Command Palette
Search for a command to run...
엔트로피 적응형 피인식 학습: 확신된 모순을 해결하여 망각을 완화하기 위해
엔트로피 적응형 피인식 학습: 확신된 모순을 해결하여 망각을 완화하기 위해
Muxi Diao Lele Yang Wuxuan Gong Yutong Zhang Zhonghao Yan Yufei Han Kongming Liang Weiran Xu Zhanyu Ma
초록
감독형 미세조정(Supervised Fine-Tuning, SFT)은 도메인 적응의 표준적 접근 방식이지만, 종종 치명적인 잊혀짐(catastrophic forgetting)이라는 비용을 수반한다. 반면, 온폴리시(On-policy) 강화학습(Reinforcement Learning, RL)은 일반적 능력을 효과적으로 보존한다. 본 연구에서는 이러한 차이를 탐구하며, 근본적인 분포 간 격차(distributional gap)를 규명한다. 즉, RL은 모델의 내부 믿음(internal belief)과 일치하는 반면, SFT는 모델이 외부 지도 정보에 맞추도록 강제한다. 이러한 불일치는 낮은 확률이지만 낮은 엔트로피를 가지는 특성의 '자신감 있는 갈등(Confident Conflicts)' 토큰으로 나타나며, 이 경우 모델은 자신의 예측에 매우 자신감을 갖지만, 이를 왜곡된 참값으로 학습하도록 강제받아 파괴적인 기울기 업데이트를 유발한다. 이를 해결하기 위해 우리는 엔트로피 적응형 미세조정(Entropy-Adaptive Fine-Tuning, EAFT)을 제안한다. 기존의 예측 확률에만 의존하는 기법들과 달리, EAFT는 토큰 수준의 엔트로피를 게이팅 메커니즘으로 활용하여 지식의 불확실성(epistemic uncertainty)과 지식 갈등(knowledge conflict)을 구분한다. 이를 통해 모델은 불확실한 샘플로부터 학습할 수 있고, 갈등이 있는 데이터에 대한 기울기를 억제할 수 있다. Qwen 및 GLM 시리즈(4B에서 32B 파라미터 규모)를 대상으로 수학, 의료, 에이전트 기반 도메인에서 실시한 광범위한 실험을 통해 본 가설을 검증하였으며, EAFT는 표준 SFT와 동일한 하류 성능을 유지하면서도 일반적 능력의 저하를 크게 완화함을 확인하였다.
One-sentence Summary
The authors from Beijing University of Posts and Telecommunications and Zhongguancun Academy propose Entropy-Adaptive Fine-Tuning (EAFT), a novel method that mitigates catastrophic forgetting in domain adaptation by using token-level entropy to gate gradient updates, distinguishing epistemic uncertainty from knowledge conflict—unlike standard SFT, which forces alignment with external supervision, EAFT preserves general capabilities while matching SFT’s downstream performance across Qwen and GLM models in mathematical, medical, and agentic tasks.
Key Contributions
- Supervised Fine-Tuning (SFT) often causes catastrophic forgetting due to a fundamental distributional gap: it forces models to fit external supervision that conflicts with their internal beliefs, leading to "Confident Conflicts" where high-confidence predictions contradict ground truth, resulting in destructive gradient updates.
- The proposed Entropy-Adaptive Fine-Tuning (EAFT) method introduces token-level entropy as a gating mechanism to distinguish between epistemic uncertainty and knowledge conflict, allowing the model to learn from uncertain tokens while suppressing gradients on conflicting ones, thus preserving general capabilities.
- Extensive experiments on Qwen and GLM models (4B to 32B parameters) across mathematical, medical, and agentic domains show EAFT matches SFT’s downstream performance while significantly reducing degradation in general abilities, offering a lightweight alternative to on-policy RL with lower computational overhead.
Introduction
The authors investigate the instability of Supervised Fine-Tuning (SFT) in large language models, which often leads to catastrophic forgetting—where domain-specific adaptation degrades general capabilities. While on-policy Reinforcement Learning (RL) preserves general knowledge by aligning updates with the model’s internal distribution, SFT forces the model to fit external supervision, creating "Confident Conflicts": low-entropy tokens where the model is highly confident but must learn a contradictory label, triggering destructive gradient updates. Prior methods attempt to mitigate this using probability or KL divergence as proxies, but these fail to distinguish between epistemic uncertainty and harmful knowledge conflicts. The authors propose Entropy-Adaptive Fine-Tuning (EAFT), a lightweight, dynamic method that uses token-level entropy as a gating mechanism to suppress gradients on conflicting samples while allowing learning from uncertain ones. EAFT matches standard SFT’s performance on target domains while significantly reducing forgetting across mathematical, medical, and agentic tasks, all with minimal computational overhead and no need for reference models or pre-filtered data.
