Command Palette
Search for a command to run...
MOSS Transcribe Diarize: 화자 디아라이제이션을 통한 정확한 음성 인식
MOSS Transcribe Diarize: 화자 디아라이제이션을 통한 정확한 음성 인식
초록
발화자 할당 시간 태그付き 음성 전사(Speaker-Attributed, Time-Stamped Transcription, SATS)는 말한 내용을 전사하는 동시에 각 발화자의 발화 시점을 정밀하게 파악하는 것을 목표로 하며, 특히 회의 전사에 매우 유용하다. 기존의 SATS 시스템은 거의 모든 경우에서 엔드투엔드(end-to-end) 형식을 채택하지 않으며, 제한된 컨텍스트 창, 약한 장기 발화자 기억 능력, 타임스탬프 출력 불가 등의 한계를 가지고 있다. 이러한 문제를 해결하기 위해 우리는 엔드투엔드 파라다임에서 발화자 할당 및 시간 태그가 포함된 음성 전사를 동시에 수행할 수 있는 통합적 다모달 대규모 언어 모델인 MOSS Transcribe Diarize를 제안한다. 방대한 실제 환경 데이터를 기반으로 훈련되었으며, 최대 90분 분량의 입력을 처리할 수 있는 128k 컨텍스트 창을 갖추고 있어 확장성과 일반화 능력이 뛰어나다. 포괄적인 평가를 통해, 다양한 공개 및 내부 벤치마크에서 기존 최첨단 상용 시스템을 뛰어넘는 성능을 입증하였다.
One-sentence Summary
The authors propose MOSS Transcribe Diarize, a unified multimodal large language model with a 128k context window that enables end-to-end Speaker-Attributed, Time-Stamped Transcription, overcoming prior limitations in context length and timestamp output by leveraging extensive real-world data and robust long-range speaker memory, significantly outperforming state-of-the-art systems in meeting transcription scenarios.
Key Contributions
-
MOSS Transcribe Diarize introduces the first unified multimodal large language model that performs Speaker-Attributed, Time-Stamped Transcription (SATS) in a single end-to-end pass, eliminating error-prone modular pipelines by jointly modeling speech recognition, speaker attribution, and timestamp prediction without intermediate hand-offs.
-
The model leverages a 128k-token context window, enabling it to process up to 90-minute meetings in a single pass, which significantly enhances long-range speaker memory, discourse coherence, and accurate handling of cross-turn references and speaker consistency.
-
Trained on extensive real-world conversational data, MOSS Transcribe Diarize outperforms state-of-the-art commercial systems across multiple public and in-house benchmarks, demonstrating superior performance in both speaker attribution accuracy and temporal precision for long-form meeting transcription.
Introduction
Speaker-Attributed, Time-Stamped Transcription (SATS) is critical for applications like meeting assistants, call-center analytics, and legal discovery, where knowing who said what and when is as important as the content itself. Prior systems typically rely on cascaded pipelines combining separate ASR and diarization modules, leading to error propagation, poor long-range speaker consistency, limited context windows, and the inability to natively output precise timestamps. While recent efforts have introduced hybrid or semi-end-to-end approaches, they still face constraints in scalability to long-form conversations, suffer from chunking artifacts, and lack robust long-range memory. The authors present MOSS Transcribe Diarize, a unified multimodal large language model that performs SATS in a single, end-to-end pass. It leverages a 128k-token context window to process up to 90-minute meetings without chunking, enabling strong long-range speaker memory, continuous discourse modeling, and native segment-level timestamping. This approach eliminates modular mismatches, reduces identity drift, and outperforms state-of-the-art systems on both public and in-house benchmarks.
Dataset

- The dataset comprises real and simulated multilingual audio, sourced from public corpora, podcasts, films, and in-house collections, designed to cover diverse multi-speaker scenarios.
- Real data includes the AISHELL-4 Test set, featuring long-form, far-field overlapping recordings from meeting rooms; the authors use the averaged channel of far-field signals for both training and evaluation.
- Two additional test sets are curated: Podcasts from high-quality YouTube interviews with available subtitles for reference transcripts, and Movies, consisting of short, overlapping audio segments from films and TV series in Chinese, English, Korean, Japanese, and Cantonese, all manually annotated for high-quality ground truth.
