Command Palette
Search for a command to run...
동적 대규모 개념 모델: 적응형 의미 공간에서의 잠재적 추론
동적 대규모 개념 모델: 적응형 의미 공간에서의 잠재적 추론
초록
대규모 언어 모델(LLMs)은 언어의 정보 밀도가 매우 비균일함에도 불구하고 모든 토큰에 대해 동일한 계산을 적용한다. 이러한 토큰 중심의 계산 방식은 지역적으로 예측 가능한 구간에서는 계산 용량을 낭비하고, 의미적으로 중요한 전이 구간에는 계산을 부족하게 할 수 있다. 본 연구에서는 잠재 표현에서 의미적 경계를 학습하고, 계산을 토큰 공간에서 추상화된 개념 공간으로 이동시켜 더 효율적인 추론을 가능하게 하는 계층적 언어 모델링 프레임워크인 동적 대규모 개념 모델(Dynamic Large Concept Models, DLCM) 을 제안한다. DLCM은 사전 정의된 언어 단위에 의존하지 않고, 종단 간(end-to-end)으로 길이가 변하는 개념을 탐지한다. 계층적 압축은 스케일링 행동을 근본적으로 변화시킨다. 우리는 처음으로 압축 인식 스케일링 법칙(compression-aware scaling law) 을 도입하여, 토큰 수준의 용량, 개념 수준의 추론 용량, 압축 비율을 분리함으로써 고정된 FLOPs 조건 하에서 체계적인 컴퓨팅 자원 할당을 가능하게 한다. 이 비균질한 아키텍처를 안정적으로 훈련하기 위해, 너비와 압축 구간 간에 제로샷 하이퍼파라미터 전이를 지원하는 분리된 μP 매개변수화(decoupled μP parametrization) 도 개발하였다. 실용적인 설정(R=4, 평균적으로 개념당 4개의 토큰)에서 DLCM은 추론 계산의 약 1/3을 더 높은 용량의 추론 백본으로 재할당하며, 동일한 추론 FLOPs 조건 하에서 12개의 제로샷 벤치마크에서 평균적으로 +2.69% 향상을 달성하였다.
One-sentence Summary
ByteDance Seed, University of Manchester, Mila, Tsinghua University, and M-A-P introduce Dynamic Large Concept Models (DLCM), a hierarchical framework that shifts computation to a compressed semantic space. It features end-to-end variable-length concepts and a compression-aware scaling law, achieving a +2.69% average improvement across 12 benchmarks under matched inference FLOPs.
Key Contributions
-
Standard LLMs waste computation on predictable tokens and under-allocate to semantically critical transitions. DLCM introduces a hierarchical framework that learns semantic boundaries end-to-end and shifts reasoning to a compressed concept space, decoupling concept formation from token-level decoding.
-
The method uses a four-stage pipeline with a learned boundary detector to segment tokens into variable-length concepts and a high-capacity transformer for concept-level reasoning. A decoupled μP parametrization enables stable training and zero-shot hyperparameter transfer across widths and compression regimes.
-
The authors present the first compression-aware scaling law that disentangles token-level capacity, concept-level reasoning capacity, and compression ratio for principled compute allocation. At R=4, DLCM reallocates about one-third of inference FLOPs to the reasoning backbone, achieving a +2.69% average improvement across 12 zero-shot benchmarks under matched inference FLOPs.
Introduction
LLMs process every token with equal computation, which is inefficient because natural language has varying information density and reasoning is inherently hierarchical. The authors propose Dynamic Large Concept Models (DLCM), a framework that learns semantic boundaries and shifts heavy computation to a compressed concept space. This approach overcomes the limitations of prior work by discovering variable-length concepts end-to-end, rather than relying on fixed linguistic units. Their key contribution is a hierarchical architecture that separates concept formation from reasoning, plus a new scaling law, achieving better performance under matched inference costs.
Dataset
-
Dataset Composition and Sources
- The authors construct a pretraining corpus entirely from open-source data, using the DeepSeek-v3 tokenizer.
- The dataset spans multiple domains, including English and Chinese web text, mathematics, and code.
- This mix is designed to provide broad language coverage and enhance structured reasoning.
- The diversity in data, from verbose prose to structured code, is essential for training the model's dynamic segmentation capabilities.
- English and Chinese web text are weighted more heavily for multilingual alignment, while specialized datasets like MegaMath-Web and OpenCoder-Pretrain are included to improve handling of high-entropy transitions.