Dataset

- The dataset is composed of three primary sources: Numina-Math (Li et al., 2024), BigMathVerified (Albalak et al., 2025), and Nemotron-CrossThink (Aker et al., 2025), all focused on mathematical reasoning.
- Responses to these prompts were synthesized using the Qwen3-235B-A22B-Instruct model (Yang et al., 2025), with the final training set consisting of 19,000 correctly answered data pairs selected through verification.
- Numina-Math contains approximately 860,000 competition-level math problems and solutions, covering a broad range of mathematical disciplines and difficulty levels.
- BigMathVerified is a high-quality, large-scale dataset emphasizing reasoning rigor and self-correction, designed for reinforcement learning in mathematical reasoning.
- Nemotron-CrossThink’s math subset provides high-quality synthetic problems with rigorous logical verification, leveraging self-correction patterns to improve precision in mathematical derivation.
- The authors use this 19k math training set for model fine-tuning, combining it with other domain-specific data (e.g., medical and agent datasets) in a mixture-based training strategy.
- For processing, the authors apply strict filtering to retain only instances where the model’s generated responses are verified as correct, ensuring high data quality.
- No explicit cropping is mentioned, but the final training set is formed via random sampling from the verified outputs.
- Metadata construction includes source attribution, problem type classification, and correctness verification, supporting reproducibility and analysis.
- The training data is used in conjunction with benchmarks across domains—mathematical (AIME24/25, GSM8K), general (MMLU, IFEval, CLUEWSC), medical (MedMCQA, PubMedQA, MedQA), and agent capabilities (BFCL v3)—to evaluate model performance.
Method
The authors investigate the mechanisms underlying catastrophic forgetting in supervised fine-tuning (SFT) and propose a novel method to mitigate it. To understand the root cause, they analyze the distributional differences between SFT and on-policy reinforcement learning (RL) data at the token level. The framework diagram illustrates this distinction: in SFT, training data often contains "Confident Conflicts," where the model assigns high confidence (low entropy) to a token but the ground truth label is highly improbable (low probability). This occurs when external supervision forces the model to override its strong priors, such as labeling a "ball" as a "truncated icosahedron" in a mathematics class setting. In contrast, on-policy RL generates sequences through self-rollout, resulting in tokens that naturally align with the model's current probability landscape, either falling into high-probability confidence zones or high-entropy exploration regions. 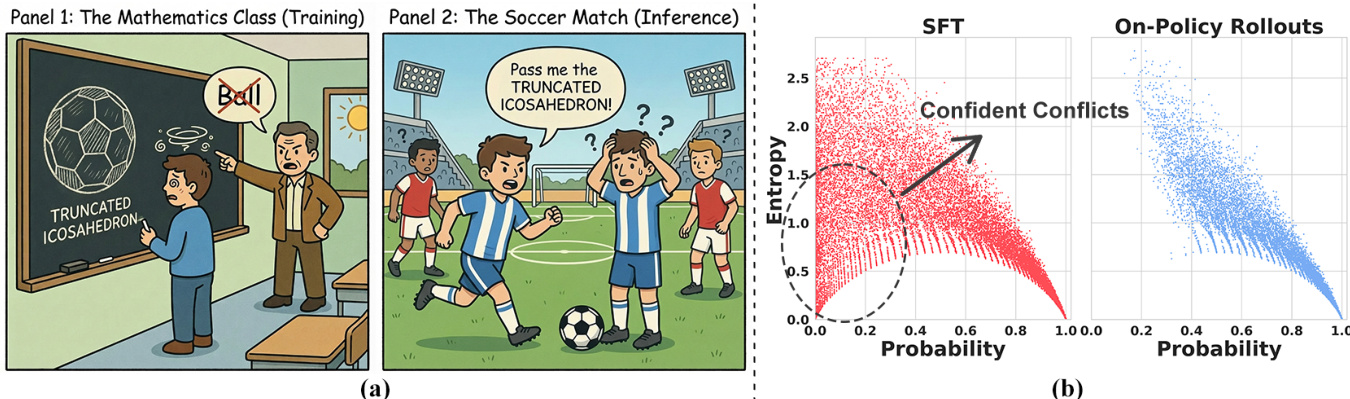
To quantify this, the authors introduce two key metrics: token-level probability, pt=Pθ(yt∣x,y<t), which measures the model's confidence in the ground-truth token, and predictive entropy, Ht=−∑v∈VPt(v)logPt(v), which measures the model's uncertainty over the vocabulary. The analysis reveals a distinct distributional gap: SFT data exhibits a prominent cluster of low-entropy, low-probability tokens, which the authors identify as the primary source of destructive gradients. This insight is validated through a pilot experiment where masking these "Confident Conflict" tokens during training significantly mitigates catastrophic forgetting.
