Command Palette
Search for a command to run...
MemRL: 에피소드 메모리 위에서 런타임 강화 학습을 통한 자가진화 에이전트
MemRL: 에피소드 메모리 위에서 런타임 강화 학습을 통한 자가진화 에이전트
초록
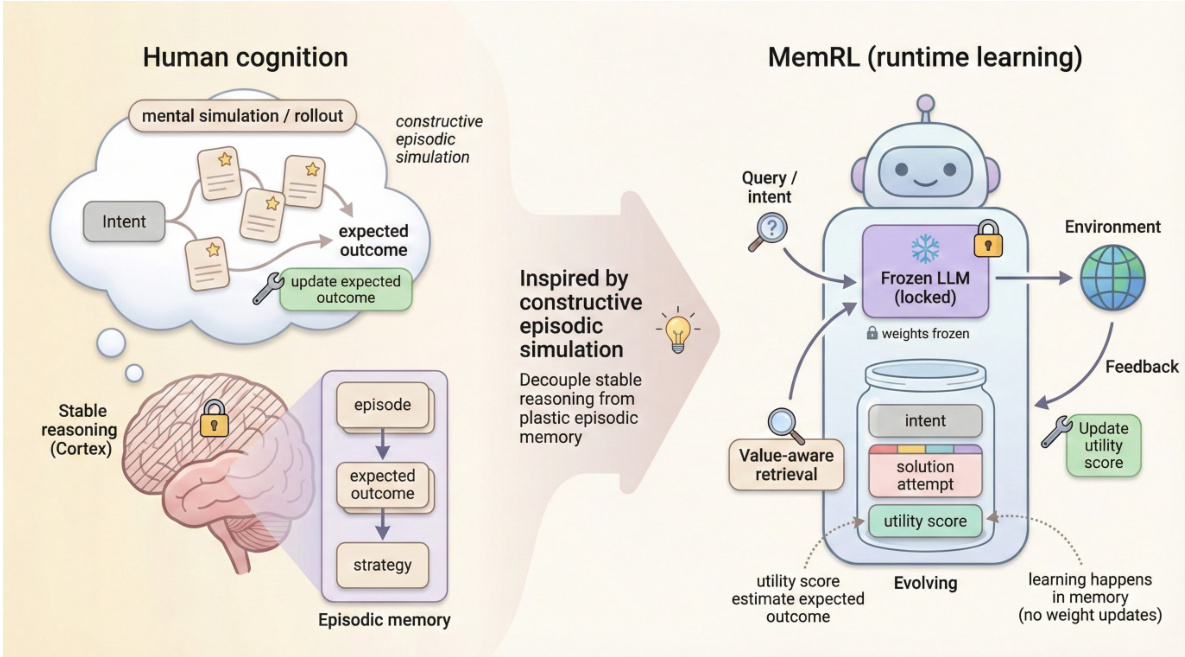
인간 지능의 핵심 특징은 새로운 과제에 대한 해결책을 창조적으로 구성하기 위해 과거 경험을 회상하고 통합하는 '건설적 에피소딕 시뮬레이션'(Constructive Episodic Simulation) 능력이다. 대규모 언어 모델(Large Language Models, LLM)은 강력한 추론 능력을 지니고 있지만, 이러한 자기 진화 과정을 모방하는 데 어려움을 겪는다. 파인튜닝은 계산 비용이 높고 치명적인 망각(catastrophic forgetting)에 취약한 반면, 기존의 메모리 기반 방법들은 주로 수동적인 의미 매칭에 의존하여 노이즈를 자주 회수하는 문제가 있다. 이러한 문제를 해결하기 위해 우리는 에피소딕 메모리 위에서 비파라미터적 강화학습을 통해 에이전트가 자기 진화할 수 있도록 하는 MemRL 프레임워크를 제안한다. MemRL은 고정된 LLM의 안정적인 추론과 진화하는 메모리의 유연성 사이를 명시적으로 분리한다. 기존의 방법과 달리, MemRL은 두 단계 검색(Two-Phase Retrieval) 메커니즘을 도입하여, 먼저 의미적 관련성에 따라 후보를 필터링한 후, 학습된 Q-값(유용성)에 기반해 이를 선택한다. 이러한 유용성은 환경 피드백을 통해 시도 오류 방식으로 지속적으로 개선되며, 이로 인해 에이전트는 유사한 노이즈와 구별하여 고가치 전략을 식별할 수 있다. HLE, BigCodeBench, ALFWorld, Lifelong Agent Bench에서 수행한 광범위한 실험 결과, MemRL이 최첨단 기준 모델들을 상당히 능가함을 확인하였다. 분석 실험을 통해 MemRL이 안정성과 유연성 사이의 갈등을 효과적으로 해소함을 입증하였으며, 가중치 갱신 없이도 런타임 중 지속적인 성능 향상을 가능하게 한다.