- Simulated data is generated using a probabilistic simulator that constructs synthetic conversations by randomly selecting 2–12 speakers, segmenting their utterances into word runs with log-normal weights, and placing them on a timeline with Gaussian-distributed gaps to enforce alternation and allow overlaps up to 80% of the shorter segment.
- Segment boundaries are snapped to low-energy points and smoothed with 50 ms cross-fades to improve perceptual continuity.
- Mixtures are augmented with real-world noise and reverberation, with SNR sampled uniformly from 0 to 15 dB.
- The model is trained using a mixture of real and simulated data, with training splits derived from the curated real and synthetic datasets.
- For evaluation, the model is tested on three benchmarks: AISHELL-4 (real meeting audio), Podcast (multi-guest interviews), and Movies (overlapping film/TV clips), with performance measured using normalized transcripts.
- Output normalization is applied uniformly across all systems: parentheticals, angle-bracket tags, and non-speaker square-bracket annotations are removed, retaining only speaker IDs like [S1] and plain text for CER/cpCER/Δcp scoring.
- The Podcast and Movies test sets will be publicly released on Hugging Face to support future research.
Method
The authors leverage a unified architecture for Speaker-Attributed, Time-Stamped Transcription (SATS), combining a speech encoder with a learned projection into a pretrained text large language model (LLM). This framework enables end-to-end modeling of transcription, speaker attribution, and timestamp prediction within a single pass, supported by a 128k-token context window. The model processes audio input through an audio encoder, which extracts acoustic embeddings. These embeddings are then projected into the feature space of the pretrained text LLM via a trainable projection module, allowing the LLM to jointly align speaker identities with lexical content.
As shown in the figure below, the system processes audio in chunks, with temporal information explicitly represented as formatted timestamp text inserted between encoder outputs. This approach avoids reliance on absolute positional indices, which degrade over long durations, and instead enables accurate timestamp generation for hour-scale audio while maintaining stable speaker attribution. The model is trained on diverse in-the-wild conversations and property-aware simulated mixtures that capture overlap, turn-taking, and acoustic variability, enhancing robustness in real-world scenarios.