Building on this, the authors propose Entropy-Adaptive Fine-Tuning (EAFT), a soft gating mechanism that dynamically modulates the training loss based on token-level entropy. The EAFT objective is formulated as a weighted sum, where the standard cross-entropy supervision is scaled by a normalized entropy term: LEAFT(θ)=−∑t=1TH~t⋅logPθ(yt∣x,y<t). The gating term H~t is derived from the entropy of the top-K tokens, normalized to the range [0,1] using ln(K) as the maximum entropy for K outcomes. This normalization creates a self-regulating mechanism: when the model is confident but conflicting (low entropy), the weight H~t approaches zero, effectively suppressing the destructive gradient; when the model is uncertain or exploring (high entropy), the weight remains high, allowing the standard SFT objective to learn new patterns. This approach differentiates EAFT from existing probability-based re-weighting strategies, as it leverages entropy to distinguish between rigidity and uncertainty, thereby automatically down-weighting destructive updates from conflicting data while concentrating supervision on high-entropy tokens to facilitate adaptation.
Experiment
- Main experiments validate that EAFT mitigates catastrophic forgetting while maintaining strong target task performance across diverse domains.
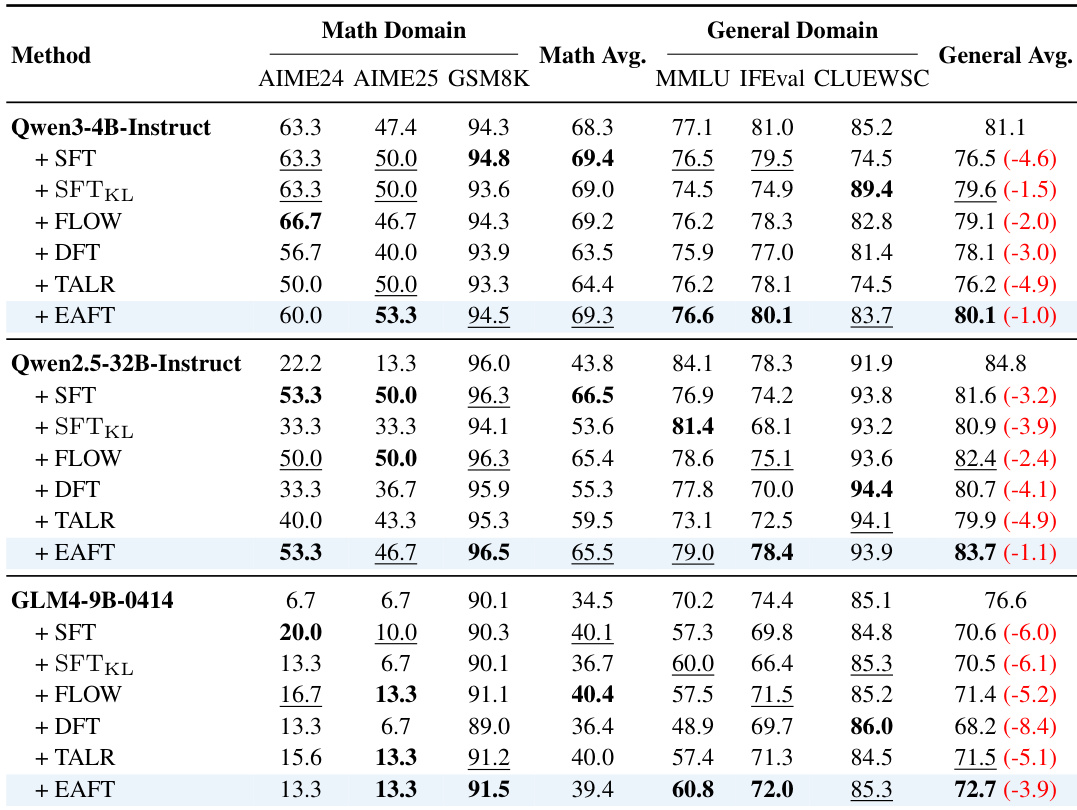
- On Math benchmarks (AIME24, AIME25, GSM8K), EAFT achieves competitive results within 1 point of the best-performing method, while preserving general capabilities with minimal degradation.
