Command Palette
Search for a command to run...
유튜브-에이전트: 자동 생성과 하이브리드 정책 최적화를 통한 에이전트 생산성 확장
유튜브-에이전트: 자동 생성과 하이브리드 정책 최적화를 통한 에이전트 생산성 확장
초록
기존의 대규모 언어 모델(LLM) 에이전트 프레임워크는 두 가지 주요 과제에 직면해 있다. 첫째, 높은 구성 비용이며, 둘째, 정적 기능성이다. 고품질의 에이전트를 구축하기 위해서는 도구 통합과 프롬프트 엔지니어링에 상당한 수동적 노력이 필요하며, 배포된 에이전트는 비용이 큰 파인튜닝 없이 동적 환경에 적응하는 데 어려움을 겪는다. 이러한 문제를 해결하기 위해, 우리는 LLM 에이전트의 자동 생성과 지속적 진화를 위한 모듈러한 프레임워크인 Youtu-Agent를 제안한다. Youtu-Agent는 실행 환경, 툴킷, 컨텍스트 관리 시스템을 구조화된 방식으로 분리함으로써 유연한 재사용과 자동 합성 가능성을 제공하는 구성 시스템을 특징으로 한다. 우리는 두 가지 생성 패러다임을 도입한다. 첫째, 표준적인 작업을 위한 워크플로우(Workflow) 모드이며, 둘째, 복잡하고 비표준적인 요구사항을 처리할 수 있는 메타에이전트(Meta-Agent) 모드로, 도구 코드, 프롬프트, 구성 파일을 자동으로 생성할 수 있다. 더불어 Youtu-Agent는 하이브리드 정책 최적화 시스템을 구축하였으며, (1) 에이전트 연습(Agent Practice) 모듈은 파라미터 업데이트 없이 컨텍스트 기반 최적화를 통해 에이전트가 경험을 축적하고 성능을 향상시킬 수 있도록 하며, (2) 에이전트 강화학습(Agent RL) 모듈은 분산 학습 프레임워크와 통합되어, 엔드투엔드 방식으로 대규모로 안정적인 강화학습을 가능하게 하여 모든 Youtu-Agent에 대해 확장 가능한 학습을 지원한다. 실험 결과, Youtu-Agent는 오픈 웨이트 모델을 사용하여 WebWalkerQA(71.47%) 및 GAIA(72.8%)에서 최신 기준(SOTA) 성능을 달성하였다. 자동 생성 파이프라인은 81% 이상의 도구 합성 성공률을 기록하였으며, 연습 모듈은 AIME 2024/2025에서 각각 +2.7%, +5.4%의 성능 향상을 이끌었다. 또한, 에이전트 RL 학습은 7B LLM 기준으로 40%의 속도 향상을 달성하면서 안정적인 성능 향상이 지속되었으며, Maths 및 일반/다단계 QA 벤치마크에서 각각 코딩/추론 능력과 검색 능력이 최대 35%, 21% 향상되었다.
One-sentence Summary
The authors from Tencent Youtu Lab, Fudan University, and Xiamen University propose Youtu-Agent, a modular framework enabling automated generation of LLM agents via Workflow and Meta-Agent modes, with a hybrid policy optimization system combining training-free experience accumulation and scalable reinforcement learning, achieving state-of-the-art performance on WebWalkerQA and GAIA while reducing configuration costs and enabling continuous evolution without expensive fine-tuning.
Key Contributions
- Youtu-Agent introduces a modular, YAML-based architecture that decouples environments, toolkits, and agents, enabling automated generation of executable agent configurations—including tool code and prompts—reducing configuration costs and supporting flexible, reusable component design.
- The framework implements a dual-paradigm generation system: Workflow mode for deterministic, routine tasks and Meta-Agent mode for dynamic, complex requirements, allowing autonomous synthesis of agent behavior without manual intervention.
