Command Palette
Search for a command to run...
FlowBlending: 빠르고 고정밀 영상 생성을 위한 단계 인식 다중 모델 샘플링
FlowBlending: 빠르고 고정밀 영상 생성을 위한 단계 인식 다중 모델 샘플링
Jibin Song Mingi Kwon Jaeseok Jeong Youngjung Uh
초록
이 연구에서는 모델 용량의 영향이 시간 단계에 따라 달라진다는 점을 보여준다. 즉, 초기 및 후기 단계에서는 매우 중요하지만, 중간 단계에서는 거의 무시할 수 있을 정도로 영향이 작다. 이를 바탕으로, 용량 민감한 단계에는 대규모 모델, 중간 단계에는 소규모 모델을 각각 활용하는 단계 인식형 다중 모델 샘플링 전략인 FlowBlending을 제안한다. 또한 단계 경계를 선택하기 위한 간단한 기준을 도입하고, 용량 민감 구역을 효과적으로 식별할 수 있는 속도-분산 분석(velocity-divergence analysis)을 제시한다. LTX-Video(2B/13B) 및 WAN 2.1(1.3B/14B)에서 FlowBlending은 시각적 정확도, 시간적 일관성, 의미적 정렬을 대규모 모델 수준으로 유지하면서 추론 속도를 최대 1.65배 빠르게 하고, FLOPs를 57.35% 감소시킨다. 더불어 기존의 샘플링 가속 기법과도 호환되어 최대 2배 추가적인 속도 향상을 가능하게 한다. 프로젝트 페이지는 다음과 같다: https://jibin86.github.io/flowblending_project_page.
One-sentence Summary
The authors from Yonsei University propose FlowBlending, a stage-aware multi-model sampling strategy that assigns a large model to early and late denoising stages for structural and detail fidelity, and a small model to intermediate stages where capacity differences matter less, reducing FLOPs by 57.35% and accelerating inference up to 1.65× while preserving visual quality and compatibility with existing acceleration methods.
Key Contributions
- Model capacity in video diffusion is not uniformly important across timesteps: early stages require large models for establishing global structure and semantic alignment, while late stages benefit from large models for refining high-frequency details, whereas intermediate stages show minimal performance difference between large and small models.
- FlowBlending introduces a stage-aware multi-model sampling strategy that dynamically allocates a large model to capacity-sensitive early and late stages and a small model to intermediate stages, using semantic similarity and velocity divergence as practical criteria to identify optimal stage boundaries without retraining.
- Evaluated on LTX-Video (2B/13B) and WAN 2.1 (1.3B/14B), FlowBlending achieves up to 1.65× faster inference and 57.35% fewer FLOPs while preserving the visual fidelity, temporal coherence, and semantic alignment of large models, and remains compatible with existing acceleration techniques for additional speedups.
Introduction
The authors leverage the observation that not all denoising stages in video diffusion models require the same level of capacity, challenging the common assumption of uniform model usage across timesteps. In diffusion-based video generation, large models deliver superior visual fidelity and temporal coherence but incur high computational costs, while small models are efficient yet struggle with semantic accuracy and detail preservation. Prior acceleration methods either reduce sampling steps or distill models, but they treat all timesteps equally and often require retraining. The authors’ main contribution is FlowBlending, a stage-aware multi-model sampling strategy that assigns a large model only to early and late denoising stages—where global structure and fine details are established—while using a small model for the intermediate stages, where velocity divergence between models is minimal. This approach achieves up to 1.65× faster inference and 57.35% fewer FLOPs without retraining, distillation, or architectural changes, while maintaining near-identical quality to the large model. The method is complemented by practical heuristics based on semantic similarity and detail quality to guide model allocation, and it remains orthogonal to existing acceleration techniques, enabling further efficiency gains when combined.
Method
The authors leverage a stage-aware multi-model sampling strategy, termed FlowBlending, to optimize computational efficiency in video generation while preserving high-quality outputs. This approach is grounded in the observation that model capacity has varying importance across different stages of the denoising process. Specifically, the early and late stages are critical for establishing global structure and refining fine details, respectively, whereas the intermediate stage is more tolerant to reduced model capacity.
