Command Palette
Search for a command to run...
에이버터 포르싱: 자연스러운 대화를 위한 실시간 상호작용형 헤드 에이버터 생성
에이버터 포르싱: 자연스러운 대화를 위한 실시간 상호작용형 헤드 에이버터 생성
Taekyung Ki Sangwon Jang Jaehyeong Jo Jaehong Yoon Sung Ju Hwang
초록
대화형 헤드 생성 기술은 정적인 초상화에서 실제와 유사한 아바타를 생성하여 가상 소통 및 콘텐츠 제작에 활용한다. 그러나 현재의 모델들은 여전히 진정한 상호작용의 느낌을 전달하지 못하며, 감정적 몰입이 부족한 일방적인 반응을 생성하는 경우가 많다. 진정한 상호작용 가능한 아바타를 구현하기 위해 우리는 두 가지 핵심 과제를 도출하였다. 첫째, 인과적 제약 조건 하에서 실시간으로 움직임을 생성하는 것, 둘째, 추가적인 레이블 데이터 없이도 표현력 있고 생동감 있는 반응을 학습하는 것이다. 이러한 과제를 해결하기 위해 우리는 확산 강제(diffusion forcing)를 통해 실시간 사용자-아바타 상호작용을 모델링하는 새로운 프레임워크인 Avatar Forcing을 제안한다. 이 설계는 사용자의 음성 및 운동 정보와 같은 실시간 다모달 입력을 처리할 수 있으며, 말하기, 고개 끄덕이기, 웃음 등 언어적·비언어적 신호에 즉각적으로 반응할 수 있도록 낮은 지연 시간을 보장한다. 또한, 사용자 조건을 제거하여 생성한 합성 부정 샘플을 활용하는 직접적 선호도 최적화 방법을 도입함으로써, 레이블 없이도 표현력 있는 상호작용을 학습할 수 있도록 했다. 실험 결과, 본 프레임워크는 약 500ms의 낮은 지연 시간으로 실시간 상호작용을 가능하게 하며 기준 모델 대비 6.8배의 성능 향상을 달성하였으며, 반응적이고 표현력 있는 아바타 움직임을 생성하여 기준 모델 대비 80% 이상의 선호도를 확보하였다.
One-sentence Summary
The authors from KAIST, NTU Singapore, and DeepAuto.ai propose Avatar Forcing, a diffusion-based framework enabling real-time, expressive interactive head avatars that react to multimodal user inputs—audio and motion—with low latency (~500ms) and 6.8× speedup over baselines, using a novel label-free preference optimization via synthetic condition-dropping to learn vibrant, emotionally responsive behaviors without labeled data, significantly enhancing engagement in virtual communication.
Key Contributions
- Existing talking head generation models fail to enable truly interactive communication, often producing one-way, non-reactive avatars that lack emotional engagement due to high latency and insufficient modeling of bidirectional verbal and non-verbal cues.
- The proposed Avatar Forcing framework addresses real-time interaction by employing causal diffusion forcing with key-value caching, enabling low-latency (≈500ms) generation of expressive avatar motion in response to live multimodal inputs such as audio and user motion.
- A novel label-free preference optimization method uses synthetic losing samples—created by dropping user conditions— to train expressive, reactive avatar behavior, resulting in 80% human preference over the baseline and a 6.8× speedup in inference.
Introduction
The authors address the challenge of creating truly interactive head avatars for natural conversation, where avatars must react in real time to both verbal and non-verbal user cues—such as speech, laughter, and head movements—while maintaining expressive, lifelike motion. Prior work in talking head generation often focuses on audio-driven lip sync or one-way response generation, lacking bidirectional interaction and suffering from high latency due to reliance on future context. Additionally, expressive listening behaviors like nodding or empathetic expressions are difficult to learn without labeled data, leading to stiff, unresponsive avatars. To overcome these limitations, the authors propose Avatar Forcing, a diffusion-forcing framework that enables causal, real-time generation by processing multimodal inputs (audio and motion) with low latency—achieving ~500ms response time and a 6.8× speedup over baselines. The key innovation lies in a label-free preference optimization method that synthesizes under-expressive motion samples by dropping user conditions, allowing the model to learn richer, more reactive behaviors without human annotations. This results in avatars that not only respond instantly but also exhibit natural, engaging expressions, outperforming baselines in human evaluations by 80%.
