Command Palette
Search for a command to run...
드림스타일: 비디오 스타일라이제이션을 위한 통합 프레임워크
드림스타일: 비디오 스타일라이제이션을 위한 통합 프레임워크
Mengtian Li Jinshu Chen Songtao Zhao Wanquan Feng Pengqi Tu Qian He
초록
비디오 스타일라이제이션은 비디오 생성 모델의 중요한 후행 작업이지만, 아직 충분히 탐구되지 않은 분야이다. 기존의 스타일 조건 입력 방식은 일반적으로 텍스트, 스타일 이미지, 그리고 스타일링된 첫 번째 프레임을 포함한다. 각 조건은 고유한 장점을 지닌다. 텍스트는 더 높은 유연성을 제공하며, 스타일 이미지는 더 정확한 시각적 기준을 제공하고, 스타일링된 첫 번째 프레임은 장시간 비디오의 스타일라이제이션을 가능하게 한다. 그러나 기존의 방법들은 대부분 단일 유형의 스타일 조건에 국한되어 있어 적용 범위가 제한된다. 게다가 고품질 데이터셋의 부족으로 인해 스타일 일관성 저하와 시간적 플리커(flicker) 문제가 발생한다. 이러한 한계를 해결하기 위해, 본 연구는 텍스트 기반, 스타일 이미지 기반, 첫 번째 프레임 기반의 비디오 스타일라이제이션을 모두 지원하는 통합적 프레임워크인 DreamStyle을 제안한다. 또한, 고품질 쌍체 비디오 데이터를 확보하기 위한 체계적인 데이터 정제 파이프라인을 함께 개발하였다. DreamStyle은 기본적인 이미지-비디오(Image-to-Video, I2V) 모델을 기반으로 하며, 조건 토큰 간의 혼동을 줄이기 위해 토큰별 업 매트릭스를 사용한 저랭크 적응(Low-Rank Adaptation, LoRA) 기법을 적용하여 훈련한다. 정성적 및 정량적 평가 결과를 통해 DreamStyle이 세 가지 비디오 스타일라이제이션 작업 모두에서 우수한 성능을 발휘하며, 경쟁 기법들에 비해 스타일 일관성과 비디오 품질 측면에서 뛰어난 성능을 보임을 입증하였다.
One-sentence Summary
The authors from ByteDance's Intelligent Creation Lab propose DreamStyle, a unified video stylization framework supporting text-, style-image-, and first-frame-guided generation via a LoRA-enhanced I2V model with token-specific up matrices, enabling consistent, high-quality stylization across diverse conditions and overcoming prior limitations in flexibility and temporal coherence.
Key Contributions
- Video stylization has been limited by reliance on single-style conditions (text, style image, or first frame), restricting flexibility and generalization; DreamStyle introduces a unified framework that seamlessly supports all three modalities within a single model, enabling versatile and controllable stylization.
- To overcome the lack of high-quality training data, DreamStyle employs a systematic data curation pipeline that generates paired stylized videos by first stylizing the initial frame and then propagating the style through an I2V model with ControlNets, combined with hybrid automatic and manual filtering for high fidelity.
- The framework leverages a modified LoRA with token-specific up matrices to reduce interference between different condition tokens, achieving superior style consistency and video quality compared to specialized baselines, while enabling advanced applications like multi-style fusion and long-video stylization.
Introduction
Video stylization is a key task in visual content generation, enabling the transformation of real-world videos into artistic or stylistic outputs while preserving motion and structure. Prior methods are largely limited to single-style conditions—either text prompts or style images—each with trade-offs in flexibility, accuracy, and usability. Moreover, the absence of high-quality, modality-aligned training data leads to poor style consistency and temporal flickering. Existing approaches also struggle with extended applications like multi-style fusion and long-video stylization due to rigid architectures and lack of unified frameworks.
The authors introduce DreamStyle, a unified video stylization framework built on a vanilla Image-to-Video (I2V) model that supports three style conditions—text, style image, and stylized first frame—within a single architecture. To enable effective multi-condition handling, they design a token-specific LoRA module with shared down and condition-specific up matrices, reducing interference between different style tokens. A key innovation is a scalable data curation pipeline that generates high-quality paired video data by first stylizing the initial frame using image stylization models and then propagating the style through an I2V model with ControlNets, followed by hybrid (automatic and manual) filtering. This pipeline addresses the scarcity of training data and improves both style fidelity and temporal coherence.