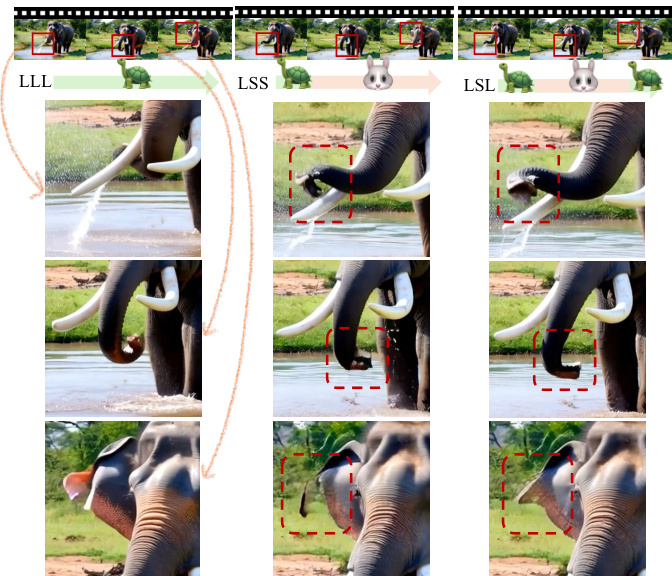
The framework dynamically allocates computational resources by employing a large model during the capacity-sensitive early and late stages and a small model during the intermediate stage. This scheduling strategy enables near-equivalent performance to a large model while significantly reducing computational overhead. As shown in the figure below, the method achieves a balanced trade-off between quality and efficiency, with the large model used at the beginning and end of the denoising trajectory and the small model handling the central phase.

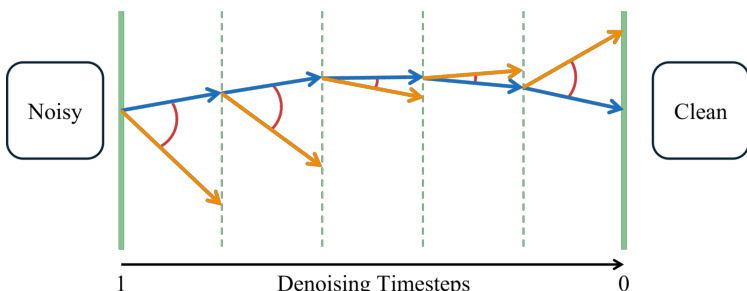
The design of FlowBlending is further informed by a velocity-divergence analysis, which serves as an effective proxy for identifying capacity-sensitive regions within the denoising process. This analysis helps determine the optimal boundaries between the early, intermediate, and late stages. The authors use this criterion to define stage transitions, ensuring that the model switch occurs at points where the dynamics of the denoising process most strongly benefit from a change in capacity.
The method is evaluated across multiple model configurations, including LTX-Video (2B/13B) and WAN 2.1 (1.3B/14B), demonstrating significant improvements in inference speed and FLOP efficiency. The results indicate that FlowBlending maintains visual fidelity, temporal coherence, and semantic alignment comparable to large models, while enabling up to 1.65× faster inference and 57.35% fewer FLOPs. The approach is also compatible with existing sampling-acceleration techniques, allowing for additional speedup.

The underlying mechanism is illustrated through a trajectory-based analysis, where the denoising process is represented as a path from a noisy input to a clean output. The velocity-divergence analysis identifies regions where the trajectories of large and small models diverge significantly, indicating capacity-sensitive stages. These regions are used to define the boundaries for model switching.
Experiment
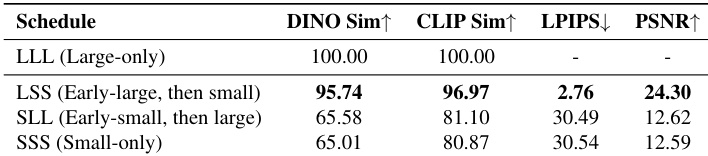
- Early structure formation: Using the large model only in early denoising steps (LSS) preserves global structure, motion coherence, and semantic alignment comparable to large-only (LLL), while small-only (SSS) or early-small (SLL) schedules fail, indicating the early stage is critical for establishing high-level attributes. On PVD and VBench, LSS achieves DINO and CLIP similarity within 96% of LLL, confirming semantic fidelity.
- Late refinement: Reintroducing the large model in the final steps (LSL) reduces high-frequency artifacts and improves detail, with FID scores significantly lower than LSS. On both LTX-Video and WAN 2.1, LSL achieves FID and FVD scores nearly indistinguishable from LLL, demonstrating the late stage is capacity-sensitive for artifact suppression and fine-grained refinement.
- Core results: The proposed LSL schedule achieves up to 1.65× faster inference and 57.35% fewer FLOPs than LLL, while maintaining near-identical quality across FID, FVD, and VBench metrics (Aesthetic Quality, Subject Consistency, Motion Smoothness) on both LTX-Video and WAN 2.1. It outperforms LSS (which retains structure but introduces artifacts) and SSS (which degrades across all metrics).