One-sentence Summary
The authors from Shanghai Jiao Tong University, Xidian University, National University of Singapore, Shanghai Innovation Institute, MemTensor (Shanghai) Technology Co., Ltd., and University of Science and Technology of China propose MEMRL, a non-parametric reinforcement learning framework that enables LLM agents to self-evolve through dynamic episodic memory. By decoupling a frozen LLM from a plastic memory module and employing a two-phase retrieval mechanism—first by semantic relevance and then by learned Q-values—MEMRL selectively updates high-utility strategies via trial-and-error feedback, overcoming catastrophic forgetting and noise in retrieval. This approach achieves continuous runtime improvement without weight updates, significantly outperforming state-of-the-art baselines on HLE, BigCodeBench, ALFWorld, and Lifelong Agent Bench, demonstrating effective resolution of the stability-plasticity dilemma in lifelong learning scenarios.
Key Contributions
-
The paper addresses the challenge of enabling large language models to continuously learn and adapt after deployment without catastrophic forgetting, by proposing MEMRL—a framework that decouples stable reasoning (via a frozen LLM) from plastic episodic memory, thus reconciling the stability-plasticity dilemma in runtime learning.
-
MEMRL introduces a novel Two-Phase Retrieval mechanism that first filters experiences by semantic relevance and then selects them based on learned Q-values (utility), with these utilities refined through environmental feedback using a non-parametric reinforcement learning approach, allowing the agent to distinguish high-value strategies from noise.
-
Extensive experiments on HLE, BigCodeBench, ALFWorld, and Lifelong Agent Bench show MEMRL consistently outperforms state-of-the-art baselines, with analysis confirming that utility-driven updates improve task success and maintain structural integrity through Bellman contraction, ensuring stable, continuous improvement without weight updates.
Introduction
The authors address the challenge of enabling large language models to continuously improve their performance after deployment without modifying their frozen parameters—a critical need for real-world agent applications where stability and adaptability must coexist. Prior approaches either rely on computationally expensive fine-tuning, which risks catastrophic forgetting, or passive retrieval methods like RAG that lack a mechanism to evaluate the actual utility of past experiences, making them ineffective at distinguishing high-value strategies from noise. To overcome these limitations, the authors propose MEMRL, a framework that decouples stable reasoning (handled by a frozen LLM) from plastic episodic memory, using non-parametric reinforcement learning to optimize memory usage. MEMRL introduces a Two-Phase Retrieval mechanism that first filters candidates by semantic relevance and then selects them based on learned Q-values, which are updated via environmental feedback using Bellman updates. This closed-loop process enables the agent to self-evolve at runtime, continuously refining its memory to prioritize high-utility experiences. The framework is validated across multiple benchmarks, demonstrating consistent performance gains and theoretical stability through convergence guarantees, establishing a new paradigm for runtime learning in LLM agents.
Method
The authors leverage a non-parametric reinforcement learning framework, MemRL, to enable a frozen large language model (LLM) to self-evolve through interaction with an environment. The core of the approach is to treat memory retrieval as a value-based decision-making process within a Memory-Based Markov Decision Process (M-MDP) formulation. The agent's behavior is decomposed into two distinct phases: Retrieve and Generation. The joint policy for generating a response yt is defined as a marginal over all possible retrieved memory items, combining a retrieval policy μ(m∣st,Mt) that selects a memory context m and an inference policy pLLM(yt∣st,m) that generates the output conditioned on the query and the retrieved context. The key innovation lies in optimizing the retrieval policy μ directly, rather than relying on static similarity metrics, to select memories based on their functional utility.