DreamStyle achieves state-of-the-art performance across all three stylization tasks, outperforming specialized models in style consistency and video quality, while enabling new capabilities such as multi-style fusion and long-video stylization through unified condition injection.
Dataset

- The dataset consists of 40K stylized-raw video pairs for Continual Training (CT) and 5K pairs for Supervised Fine-Tuning (SFT), each with a resolution of 480P and up to 81 frames.
- The raw videos are sourced from existing video collections, and stylized videos are generated in two stages: first, the initial frame is stylized using either InstantStyle (style-image-guided) or Seedream 4.0 (text-guided); second, an in-house I2V model generates the full video from the stylized first frame.
- For CT, the dataset uses InstantStyle to produce a large-scale, diverse set focused on general video stylization capability, with one style reference image per sample. For SFT, Seedream 4.0 generates a smaller, higher-quality set with 1 to 16 style reference images per sample, where only one is used during training.
- To ensure motion consistency between raw and stylized videos, the same control conditions—depth and human pose—are applied to drive both video generations, avoiding motion mismatches caused by imperfect control signal extraction.
- Metadata is constructed using a Visual-Language Model (VLM) to generate two text prompts per video: one excluding style attributes (t_ns) and one including them (t_sty), enabling style-irrelevant and style-aware conditioning.
- Style reference images (s_i^1..K) are generated using the same guidance as the stylized video, with the CT dataset filtered for style consistency using VLM and CSD scores, while the SFT dataset undergoes manual filtering and content consistency verification.
- During training, the three style conditions—text-guided, style-image-guided, and first-frame-guided—are sampled in a 1:2:1 ratio, and the model is trained with LoRA (rank 64) using AdamW optimizer, a learning rate of 4×10⁻⁵, and a total of 6,000 (CT) and 3,000 (SFT) iterations.
- A 2-step gradient accumulation strategy is used to achieve an effective batch size of 16, with training conducted on NVIDIA GPUs and a per-GPU batch size of 1.
Method
The authors leverage the Wan14B-I2V [48] base model as the foundation for the DreamStyle framework, which is designed to support three distinct style conditions: text, style image, and first frame. The framework's architecture is built upon the base model's structure, with modifications to the input conditioning mechanism to enable the injection of raw video and additional style guidance. As shown in the figure below, the model processes multiple input modalities, including the raw video, a stylized first frame, a style reference image, and a text prompt. These inputs are encoded into latent representations using a VAE encoder, with the raw video and stylized first frame being processed into video latents, and the style image being encoded into a style latent. The text prompt is processed by a text encoder, and the style image's high-level semantics are further enhanced by a CLIP image feature branch. 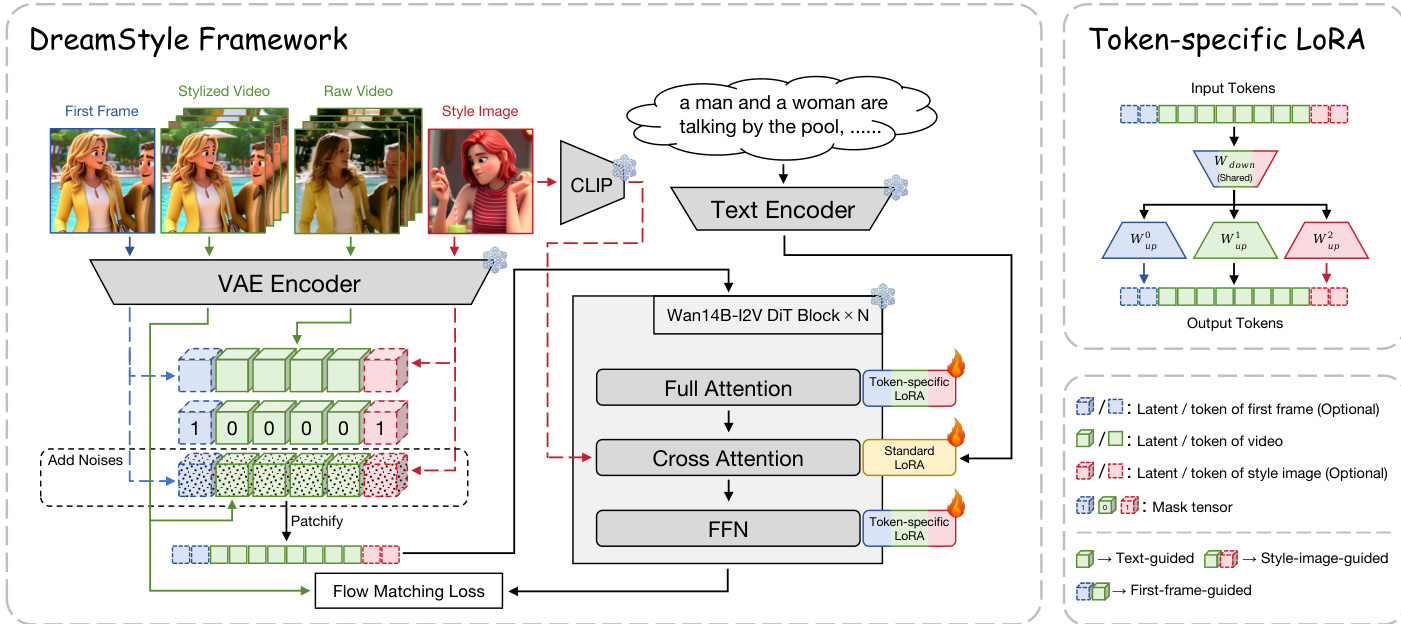