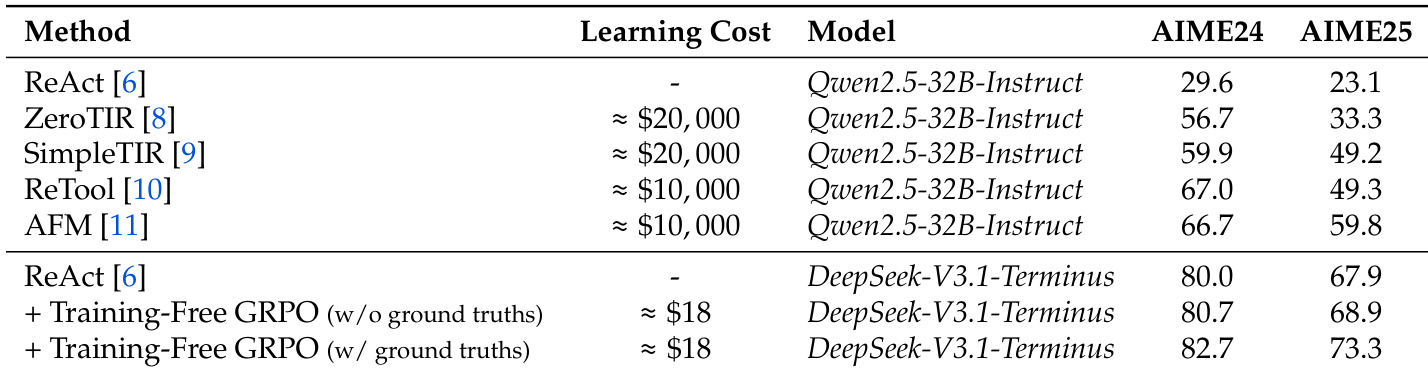
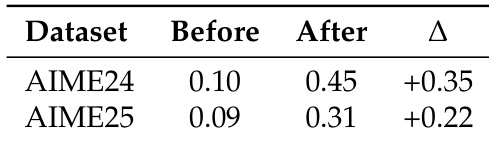
- It features a hybrid optimization pipeline with the Agent Practice module, which improves performance via in-context experience accumulation using only 100 samples and $18 cost, and the Agent RL module, which enables stable, scalable reinforcement learning with 40% speedup and 128-GPU support, boosting AIME 2024 accuracy from 10% to 45% on Qwen2.5-7B.
Introduction
The authors leverage the growing trend of LLM-based agents for real-world task automation, where the dual challenges of high configuration costs and static capabilities hinder scalable deployment. Prior frameworks rely on labor-intensive prompt engineering or costly fine-tuning, with limited adaptability and poor scalability. Youtu-Agent addresses these issues through a modular, YAML-driven architecture that separates environment, tools, and agent logic, enabling automated generation of both agent configurations and executable tool code. It introduces two generation modes—Workflow for deterministic tasks and Meta-Agent for dynamic scenarios—alongside a hybrid optimization system: the Agent Practice module enables low-cost, gradient-free self-improvement via parallel rollouts and experience sharing, while the Agent RL module supports stable, scalable reinforcement learning with solutions to concurrency and entropy explosion. The framework achieves strong performance on benchmarks using only open-source models, demonstrating significant gains in task completion, accuracy, and training efficiency.
Dataset
- The dataset, named AgentGen-80, comprises 80 diverse task descriptions designed to evaluate automated agent generation, spanning from simple information retrieval to complex multi-step automation.
- It is curated specifically for this study, as no established benchmarks existed for the task, and includes a balanced mix of task types to ensure comprehensive evaluation.
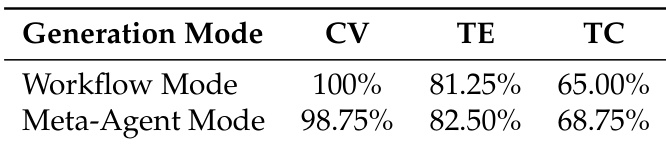
- The evaluation focuses on three key dimensions: Configuration Validity (CV), assessing whether the generated YAML configuration is structurally correct and semantically complete; Tool Executability (TE), measuring whether synthesized tools compile and run as expected; and Task Completion (TC), testing end-to-end success in achieving the specified task.
- The dataset is used entirely for evaluation, with no training data drawn from it; it serves as a standardized testbed to measure model performance across the three quality dimensions.
- No cropping or metadata construction is applied—each task description is used in its original form, with evaluation conducted on the full output of the agent generation pipeline.
Method
The Youtu-Agent framework is structured around a modular architecture designed to decouple execution components and enable automated generation and continuous optimization of large language model (LLM) agents. The core execution framework consists of three hierarchical layers: the Environment Layer, the Tools Layer, and the Agent Layer. The Environment Layer provides the foundational execution context, abstracting low-level capabilities such as browser navigation, command execution, or sandboxed code environments. This abstraction allows tools and agents to operate across different backends with minimal modification. The Tools Layer encapsulates atomic and composite operations, categorized into environment-related tools, environment-independent utilities, and Model Context Protocol (MCP) tools for external service integration. The Agent Layer houses the LLM-driven planner/executor, which operates through a perceive–reason–act loop. To manage long-horizon interactions and control context window size, a Context Manager module is integrated within this layer, pruning stale information while preserving essential task history.