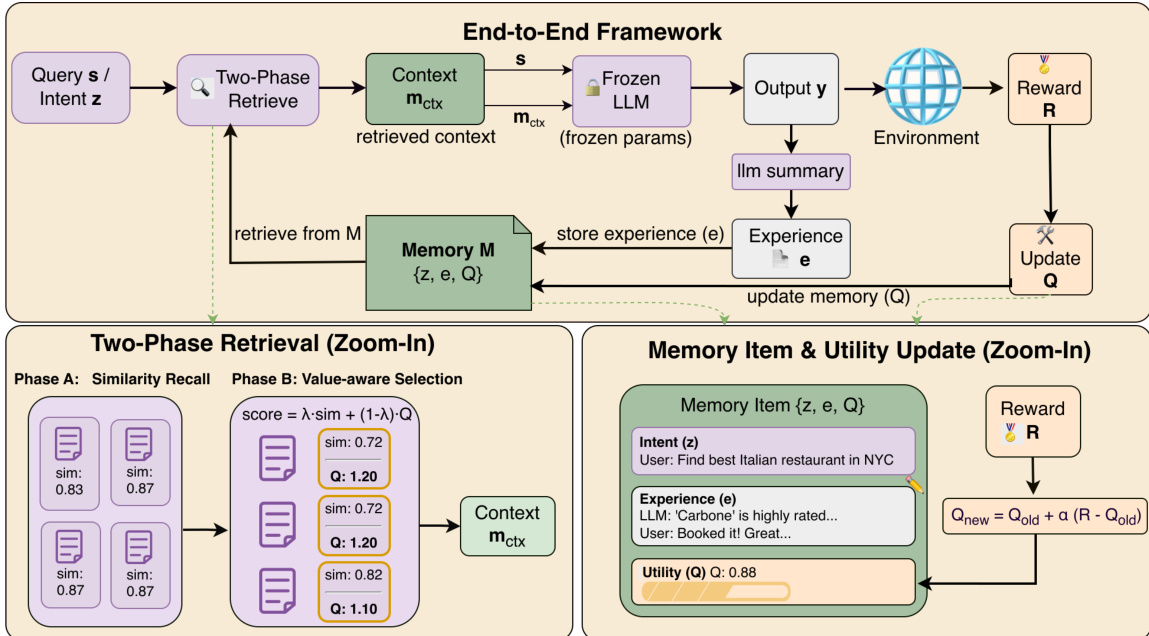
The framework's architecture is built around a structured memory bank M, which is organized as a set of Intent-Experience-Utility triplets (zi,ei,Qi). Here, zi is the intent embedding of a past query, ei is the raw experience (e.g., a successful solution trace), and Qi is the learned utility value, which approximates the expected return of applying that experience to similar intents. This structure enables the agent to make decisions based on the proven effectiveness of past experiences, not just their semantic similarity.
