Command Palette
Search for a command to run...
유니코른: 자가 생성된 감독을 통한 자기 개선형 통합 다중모달 모델 지향
유니코른: 자가 생성된 감독을 통한 자기 개선형 통합 다중모달 모델 지향
초록
통합 다중모달 모델(UMMs)은 다중모달 이해 측면에서 놀라운 성과를 거두었으나, 내부 지식을 고품질 생성에 효과적으로 활용하는 데에는 여전히 큰 격차가 존재한다. 본 연구에서는 이러한 불일치를 '전도성 실어증(Conduction Aphasia)'으로 정의한다. 이는 모델이 다중모달 입력을 정확히 해석하지만, 그 이해를 충실하고 제어 가능한 생성으로 전환하는 데 어려움을 겪는 현상이다. 이를 해결하기 위해, 외부 데이터나 교사 감독 없이도 작동할 수 있는 간단하면서도 우아한 자기개선 프레임워크인 UniCorn을 제안한다. UniCorn은 단일 UMM을 세 가지 협업 역할—제안자(Proposer), 해결자(Solver), 심사자(Judge)—로 분할함으로써, 자기 대결(self-play)을 통해 고품질의 상호작용을 생성하고, 인지적 패턴 재구성 기법을 활용하여 잠재된 이해를 명시적인 생성 신호로 정제한다. 다중모달 일관성 복원을 검증하기 위해, 텍스트 → 이미지 → 텍스트로의 재구성 루프를 기반으로 한 사이클 일관성 기준인 UniCycle을 도입한다. 광범위한 실험을 통해 UniCorn이 6개의 일반적인 이미지 생성 벤치마크에서 기준 모델 대비 종합적이고 현저한 성능 향상을 달성함을 입증하였다. 특히 TIIF(73.8), DPG(86.8), CompBench(88.5), UniCycle에서 최고 성능(SOTA)을 기록하였으며, WISE에서는 +5.0, OneIG에서는 +6.5의 상당한 향상도 달성하였다. 이러한 결과는 본 연구 방법이 텍스트에서 이미지로의 생성 성능을 크게 향상시키면서도 강력한 이해 능력을 유지함을 보여주며, 통합 다중모달 지능에 대한 완전 자율적 정제 기법의 확장 가능성을 입증한다.
One-sentence Summary
The authors from USTC, FDU, ECNU, CUHK, NJU, and SUDA propose UniCorn, a self-supervised framework that enhances unified multimodal models by decomposing them into Proposer, Solver, and Judge roles to enable self-play and cognitive pattern reconstruction, significantly improving text-to-image generation quality and coherence without external data, achieving SOTA results on multiple benchmarks including TIIF, DPG, and UniCycle.
Key Contributions
-
The paper identifies "Conduction Aphasia" in Unified Multimodal Models (UMMs), where strong cross-modal comprehension fails to translate into high-quality generation, and proposes UniCorn, a self-improvement framework that repurposes a single UMM’s internal capabilities into three collaborative roles—Proposer, Solver, and Judge—enabling self-supervised refinement without external data or teacher models.
-
UniCorn employs cognitive pattern reconstruction to convert multi-agent interactions into structured training signals, such as descriptive captions and evaluative feedback, thereby distilling latent understanding into explicit generative guidance and enabling autonomous, scalable improvement within a unified model architecture.
-
Extensive experiments show UniCorn achieves state-of-the-art performance on six image generation benchmarks, including TIIF (73.8), DPG (86.8), CompBench (88.5), and UniCycle (46.5), with significant gains of +5.0 on WISE and +6.5 on OneIG, while UniCycle, a novel cycle-consistency evaluation, validates enhanced multimodal coherence across text-to-image-to-text reconstruction.