Dataset
- The dataset comprises dyadic conversation videos from RealTalk [16] and ViCo [67], selected for their natural, interactive speaker-listener dynamics.
- Videos are preprocessed by detecting scene changes using PySceneDetect [44], splitting them into individual clips for focused analysis.
- Each face is detected and tracked using Face-Alignment [4], then cropped and resized to 512×512 pixels to standardize visual input.
- Speaker and listener audio are separated using a visual-grounded speech separation model [30], leveraging visual cues for accurate audio assignment.
- All video content is converted to 25 frames per second, and audio is resampled to 16 kHz to ensure consistent temporal and spectral alignment.
- A subset of 50 videos from the HDTF [66] dataset is randomly selected for evaluating talking-head generation performance.
- The data is used in training with a mixture of RealTalk and ViCo subsets, where each subset contributes to the overall training split based on predefined ratios.
- Metadata is constructed during preprocessing to associate speaker and listener roles, clip boundaries, and audio-visual alignment, supporting interactive avatar generation.
- No explicit cropping beyond face-centered 512×512 crops is applied, and all processing is designed to preserve natural conversational context and visual fidelity.
Method
The authors leverage diffusion forcing as the core generative mechanism for real-time interactive head avatar generation, operating within a motion latent space. The overall framework, illustrated in the figure below, consists of two primary stages: encoding multimodal user and avatar signals, and causal inference of avatar motion. The motion latent auto-encoder, detailed in the accompanying figure, maps an input image S to a latent z that is explicitly decomposable into an identity latent zS and a motion latent mS. This decomposition allows the model to capture holistic head motion and fine-grained facial expressions, which are essential for realistic avatar generation. The motion generation process is formulated as an autoregressive model, where each motion latent mi is predicted conditioned on past motion latents and a condition triplet ci comprising user audio aui, user motion mui, and avatar audio ai.
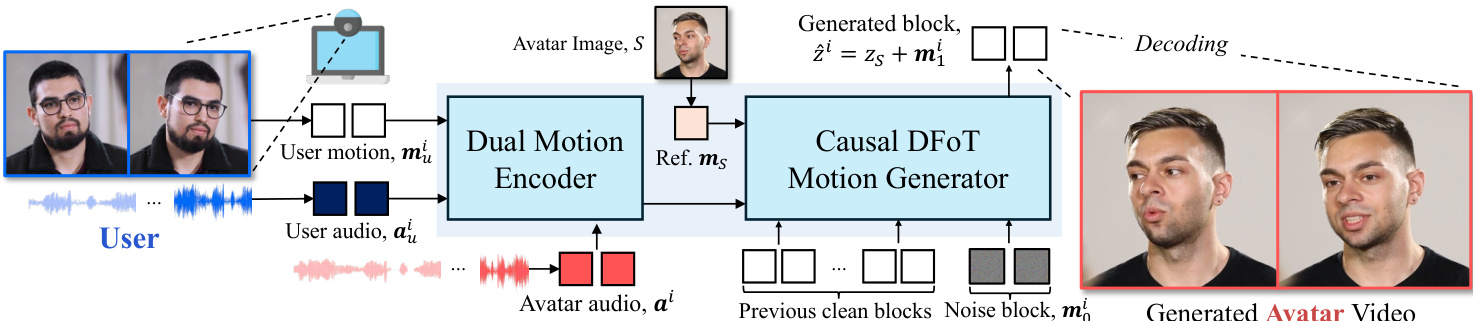
The core of the motion generation is a diffusion forcing-based causal motion generator, modeled as a vector field vθ. As shown in the figure below, this model is composed of two main components: a Dual Motion Encoder and a Causal DFoT Motion Generator. The Dual Motion Encoder first processes the user motion mui and user audio aui through a cross-attention layer to capture holistic user motion. This representation is then integrated with the avatar audio ai using another cross-attention layer, which learns the causal relationship between the user and the avatar, producing a unified condition. The Causal DFoT Motion Generator, detailed in the figure below, operates on the motion latent space using a blockwise causal structure. The latent frames are divided into blocks to capture local bidirectional dependencies within each block while maintaining causal dependencies across blocks. For each block, a shared noise timestep is applied, and an attention mask prevents the current block from attending to any future blocks, enabling stepwise motion generation under causal constraints.