The input latents are then prepared for the model by incorporating noise and mask tensors. For the raw video condition, the encoded raw video latent zraw and the stylized video latent zsty are concatenated with a mask tensor 04×F×H×W, where the mask value of 0.0 is used to indicate the absence of a condition. For the style-image condition, the VAE-encoded style reference image latent zs is combined with a noise-injected version of itself and a mask tensor 14×1×H×W, which is filled with 1.0 to signify the presence of the style condition. The first-frame condition is similarly handled by feeding the stylized first frame into the image condition channels with a mask of 1.0. These conditioned latents are then transformed into token sequences after patchification, which are fed into the core model.
To address the challenge of inter-token confusion arising from the distinct semantic roles of the different condition tokens, the authors introduce a token-specific LoRA module. This modification is applied to the full attention and feedforward (FFN) layers of the model. As illustrated in the figure below, for an input token xin, a shared down matrix Wdowni projects the token, and the output residual token xout is computed using a specific up matrix Wupi that is selected based on the token type i. This design allows the model to learn adaptive features for each condition type while maintaining training stability through the large proportion of shared parameters. 
Experiment
- Text-guided video stylization: DreamStyle outperforms commercial models (Luma, Pixverse, Runway) and open-source baseline StyleMaster, achieving the highest CLIP-T and DINO scores, indicating superior style prompt following and structure preservation. On the test set, it surpasses competitors in style consistency (CSD) and dynamic degree, with overall quality scores of approximately 4 or higher in user study.
- Style-image-guided stylization: DreamStyle achieves the best CSD score and excels in handling complex styles involving geometric shapes, outperforming StyleMaster in both quantitative metrics and visual quality.
- First-frame-guided stylization: DreamStyle achieves optimal style consistency (CSD) and strong video quality, though slightly lower DINO scores due to occasional structural conflicts from stylized first frames; visual results confirm preservation of primary structural elements.
- Multi-style fusion: DreamStyle successfully integrates text prompts and style images during inference, enabling creative style fusion beyond single guidance.
- Long-video stylization: By chaining short video segments using the last frame as the next segment’s first frame, DreamStyle extends beyond the 5-second limit, enabling stylization of longer sequences with consistent style.
- Ablation studies: Token-specific LoRA significantly improves style consistency and reduces style degradation and confusion; training on both CT and SFT datasets in two stages achieves the best balance between style consistency and structure preservation.
Results show that DreamStyle outperforms all compared methods in text-guided video stylization, achieving the highest CLIP-T and DINO scores, indicating superior style prompt following and structure preservation. In style-image-guided and first-frame-guided tasks, DreamStyle achieves the best or second-best performance across most metrics, particularly excelling in style consistency while maintaining strong overall quality.