Introduction
Unified Multimodal Models (UMMs) aim to integrate perception and generation within a single framework, enabling coherent reasoning across modalities—a key step toward Artificial General Intelligence. However, a critical limitation persists: strong comprehension often fails to translate into high-quality generation, a phenomenon the authors term "Conduction Aphasia," where models understand content but cannot reliably produce it. Prior self-improvement methods rely on external supervision, curated data, or task-specific reward engineering, limiting scalability and generalization. The authors introduce UniCorn, a post-training framework that enables fully self-contained improvement by treating a single UMM as a multi-agent system with three roles: Proposer (generates diverse prompts), Solver (produces image candidates), and Judge (evaluates outputs using internal comprehension). This self-generated feedback loop, enhanced by data reconstruction into structured signals, allows the model to refine its generation without external data or teacher models. To validate genuine multimodal coherence, they propose UniCycle, a cycle-consistency benchmark that measures conceptual alignment through text-to-image-to-text reconstruction. Experiments show UniCorn achieves state-of-the-art results across multiple benchmarks while maintaining robustness under out-of-distribution conditions, demonstrating that internal understanding can be repurposed as a powerful, self-sustaining training signal.
Method
The authors leverage a self-supervised framework, UniCorn, to bridge the comprehension-generation gap in unified multimodal models (UMMs) by enabling internal synergy through multi-agent collaboration and cognitive pattern reconstruction. The framework operates in two primary stages: Self Multi-Agent Sampling and Cognitive Pattern Reconstruction (CPR).
In the first stage, the UMM is functionally partitioned into three collaborative roles—Proposer, Solver, and Judge—within a single model, enabling a self-play loop without external supervision. The Proposer generates diverse and challenging text prompts for image generation, guided by fine-grained rules across ten predefined categories and enhanced by a dynamic seeding mechanism that iteratively refines prompt generation using previously sampled examples. The Solver then produces a set of images in response to these prompts, utilizing multiple rollouts per prompt to ensure diversity and quality. The Judge evaluates the generated images by assigning discrete scores from 0 to 10, leveraging task-specific rubrics and Chain-of-Thought reasoning to provide evaluative signals. This process, illustrated in the framework diagram, establishes a closed-loop system where the model generates, evaluates, and refines its own outputs.

In the second stage, Cognitive Pattern Reconstruction (CPR), the raw interactions from the self-play cycle are restructured into three distinct training patterns to distill latent knowledge into explicit supervisory signals. The first pattern, Caption, establishes bidirectional semantic grounding by training the model to predict the original prompt given the highest-scoring generated image, thereby reinforcing the inverse mapping from image to text. The second pattern, Judgement, calibrates the model's internal value system by training it to predict the evaluative score for any prompt-image pair, using the reasoning traces and rubrics from the Judge. The third pattern, Reflection, introduces iterative self-correction by training the model to transform a suboptimal image into an optimal one, using the contrast between high- and low-reward outputs from the same prompt. This process, detailed in the cognitive pattern reconstruction diagram, transforms the model's internal "inner monologue" into structured data that facilitates robust learning.

These three reconstructed data types—caption, judgement, and reflection—are combined with high-quality self-sampled generation data to fine-tune the UMM. The entire process is fully self-contained, requiring no external teacher models or human annotations. The framework's effectiveness is further validated through the UniCycle benchmark, which evaluates the model's ability to reconstruct textual information from its own generated content, as illustrated in the benchmark diagram.

Experiment
- UniCycle benchmark validates internal multimodal intelligence by measuring semantic preservation in a Text → Image → Text loop, achieving a Hard score of 46.5, outperforming base models by nearly 10 points and demonstrating superior self-reflection and unified understanding.
- On TIIF, UniCorn achieves a 3.7-point gain on short prompts and a 22.4-point improvement on the Text subtask of OneIG-EN, indicating strong instruction following and knowledge internalization.
- On WISE, UniCorn improves by 5 points, and on CompBench by 6.3 points, with notable gains in Numeracy (+13.1) and 3D Spatial (+6.1), surpassing GPT-4o on DPG (86.8 vs 86.2).
- Ablation studies confirm that Cognitive Pattern Reconstruction (CJR) stabilizes latent space and enables reciprocal reinforcement between understanding and generation, with removal of generation or judgment leading to performance collapse.