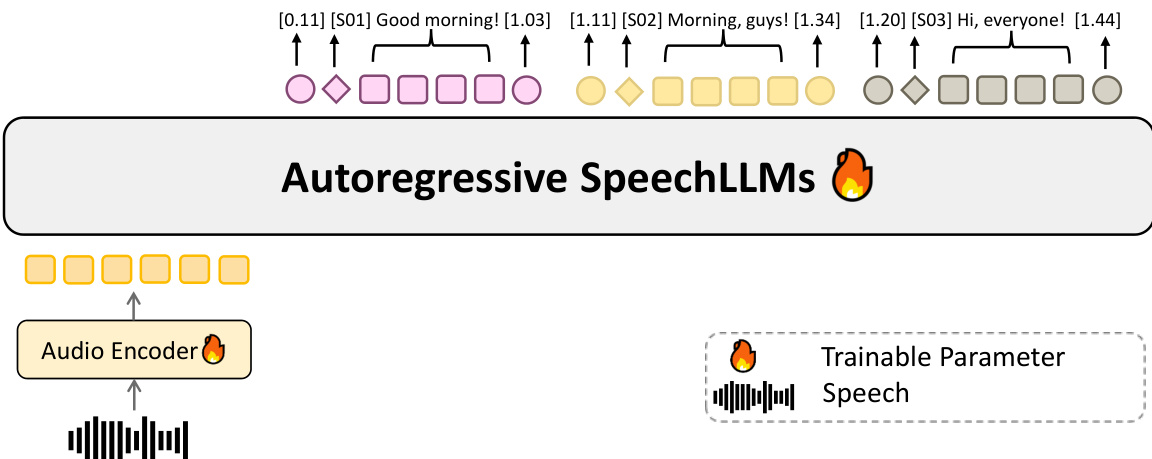
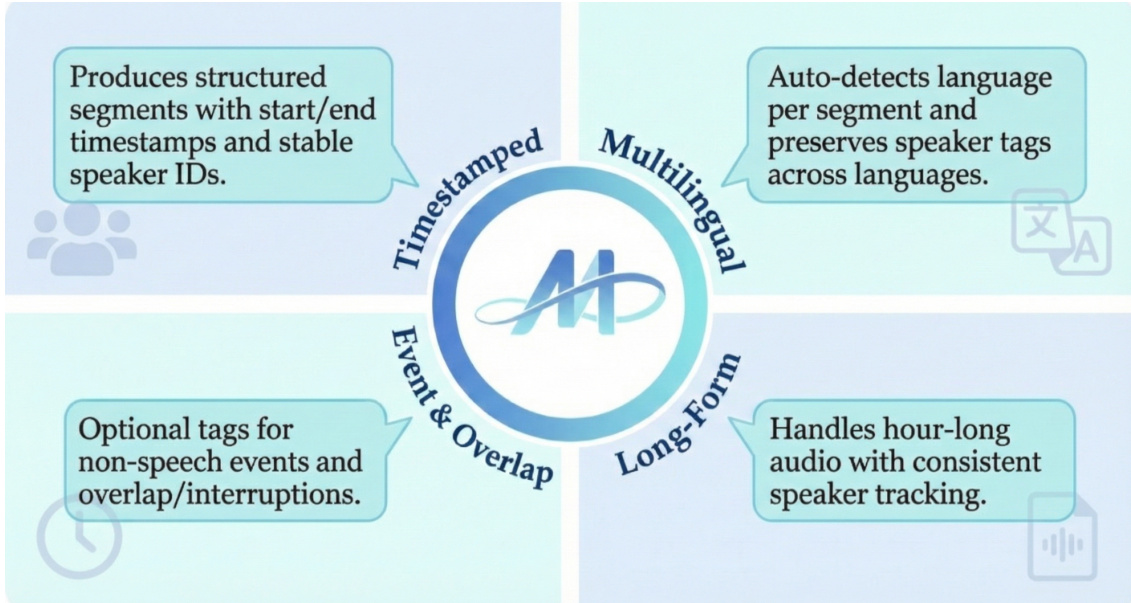
The framework produces structured segments with start/end timestamps and stable speaker IDs, as illustrated in the diagram below. It supports multilingual input, auto-detecting language per segment and preserving speaker tags across languages. The model also handles hour-long audio with consistent speaker tracking and includes optional tags for non-speech events and overlap/interruptions, enabling comprehensive event and overlap modeling.
Experiment
- Evaluated on AISHELL-4, Podcast, and Movies benchmarks using CER, cpCER, and Δcp metrics to assess ASR, speaker diarization, and joint performance.
- On AISHELL-4, achieved the lowest cpCER and Δcp, outperforming closed-source models including GPT-4o and Gemini 3 Pro, which failed on long-form inputs due to length constraints or output format issues.
- On Podcast, attained the best cpCER and smallest Δcp, demonstrating superior speaker attribution in long, multi-speaker discussions with frequent turn-taking.
- On Movies, surpassed all baselines in cpCER and Δcp despite short utterances and high overlap, indicating robust speaker boundary detection.
- Consistently low Δcp across datasets confirms that speaker attribution errors contribute minimally to overall degradation, validating the effectiveness of end-to-end, long-context modeling.
The authors use the table to provide context for the datasets evaluated in their experiments, showing that AISHELL-4 Test consists of long-form meeting recordings with durations around 2290 seconds and 5–7 speakers, Podcast features longer conversations with up to 11 speakers and average duration of 2658 seconds, and Movies contains short, overlap-rich segments with durations up to 29.888 seconds and 1–6 speakers. These characteristics align with the experimental findings that MOSS Transcribe Diarize performs best on long-form and complex conversational data, demonstrating robustness across varying audio lengths and speaker counts.

Results show that MOSS Transcribe Diarize achieves the lowest cpCER and Δcp across all datasets, indicating superior joint performance in speech recognition and speaker attribution. On AISHELL-4, it significantly outperforms all baselines in both CER and cpCER, with a markedly smaller Δcp, demonstrating more reliable speaker attribution over long conversations. On Podcast and Movies, it again achieves the best performance in cpCER and Δcp, highlighting robustness in both long-form and short-form conversational settings.