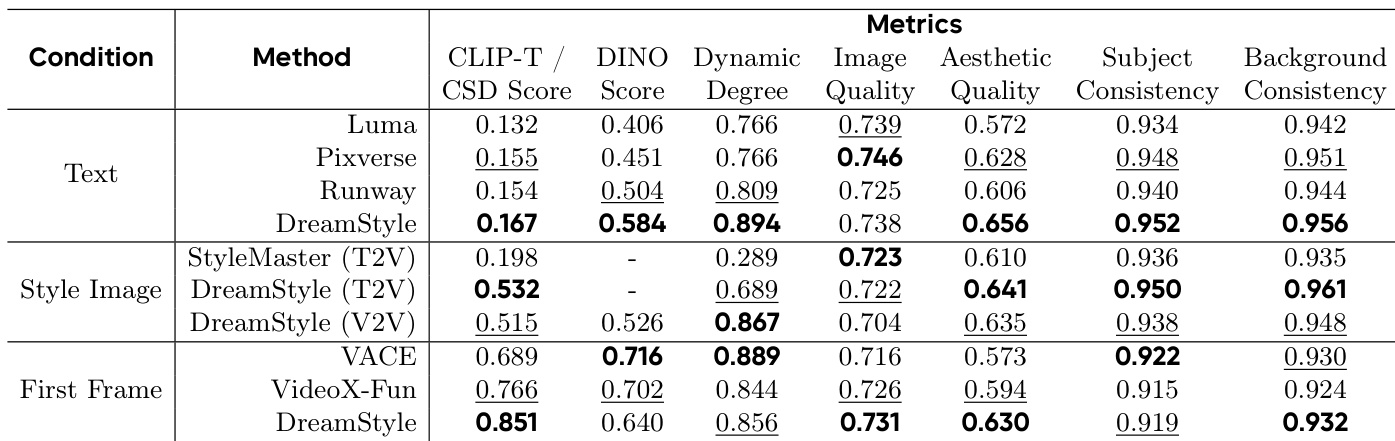
Results show that DreamStyle achieves the highest scores in style consistency, content consistency, and overall quality across all three video stylization tasks. In text-guided stylization, it outperforms Luma, Pixverse, and Runway, particularly in style consistency and content preservation. For style-image-guided and first-frame-guided tasks, DreamStyle also leads in style consistency and overall quality, demonstrating superior performance compared to StyleMaster, VACE, and VideoX-Fun.
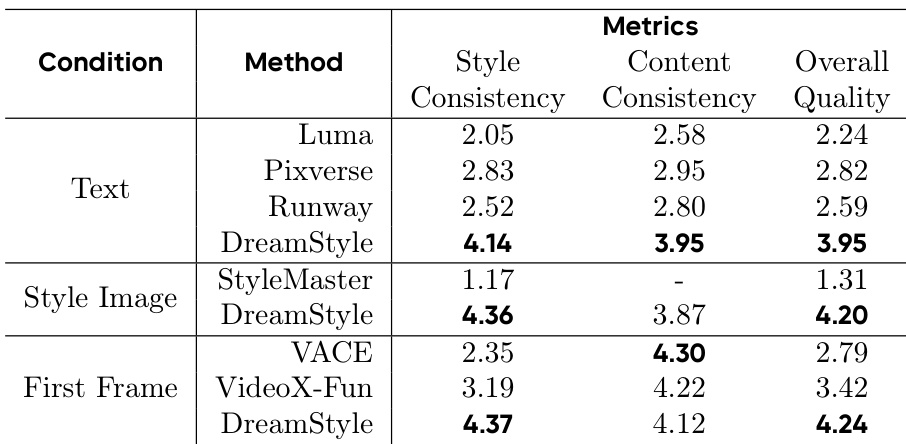
Results show that the token-specific LoRA significantly improves style consistency, with the full model achieving a CSD score of 0.515, outperforming the version without it (0.413). The full model also maintains strong structure preservation, scoring 0.526 on the DINO metric, while the ablation with only CT data achieves the highest CSD score but at the cost of structure preservation.