The framework is supported by a YAML-based structured configuration system that declaratively specifies all components, including environment, tools, agent instructions, and context management settings. This standardized format facilitates both manual composition and automated synthesis. The automated generation mechanism leverages this configuration system to produce complete agent configurations from high-level task descriptions, employing two distinct paradigms. The Workflow mode follows a deterministic four-stage pipeline: Intent Clarification and Decomposition, Tool Retrieval and Ad-hoc Tool Synthesis, Prompt Engineering, and Configuration Assembly. This pipeline enables rapid development for well-defined, routine tasks. For more complex or ambiguous requirements, the Meta-Agent mode deploys a higher-level Architect Agent that dynamically plans the generation process. This meta-agent utilizes a set of callable tools—search_tool, create_tool, ask_user, and create_agent_config—to conduct multi-turn clarification, retrieve or synthesize tools, and assemble the final configuration.

Beyond execution, the framework emphasizes continuous agent improvement through two primary optimization components. The Agent Practice module enables low-cost, experience-based improvement without parameter updates. It integrates Training-free Group Relative Policy Optimization (Training-free GRPO), which operates by performing multiple rollouts on a small dataset to generate diverse solution trajectories. An LLM evaluator assesses the relative quality of these trajectories, distilling a semantic group advantage from contrasting successful and failed trials. This experiential knowledge is then injected into the agent's context during online testing as a form of "textual LoRA," guiding reasoning without modifying model weights. The Agent RL module provides a complete pipeline for end-to-end reinforcement learning, supporting scalable and stable training. This module integrates with modern RL frameworks via a custom connector, addressing scalability through RESTful API wrapping, Ray-based concurrency, and hierarchical timeout logic. Stability is ensured by filtering invalid tool calls, reducing off-policy updates, and correcting advantage estimation bias.

The end-to-end RL training pipeline is structured into three main components: the RL Framework, the Connector, and the Agent Framework. The RL Framework handles data loading, rollout generation, loss computation, and policy updates. The Connector acts as a bridge, translating between the RL framework and the Youtu-Agent execution environment. It includes an LLM Proxy, Bridging Protocols, and a Data Store, enabling seamless communication and data exchange. The Agent Framework, which includes the Youtu-Agent core, manages the agent's lifecycle, from initialization to execution and reward computation. This modular design allows for efficient integration and scalable training of agents across distributed systems.
Experiment
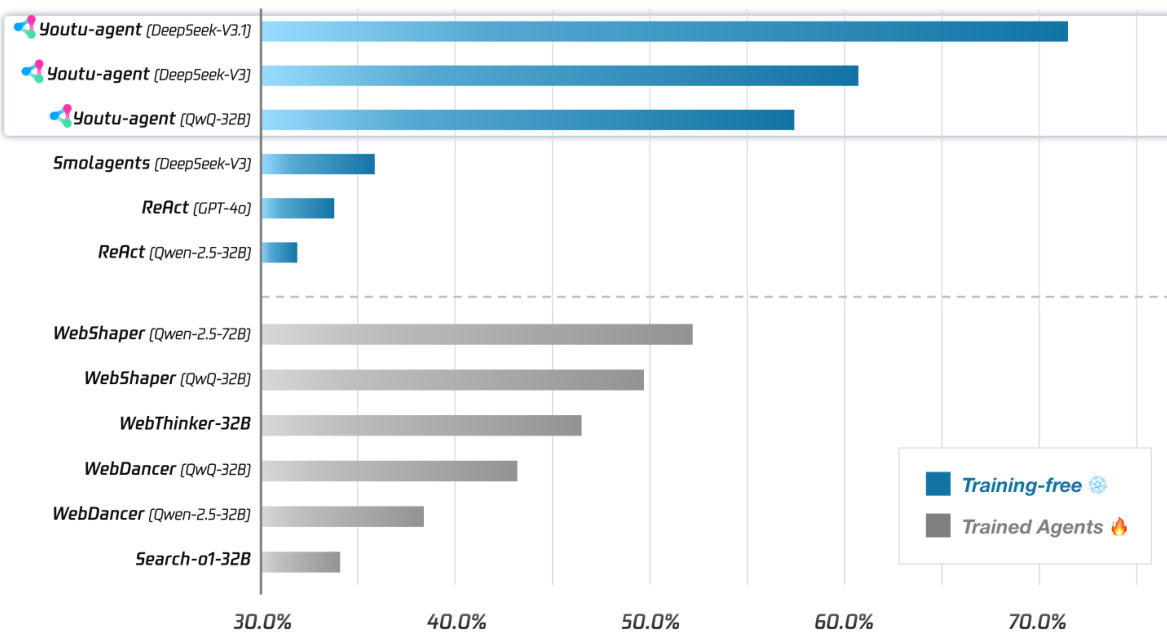
- Framework Efficiency: Achieved 71.47% pass@1 on WebWalkerQA and 72.8% pass@1 on GAIA (text-only subset) using only open-source models, establishing a strong open-source baseline for general agent capabilities.