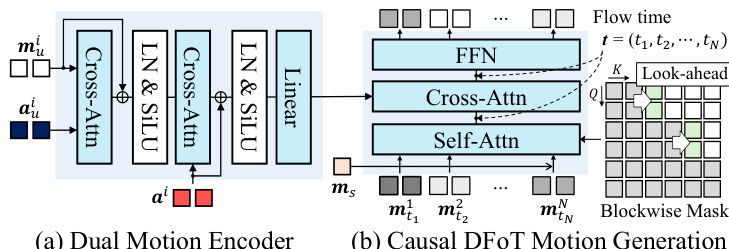
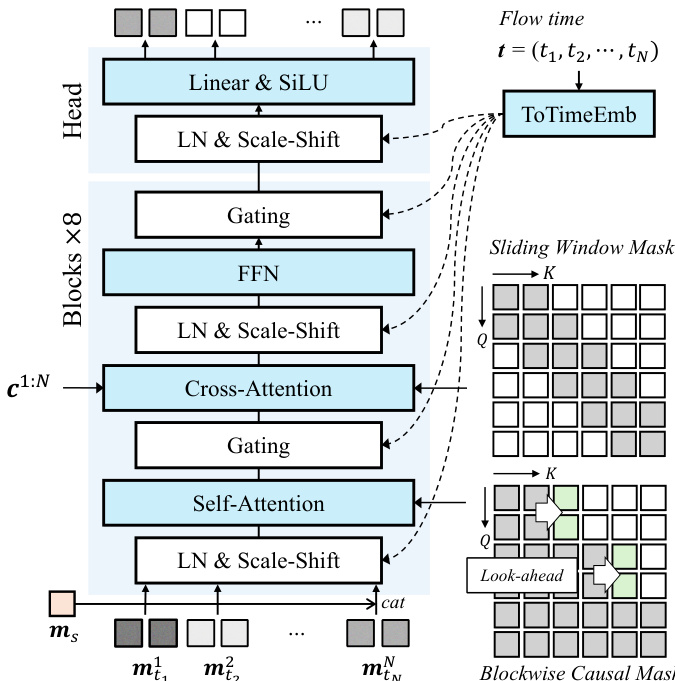
To address the issue of temporal jittering caused by the strict causal mask, the authors introduce a look-ahead mechanism in the causal mask. This allows each block to attend to a limited number of future frames, ensuring a smooth transition across blocks while preserving overall causality. The blockwise look-ahead causal mask M is defined such that a frame i can attend to frame j if ∣j/B∣≤∣i/B∣+l, where B is the block size and l is the look-ahead frame size. The model vθ is trained using a diffusion forcing objective that regresses the vector field vθ towards the target vector field (m1n−m0n), where m0n is the clean motion latent and m1n is the noisy motion latent. During inference, the model generates motion latents in a blockwise manner, utilizing a rolling key-value (KV) cache to maintain context and achieve low-latency real-time interaction. The figure below provides a detailed architecture of the Causal DFoT Motion Generator, which consists of eight DFoT transformer blocks followed by a transformer head. Each DFoT block modulates the noisy latents by the flow time t through a shared AdaLN scale-shift coefficients layer. The attention modules use the blockwise causal look-ahead mask for self-attention and a sliding-window attention mask to align the driving signal c1:N to the noisy latents.
Experiment
- Evaluates interactive avatar generation across latency, reactiveness, motion richness, visual quality, and lip synchronization using metrics including rPCC, SID, Var, FID, FVD, CSIM, LSE-D, and LSE-C.
- On the RealTalk dataset, Avatar Forcing achieves 0.5s latency, outperforms INFP* in reactiveness and motion richness, and maintains comparable visual quality and lip synchronization, enabling real-time interaction.
- Human preference study with 22 participants shows over 80% preference for Avatar Forcing across all metrics, particularly in reactivity, motion richness, and non-verbal alignment.