-
Subset Details and Filtering
- The authors do not apply aggressive filtering to avoid gains from data curation, ensuring that any performance improvements are due to the architectural benefits of DLCM.
- The data quality aligns with standard open-source corpora.
- Specific statistics for the pretraining data are summarized in Table 1.
-
Data Usage and Processing
- The entire corpus is tokenized using the DeepSeek-v3 [14] tokenizer.
- The data is used for pretraining the model, with the mixture of domains serving two critical objectives: balancing breadth and specialization, and enabling robust dynamic segmentation.
- The authors intentionally expose the model to domains with different information densities to force the learned boundary predictor to discover content-adaptive segmentation strategies.
Method
The authors leverage a hierarchical next-token prediction architecture called Dynamic Large Concept Model (DLCM) to enable concept-level latent reasoning with learned boundaries. The overall framework, as shown in the figure below, consists of four sequential stages: encoding, dynamic segmentation, concept-level reasoning, and token-level decoding. The encoder, a standard causal Transformer, processes the input token sequence to generate fine-grained representations. These representations are then fed into a dynamic segmentation module that detects semantic boundaries by measuring local dissimilarity between adjacent token embeddings, using a cosine similarity-based boundary probability. The detected boundaries partition the sequence into variable-length segments, which are compressed into single concept representations via mean pooling and projection to a concept dimension. This compressed sequence is then processed by a concept-level Transformer, which performs deep reasoning in a semantically aligned space, significantly reducing attention complexity. Finally, the decoder reconstructs token-level predictions by attending to the reasoned concepts through a causal cross-attention mechanism, where each token can only attend to concepts formed up to its corresponding boundary index.
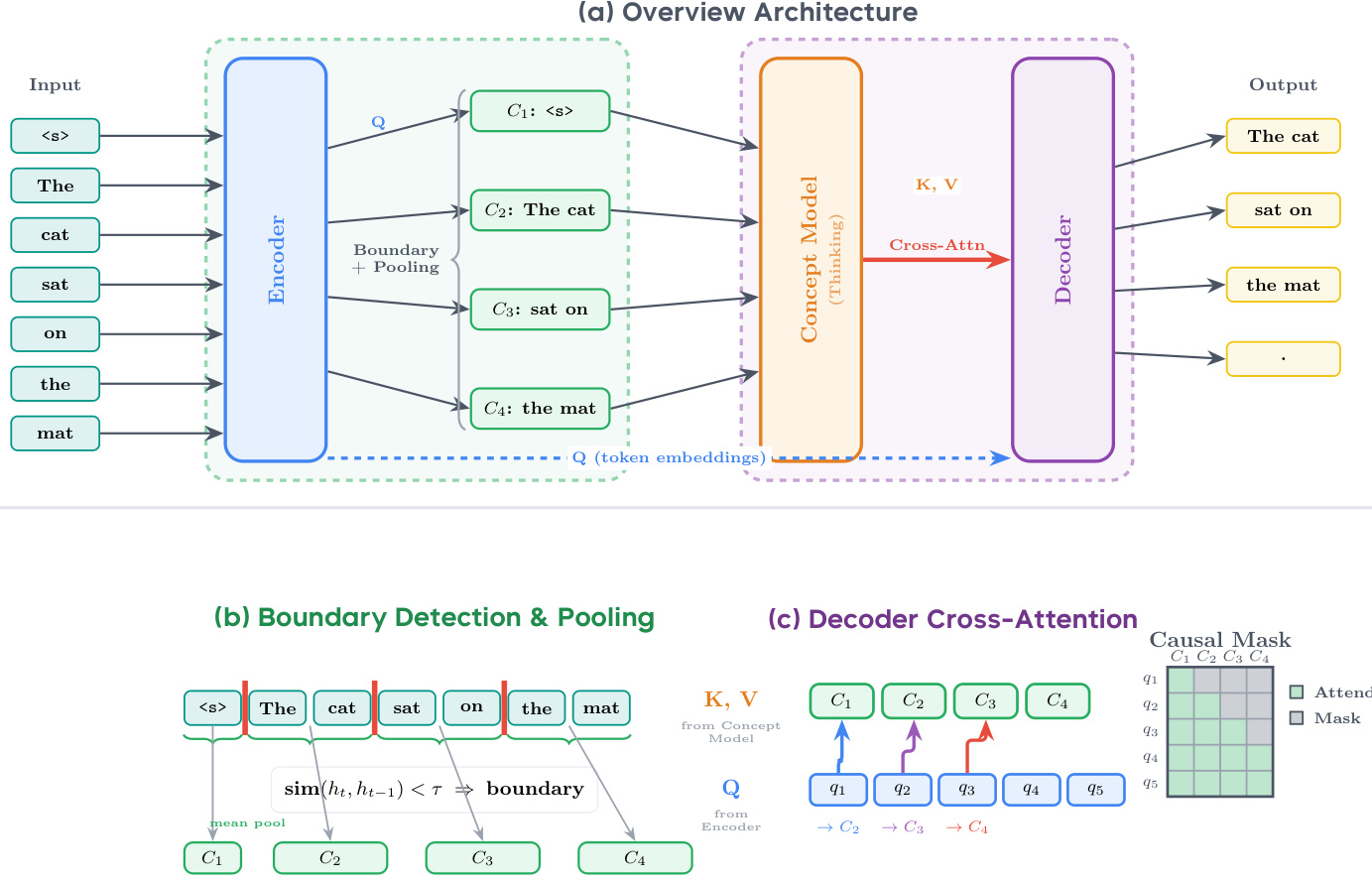
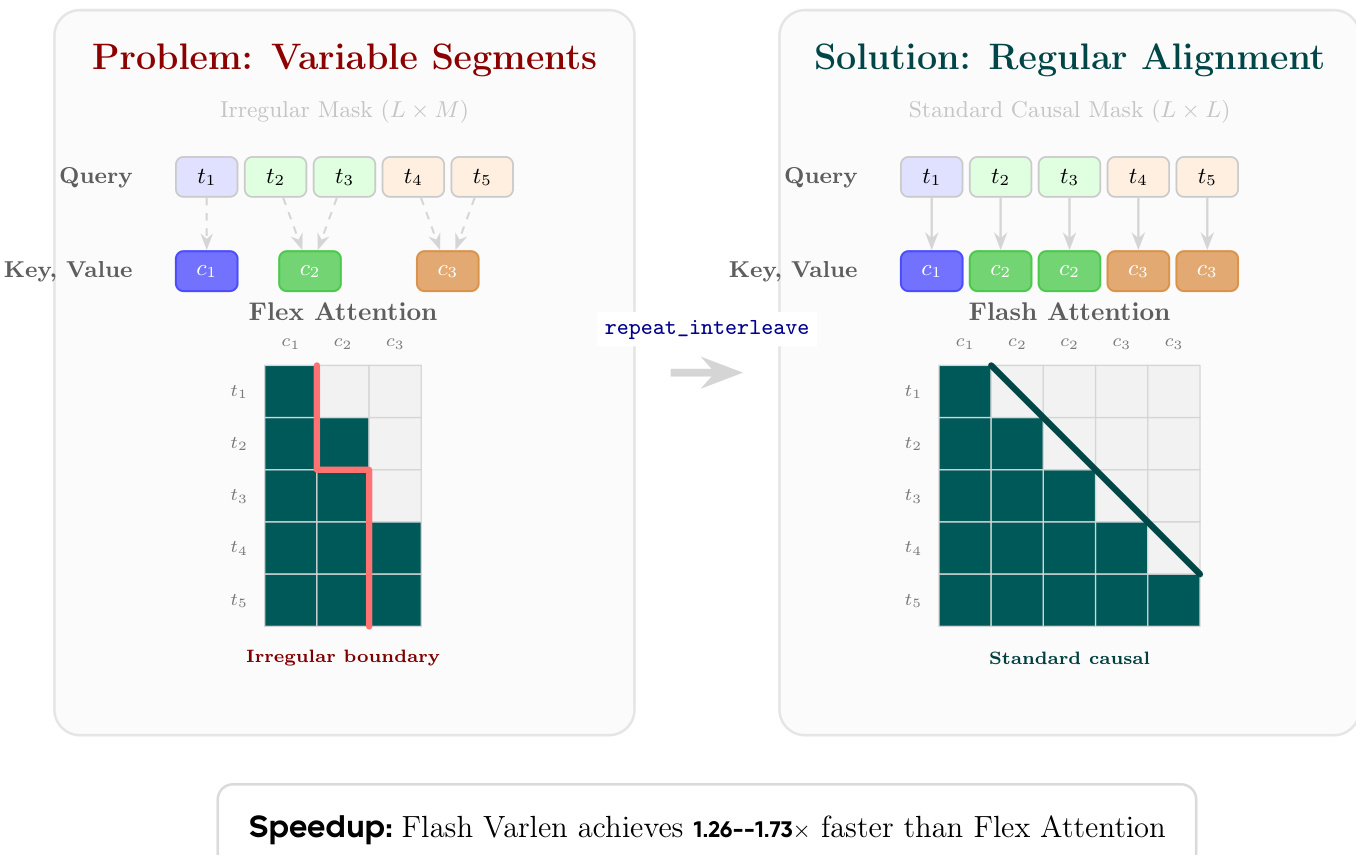
A critical implementation challenge arises in the decoder's cross-attention mechanism, where tokens must attend to concepts with variable-length mappings, creating irregular attention patterns. As illustrated in the figure below, this leads to an irregular mask that is inefficient for hardware acceleration. To address this, the authors adopt a concept replication strategy, expanding the concept features via repeat_interleave to match the token sequence length. This transformation aligns the key and value sequences with the query sequence, enabling the use of highly optimized Flash Attention with Variable Length (Varlen) kernels, which treat the problem as a specialized form of self-attention with locally constant keys and values within each concept segment. This approach achieves a significant speedup over direct Flex Attention implementation.