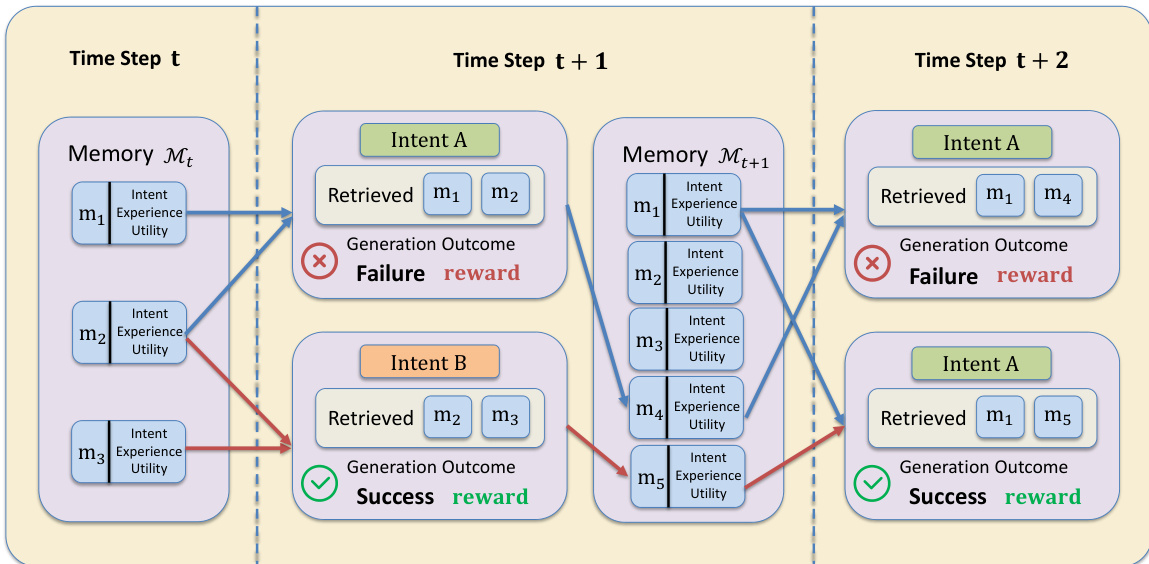
To select the most useful context, MemRL employs a Two-Phase Retrieval mechanism. Phase A, Similarity Recall, acts as a coarse filter. Given a current query intent s, it computes the cosine similarity between s and all stored intent embeddings zi and retrieves a candidate pool C(s) of the top-K most semantically similar memories. This ensures the retrieval is contextually relevant. Phase B, Value-aware Selection, refines this pool by selecting the optimal context based on learned utility. It uses a composite scoring function that balances semantic similarity and utility: score(s,zi,ei)=(1−λ)⋅sim^(s,zi)+λ⋅Q^(zi,ei), where ^ denotes z-score normalization. This allows the policy to prioritize memories with high utility, even if they are not the most semantically similar, effectively filtering out "distractor" memories.
The learning process occurs entirely within the memory space, without modifying the LLM's weights. After the agent generates an output and receives a reward R from the environment, the utility scores of the retrieved memories are updated. This is done using a Monte Carlo-style update rule: Qnew←Qold+α(R−Qold), where α is the learning rate. This update drives the utility estimate toward the empirical expected return of using that experience. Concurrently, the experience is summarized and stored as a new triplet in the memory bank, enabling continual expansion of the agent's knowledge base. This process of utility update, inspired by memory reconsolidation, allows the agent to learn from its successes and failures, continuously refining its retrieval policy.
Experiment
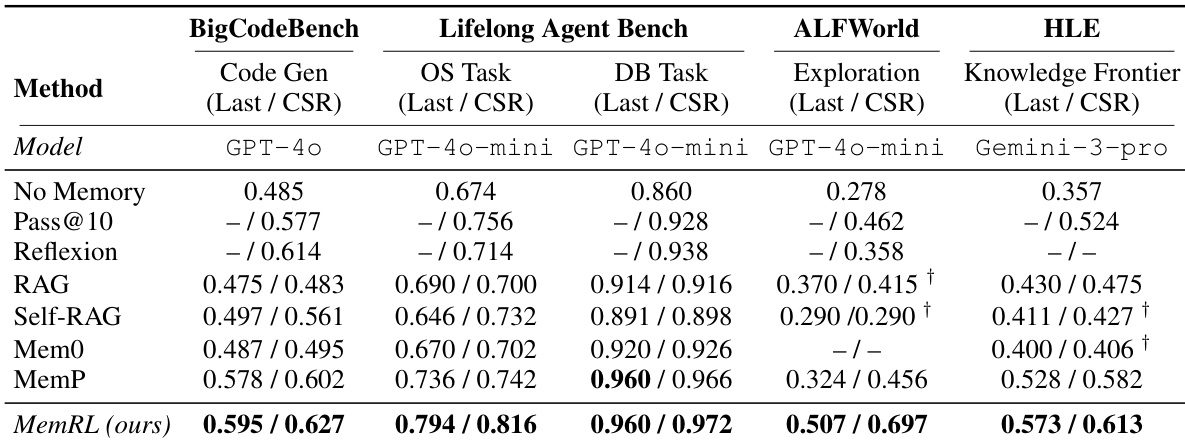
- MEMRL outperforms multiple baselines—including RAG, Self-RAG, MemP, and Reflexion—across four diverse benchmarks: BigCodeBench (code generation), ALFWorld (embodied navigation), Lifelong Agent Bench (OS/DB interaction), and Humanity's Last Exam (HLE, complex reasoning), validating its effectiveness in both runtime learning and transfer settings.