- On general benchmarks (MMLU, IFEval, CLUEWSC), EAFT significantly outperforms standard SFT, reducing average performance drops (e.g., only 1.6-point decline on CLUEWSC vs. 10.7-point drop for SFT).
- In the medical domain (MedMCQA, PubMedQA, MedQA), EAFT maintains general capability average at 84.5 (vs. 81.3 for SFT) and slightly outperforms SFT on target tasks (73.7 vs. 73.6).
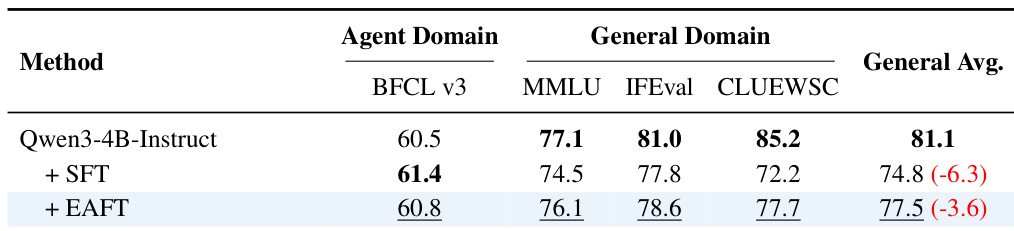
- In the agent tool-use domain (BFCL), EAFT achieves 60.8 (within 1% of SFT’s 61.4) while preserving general performance at 77.5 (vs. 74.8 for SFT).
- Gradient analysis confirms EAFT suppresses large gradients in "Confident Conflict" regions (low entropy, low probability), preventing destructive updates.
- Training dynamics show EAFT stabilizes loss on low-entropy tokens while matching SFT on high-entropy tokens, enabling effective adaptation without over-optimization.
- Ablation studies confirm entropy-aware gating is the key mechanism—soft gating (EAFT) outperforms hard masking (Masked SFT) by preserving target performance while eliminating forgetting.
- Top-K entropy approximation (K=20) achieves 0.999 correlation with exact entropy and incurs negligible computational overhead, enabling efficient implementation.
The authors use EAFT to fine-tune models on math tasks while preserving general capabilities. Results show that EAFT maintains competitive performance on target math benchmarks while significantly reducing the drop in general domain scores compared to standard SFT, with the largest improvements seen in CLUEWSC and MMLU.
The authors use EAFT to fine-tune the Qwen3-4B-Instruct model on agent tool-use tasks, showing that it maintains competitive performance on the target BFCL benchmark while significantly reducing the drop in general capabilities compared to standard SFT. Results show that EAFT preserves general performance with only a 3.6-point average decline, compared to a 6.3-point drop for SFT, demonstrating its effectiveness in mitigating catastrophic forgetting.
The authors use EAFT to fine-tune the Qwen3-4B-Thinking model on medical domain data, showing that it preserves general capabilities while improving target domain performance. Results show that EAFT maintains higher average scores on general benchmarks (84.5) compared to standard SFT (81.3), and achieves better performance on medical tasks (73.7) than SFT (73.6), indicating effective mitigation of catastrophic forgetting.

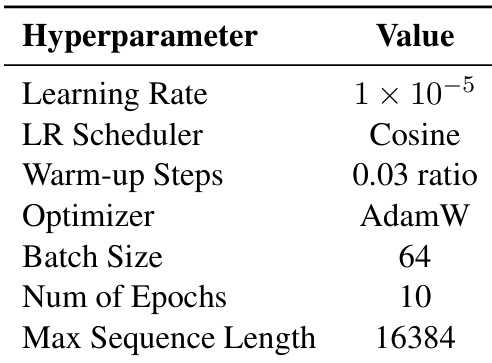
The authors use a unified set of hyperparameters across all models, including a learning rate of 1×10−5, AdamW optimizer, and 10 training epochs. These settings were applied consistently to ensure a fair comparison between EAFT and baseline methods.