The training objective combines next-token prediction loss with an auxiliary loss for global load balancing, which enforces a target compression ratio across the distributed batch. To ensure stable training and optimal performance at scale, the authors adapt the Maximal Update Parametrization (μP) to their heterogeneous architecture, decoupling the learning rates and initialization variances for the token-level components and the concept-level backbone based on their respective widths. This decoupled μP enables zero-shot hyperparameter transfer from a small proxy model to larger scales, confirming its effectiveness in stabilizing training for unequal-width models.
Experiment
- Performance benchmarks validate the concept replication strategy's efficiency, showing it consistently outperforms Flex Attention with speedups from 1.26x to 1.73x. The performance advantage scales with sequence length, reaching up to 1.73x at 16K sequences, while remaining insensitive to hidden dimension size.
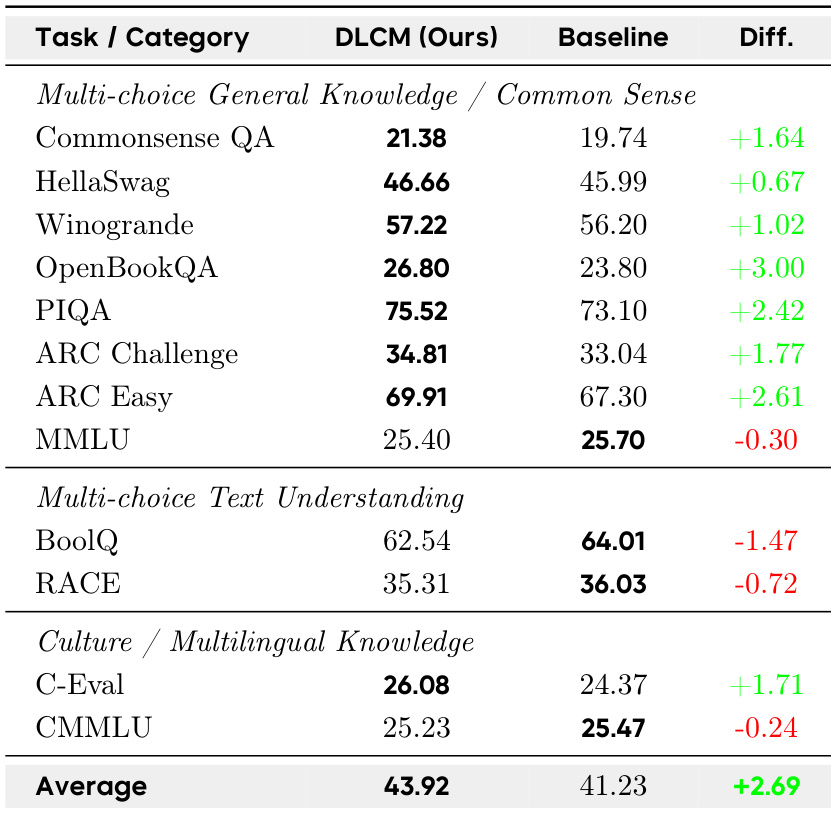
- The main results compare DLCM against a parameter-matched LLaMA baseline. On 12 zero-shot benchmarks, DLCM achieves an average accuracy of 43.92%, surpassing the baseline by +2.69%. Gains are concentrated on reasoning-dominant tasks, while minor regressions occur on fine-grained understanding benchmarks. Despite having nearly double the parameters, DLCM maintains comparable inference FLOPs to the smaller baseline.