- On ALFWorld, MEMRL achieves a last-epoch accuracy of 0.507, a 56% improvement over MemP (0.324) and 82% over the no-memory baseline (0.278), with a cumulative success rate (CSR) of 0.697, demonstrating superior exploration and solution discovery in high-complexity, procedural tasks.
- In HLE, MEMRL reaches 0.573 last accuracy and 61.3% CSR, significantly outperforming MemP (0.528), highlighting its ability to learn from near-miss failures and retain reusable corrective heuristics.
- On BigCodeBench, MEMRL achieves 0.508 accuracy, surpassing Self-RAG (0.500) and MemP (0.494), while in Lifelong Agent Bench it attains 0.746 accuracy, outperforming RAG (0.713), confirming strong generalization across domains.
- Ablation studies show that the value-aware retrieval mechanism with balanced Q-weighting (λ = 0.5) yields the best performance, with pure semantic retrieval plateauing early and pure RL showing instability due to context detachment.
- Compact retrieval settings (k₁ = 5, k₂ = 3) outperform larger ones (k₁ = 10, k₂ = 5) on HLE, indicating that high-quality, low-noise memory recall is more effective than high-volume retrieval for complex reasoning.
- MEMRL acts as a trajectory verifier, significantly improving performance on multi-step tasks (e.g., +24.1 pp on ALFWorld) by filtering out memories that fail in later steps despite initial semantic match.
- The Q-critic shows strong predictive power (Pearson r = 0.861), with high-Q failure memories contributing to robustness by encoding transferable corrective heuristics, as demonstrated in case studies where high-Q failures led to 100% downstream success.
- MEMRL exhibits superior stability, with a lower forgetting rate (0.041 vs. 0.051 for MemP) and synchronized growth in CSR and epoch accuracy, attributed to theoretical guarantees from Bellman contraction and effective noise filtering via normalization and similarity gating.
- Performance gains correlate with intra-dataset similarity, with ALFWorld (similarity 0.518) showing the highest gain (Δ = +0.229) due to strong pattern reuse, while HLE (similarity 0.186) achieves high gain (Δ = +0.216) through runtime memorization of unique, domain-specific solutions, showcasing MEMRL’s dual capability in generalization and specific knowledge acquisition.
Results show that MEMRL's performance gain correlates with query similarity, with higher gains observed in tasks like ALFWorld that have greater structural repetition. However, HLE, despite its low similarity, achieves a high gain through runtime memorization, indicating that MEMRL supports both pattern generalization and specific knowledge acquisition depending on task structure.
The authors use the table to compare MEMRL against MemP across four benchmarks, showing that MEMRL achieves higher accuracy in all cases. The performance gain is most pronounced in multi-step tasks like ALFWorld, where MEMRL improves accuracy by 24.1 percentage points, while the gain is smaller in single-step tasks such as BigCodeBench, indicating that MEMRL's value-aware retrieval is particularly effective in complex, sequential environments.
The authors use MEMRL to evaluate its performance against various memory-augmented baselines across four benchmarks, including code generation, OS interaction, and embodied navigation. Results show that MEMRL achieves the highest accuracy on all tasks, with significant improvements over baselines such as RAG and MemP, particularly in complex exploration-heavy environments like ALFWorld.
The authors use MEMRL to evaluate its performance against various memory-augmented baselines across four benchmarks, including code generation, embodied navigation, OS/DB interaction, and complex reasoning. Results show that MEMRL consistently outperforms all baselines in both runtime learning and transfer settings, achieving the highest accuracy and cumulative success rate on all tasks, with particularly strong gains in exploration-heavy environments like ALFWorld and HLE.