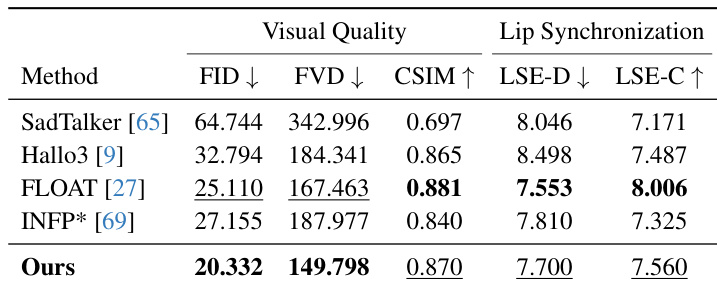
- On the HDTF dataset, Avatar Forcing achieves competitive performance with the best image and video quality (FID, FVD) and strong lip synchronization (LSE-D, LSE-C) compared to SadTalker, Hallo3, FLOAT, and INFP*.
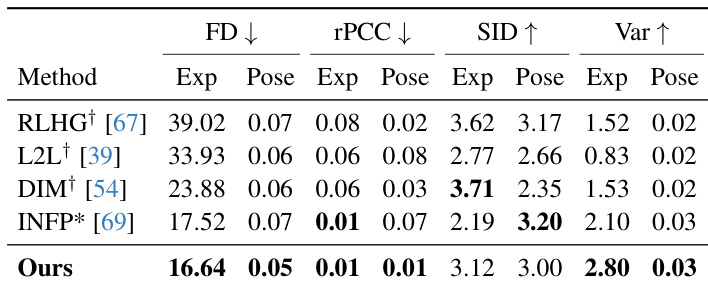
- On the ViCo dataset, Avatar Forcing outperforms listening head avatar models (RLHG, L2L, DIM, INFP*) in user-avatar motion synchronization (rPCC), expression and pose diversity (SID, Var), and distributional similarity (FD).
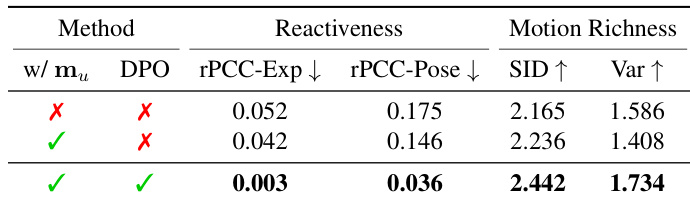
- Ablation studies confirm that user motion input is essential for reactivity and expressiveness, with removal leading to static behavior during silent audio.
- Preference optimization via DPO significantly improves rPCC, SID, and Var, resulting in more expressive and reactive avatar motion, as validated by both quantitative metrics and qualitative visualizations.
The authors use an ablation study to evaluate the impact of user motion input and preference optimization on avatar generation. Results show that including both user motion and preference optimization significantly improves reactivity and motion richness, with the best performance achieved when both components are present.
Results show that the proposed model achieves the lowest latency of 0.5s, significantly outperforming baselines in reactivity and motion richness while maintaining competitive visual quality and lip synchronization. The model's superior performance in reactivity and motion richness metrics indicates more expressive and synchronized avatar behavior compared to existing methods.

Results show that the proposed method achieves superior visual quality, as indicated by lower FID and FVD scores, and better identity preservation with a higher CSIM value compared to SadTalker, Hallo3, FLOAT, and INFP*. The model also maintains competitive lip synchronization performance, with lower LSE-D and higher LSE-C scores, demonstrating effective alignment between generated lip motion and audio.
Results show that the proposed model achieves higher reactivity, motion richness, verbal alignment, non-verbal alignment, and overall preference compared to the baselines INFP* and Tie. The model demonstrates superior performance in generating expressive and synchronized avatar motions, with significant improvements in user-avatar interaction metrics.

Results show that the proposed model achieves the best performance across all metrics compared to the baselines, with the lowest Frechet distance (FD) for expression and pose, the highest similarity index for diversity (SID), and the highest variance (Var) for both expression and pose. The model also demonstrates superior motion synchronization, as indicated by the lowest residual Pearson correlation coefficients (rPCC) for expression and pose, indicating more reactive and expressive avatar motion.