Results show that the LSL schedule, which uses the large model in the early and late stages and the small model in the intermediate stage, achieves video quality nearly indistinguishable from the large-only baseline (LLL) across all metrics, while significantly reducing computational cost. In contrast, the LSS schedule preserves global structure but fails to resolve late-stage artifacts, and the SSS schedule exhibits substantial degradation in both quality and consistency.

The authors use a stage-aware sampling strategy that applies the large model only during the early and late denoising stages, while using the small model for intermediate steps, to balance computational efficiency and video quality. Results show that this approach, particularly the LSL schedule, achieves performance nearly indistinguishable from the large-only baseline across multiple metrics while significantly reducing runtime and FLOPs.
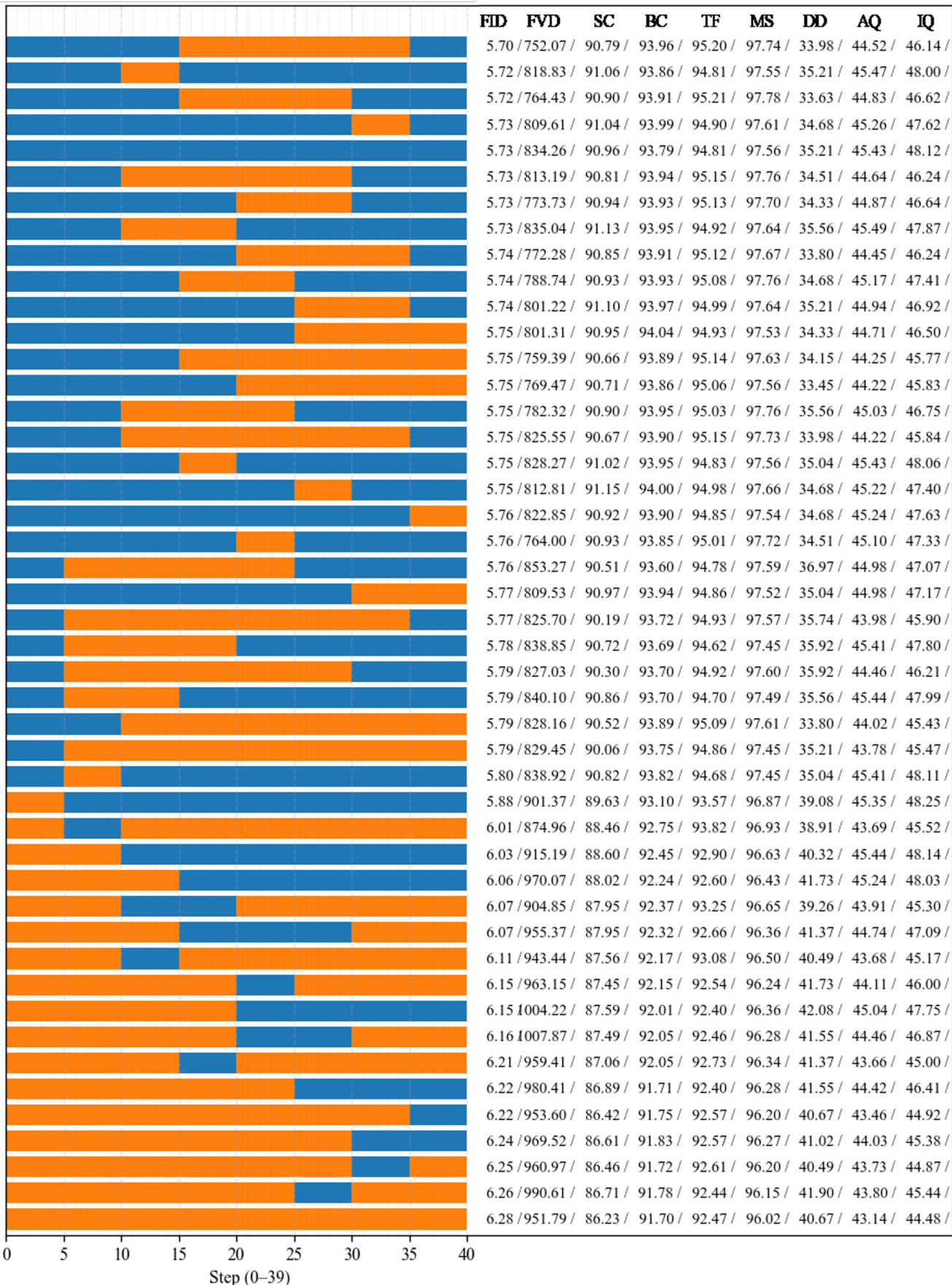
The authors use a stage-aware sampling strategy that applies the large model during the early and late denoising stages and the small model in the intermediate stage, achieving video quality nearly indistinguishable from the large-only baseline while reducing computational cost. Results show that the early stage is critical for establishing global structure and semantic alignment, and the late stage is essential for detail refinement and artifact suppression, with both stages being capacity-sensitive.