- Architectural efficiency analysis validates the selection of a compression ratio of R=4, offering the best balance between training stability and computational efficiency.
- Loss distribution analysis reveals a "U-shaped" pattern, where the concept model excels at semantic boundaries but trades off some fine-grained precision in internal positions, validating the strategy of reallocating computation to structurally salient regions.
- Boundary learning analysis compares a learned neural predictor with a rule-based one. The rule-based predictor demonstrates superior stability, converging to the target compression, whereas the learned predictor suffers from instability due to conflicting optimization objectives.
- Content-adaptive compression analysis confirms the model adapts segmentation granularity to semantic density, compressing code into shorter units while preserving longer chunks for dense prose, maximizing information retention within the global budget.
The authors compare DLCM against a parameter-matched LLaMA baseline on 12 zero-shot benchmarks, showing DLCM achieves an average accuracy of 43.92% versus 41.23% for the baseline, a +2.69% improvement. Performance gains are most pronounced on reasoning-dominant tasks such as OpenBookQA (+3.00%) and ARC Easy (+2.61%), while mild regressions occur on fine-grained text understanding tasks like BoolQ (-1.47%) and RACE (-0.72%), reflecting the model’s trade-off between global coherence and token-level precision.
The authors analyze the adaptive compression behavior of their model across different content types using Table 5, which shows the average number of tokens per concept under target compression ratios of 2×, 4×, and 8×. Results indicate that the model dynamically adjusts segmentation granularity based on semantic density, with technical English retaining more tokens per concept (10.58 at 8×) compared to code or technical Chinese (6.14 and 6.09 respectively), demonstrating content-adaptive compression that preserves information more effectively in dense prose while enabling tighter compression in structured content.
The authors benchmark the efficiency of Flash Attention Varlen with concept replication against Flex Attention using independent kernel profiling across varying sequence lengths and hidden sizes. Results show that Flash Varlen consistently outperforms Flex Attention, with speedups ranging from 1.26× to 1.73×, and the performance advantage increases with longer sequences, peaking at 1.73× for a sequence length of 16K and hidden size of 2048. The speedup remains largely insensitive to hidden size, indicating that memory access patterns, not computational complexity, dominate the performance bottleneck.
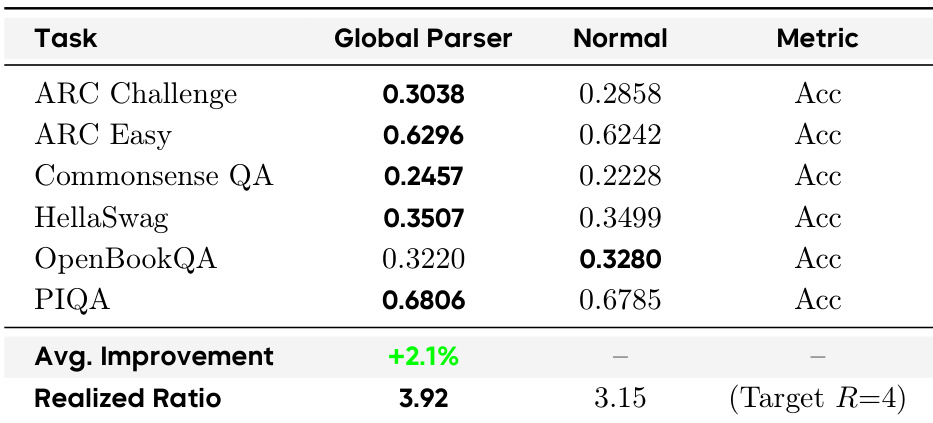
The authors compare two boundary prediction mechanisms in DLCM: a Global Parser and a Normal (learned) predictor, both targeting a compression ratio of R=4. Results show the Global Parser achieves a realized ratio of 3.92, closer to the target, and delivers an average accuracy improvement of +2.1% across reasoning-dominant benchmarks, outperforming the Normal predictor which achieves a realized ratio of 3.15 and shows lower accuracy on most tasks.