- Automated Agent Generation: The Workflow and Meta-Agent modes achieved 100% and 98.75% configuration validity, respectively, with 81.25%–82.50% tool executability and 65.00%–68.75% task completion, demonstrating effective automated tool and agent configuration synthesis.
- Continuous Experience Learning: Training-free GRPO in the Agent Practice module improved performance by +2.7% on AIME 2024 and +5.4% on AIME 2025 with only 100 training examples and zero gradient updates, achieving comparable results to expensive RL methods at a fraction of the cost.
- Scalable and Stable Agent RL: The Agent RL module reduced training iteration time by 40% and improved Qwen2.5-7B accuracy on AIME 2024 from 10% to 45%, with consistent gains across math/code and search tasks, validating enhanced scalability and stability in large-scale RL training.
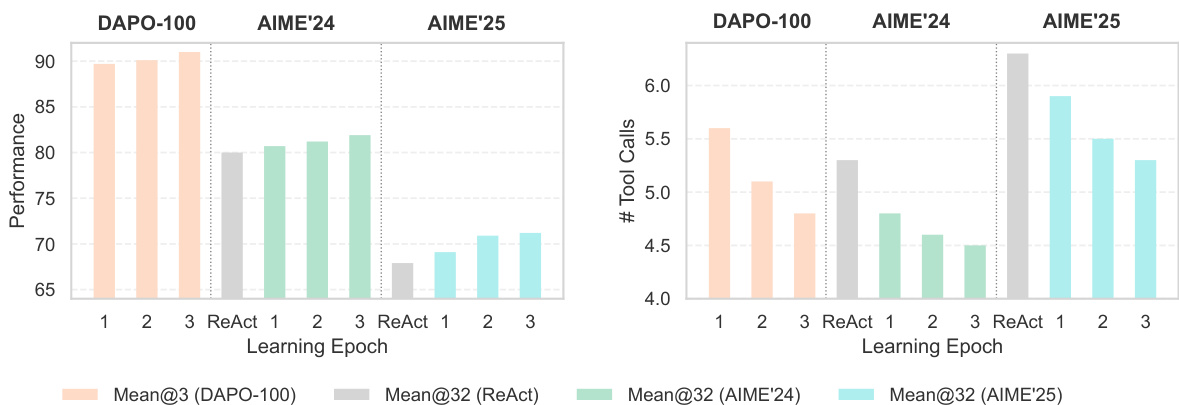
The authors use a training-free approach to improve agent performance on mathematical reasoning benchmarks, achieving +2.7% and +5.4% absolute improvements on AIME 2024 and AIME 2025 respectively, with no parameter updates and only 100 training examples. This demonstrates that experience accumulation through in-context learning can effectively enhance agent capabilities at low cost.
The authors evaluate the effectiveness of their Training-Free GRPO method on AIME 2024 and AIME 2025 benchmarks, showing that it achieves 80.7% and 68.9% accuracy respectively when trained without ground truths, and 82.7% and 73.3% when trained with ground truths, outperforming the ReAct baseline. These results demonstrate that the method enables significant performance improvements with minimal learning cost and no parameter updates.
The authors use the Agent Practice module to improve agent performance on mathematical reasoning benchmarks, achieving a +0.35 absolute improvement on AIME 2024 and a +0.22 improvement on AIME 2025. Results show that the training-free GRPO method enables effective learning through experience accumulation without parameter updates, leading to significant gains in accuracy.
Results show that the Training-free GRPO method achieves consistent performance improvements across learning epochs on AIME 2024 and AIME 2025, with Mean@32 accuracy increasing from epoch 1 to 3. The number of tool calls decreases over epochs, indicating that the agent learns more efficient problem-solving strategies without parameter updates.
The authors compare two automated generation modes in Youtu-Agent, showing that the Meta-Agent mode achieves slightly higher task completion rates (68.75% vs. 65.00%) while maintaining comparable tool executability and configuration validity. Results indicate that both modes are effective, with the Meta-Agent mode demonstrating marginally better end-to-end performance.