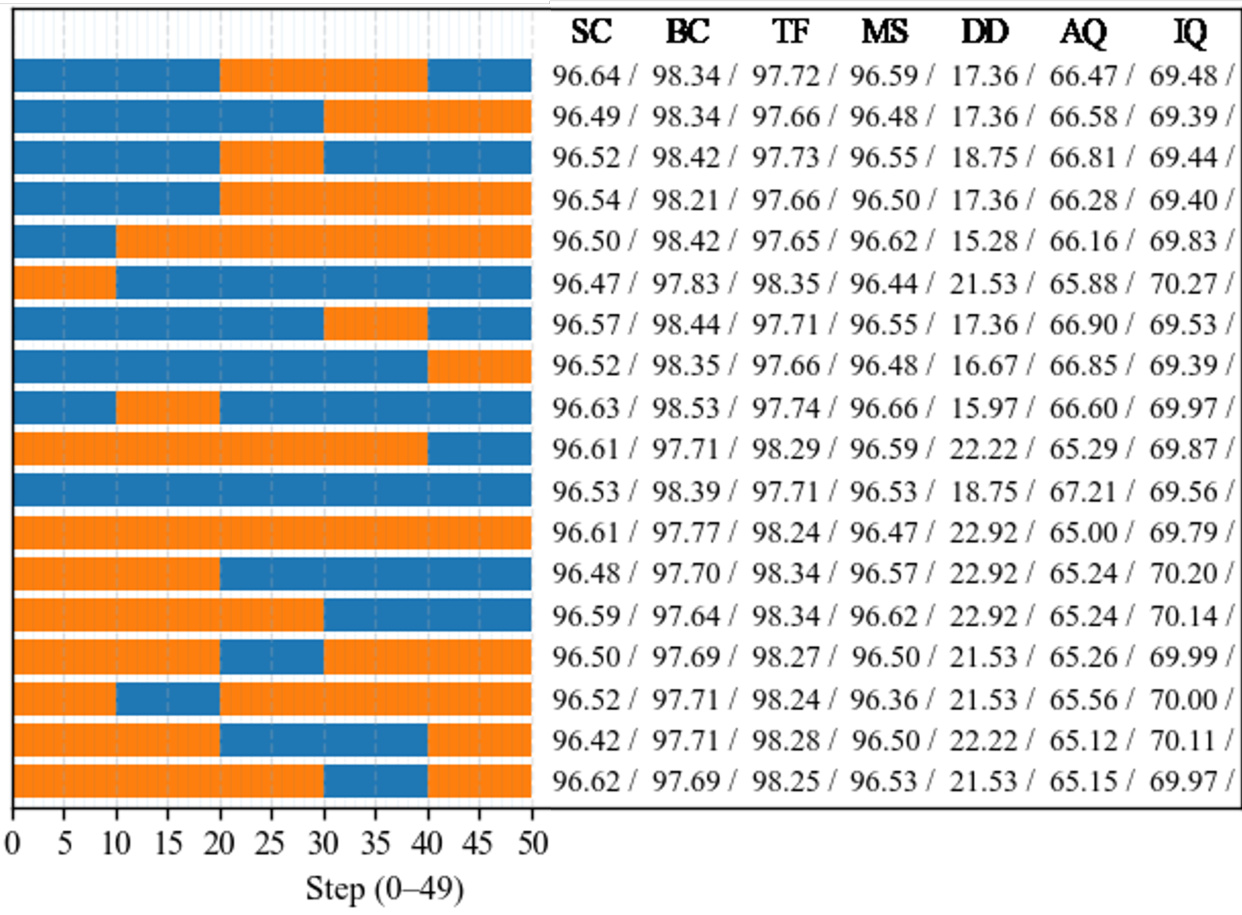
Results show that the LSL (Stage-aware, Ours) schedule achieves performance nearly identical to the large-only baseline (LLL) across all metrics, including FID, FVD, and perceptual quality, while significantly reducing runtime and computational cost. In contrast, the SSS (Small-only) schedule exhibits substantial degradation in quality, particularly in FVD and motion coherence, highlighting the critical role of the large model in early and late stages for maintaining structural and semantic fidelity.

Results show that the LSS schedule, which uses the large model only in the early denoising steps, maintains high similarity to the large-only baseline (LLL) across semantic and low-level metrics, indicating that early-stage capacity is critical for establishing global structure and motion. In contrast, SSS and SLL schedules, which delay or omit large-model usage in the early stage, exhibit significantly lower similarity, demonstrating that misalignment in early structure cannot be recovered later.