- Scaling experiments show that UniCorn achieves SOTA performance with only 5k self-generated samples, outperforming IRG (trained on 30k GPT-4o data) and DALL·E 3, demonstrating efficient, unbounded self-improvement.
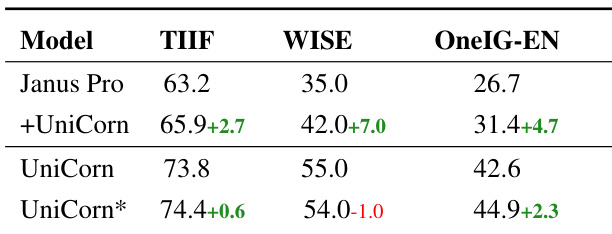
- UniCorn generalizes across architectures, improving Janus-Pro by +3.2 on TIIF and +7.0 on WISE, confirming its effectiveness in enhancing knowledge expression and understanding-guided generation.
The authors use the UniCycle benchmark to evaluate the ability of unified multimodal models to preserve instruction-critical semantics through a Text → Image → Text loop. Results show that UniCorn achieves the highest Hard score (46.5) on UniCycle, outperforming its base model BAGEL by nearly 10 points and other models by over 3 points, demonstrating superior self-reflection and comprehensive multimodal intelligence.
The authors use the UniCycle benchmark to evaluate the ability of unified multimodal models to preserve instruction-critical semantics through a Text → Image → Text loop. Results show that UniCorn achieves the highest Hard score (46.5) on UniCycle, significantly outperforming its base model BAGEL and other unified models, indicating superior internalization of knowledge and self-reflection capabilities.
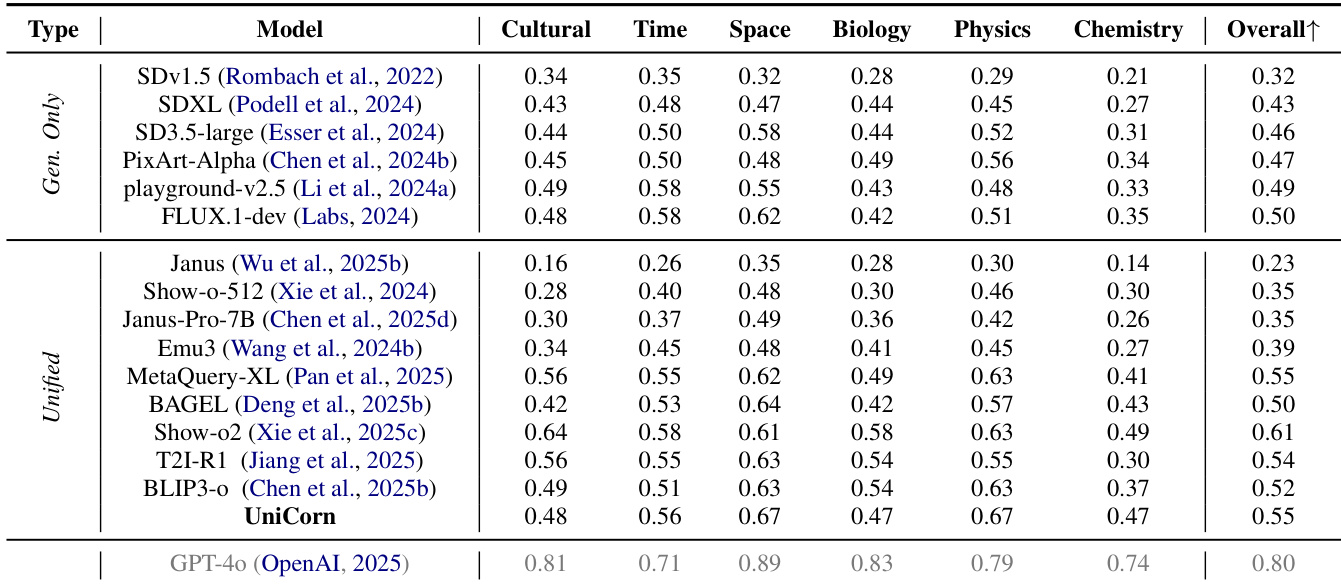
The authors use the UniCycle benchmark to evaluate the ability of multimodal models to preserve instruction-critical semantics through a Text → Image → Text loop. Results show that UniCorn achieves the highest Hard score of 46.5 on UniCycle, significantly outperforming its base model BAGEL and other unified models, indicating superior internalization of knowledge and self-reflection capabilities.
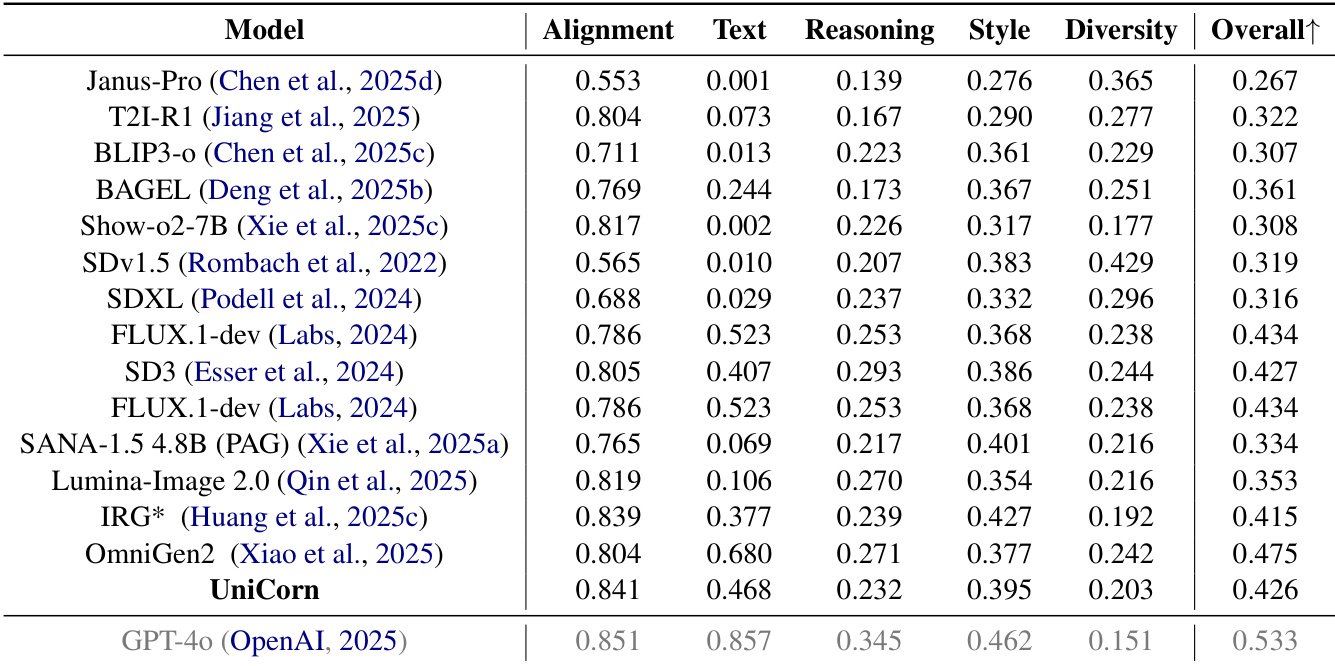
The authors use a table to compare UniCorn with other models on criteria including external model and data dependency, as well as hyperparameter tuning. Results show that UniCorn achieves state-of-the-art performance on OneIG-EN using only 5K training samples without relying on external task-specific models or annotated data, while also requiring no hyperparameter tuning.

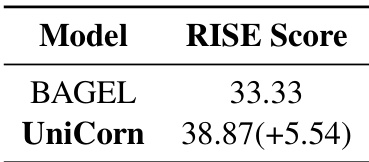
The authors use the RISE benchmark to evaluate the performance of UniCorn and its base model BAGEL. Results show that UniCorn achieves a RISE score of 38.87, which is 5.54 points higher than BAGEL's score of 33.33, indicating significant improvement in instruction-following and generation quality.