Command Palette
Search for a command to run...
LiveTalk: 개선된 온폴리시 디스틸레이션을 통한 실시간 다중모달 상호작용 영상 디퓨전
LiveTalk: 개선된 온폴리시 디스틸레이션을 통한 실시간 다중모달 상호작용 영상 디퓨전
Ethan Chern Zhulin Hu Bohao Tang Jiadi Su Steffi Chern Zhijie Deng Pengfei Liu
초록
디퓨전을 통한 실시간 비디오 생성은 일반 목적의 다중모달 상호작용 AI 시스템을 구축하는 데 필수적이다. 그러나 디퓨전 모델에서 반복적 과정을 통해 모든 비디오 프레임을 양방향 어텐션을 이용해 동시에 노이즈 제거하는 방식은 실시간 상호작용을 방해한다. 기존의 정교화(다이스틸레이션) 기법은 모델을 순차적(autoregressive)으로 만들고 추출 단계를 줄여 이 문제를 완화할 수 있으나, 주로 텍스트-비디오 생성에 초점이 맞춰져 있어 인간-AI 상호작용이 자연스럽지 않으며 효율성도 떨어진다. 본 논문은 텍스트, 이미지, 오디오를 포함한 다중모달 컨텍스트를 기반으로 실시간 상호작용 가능한 비디오 디퓨전을 목표로 하여 이 격차를 메우고자 한다. 특히, 최상위의 온폴리시(On-policy) 정교화 기법인 Self Forcing이 다중모달 조건부 입력에서 시각적 아티팩트(예: 깜빡임, 검은 프레임, 품질 저하)와 같은 문제를 겪는다는 관찰을 바탕으로, 온폴리시 최적화를 위한 조건 입력의 품질, 초기화 및 스케줄링에 중점을 둔 개선된 정교화 방식을 제안한다. HDTF, AVSpeech, CelebV-HQ 등 다중모달 조건부(오디오, 이미지, 텍스트) 아바타 비디오 생성을 위한 벤치마크에서, 제안한 정교화 모델은 유사하거나 더 큰 크기의 전단계 양방향 기준 모델과 비슷한 시각적 품질을 달성하면서도 추론 비용과 지연 시간을 20배 줄였다. 더 나아가, 오디오 언어 모델과 장기형 비디오 추론 기술인 Anchor-Heavy Identity Sinks를 통합하여 실시간 다중모달 상호작용 아바타 시스템인 LiveTalk을 구축하였다. 자체적으로 구성한 다단계 상호작용 벤치마크에서 시스템 수준 평가 결과, LiveTalk은 최첨단 모델(Sora2, Veo3)보다 다단계 비디오 일관성과 콘텐츠 품질에서 우수하며, 응답 지연 시간을 1~2분에서 실시간 생성 수준으로 단축시켜 인간-AI 간 자연스럽고 원활한 다중모달 상호작용을 가능하게 한다.
One-sentence Summary
The authors, affiliated with SII, SJTU, and GAIR, propose a distilled multimodal diffusion model enabling real-time interactive video generation conditioned on text, image, and audio, achieving 20× faster inference than bidirectional baselines while maintaining high visual quality through improved on-policy distillation with better input conditioning and optimization scheduling; integrated into LiveTalk, the system enables seamless, low-latency, multi-turn human-AI interaction with superior coherence and content quality compared to Sora2 and Veo3.
Key Contributions
-
The paper addresses the challenge of real-time interactive video generation by enabling multimodal-conditioned diffusion models (text, image, audio) to operate efficiently in autoregressive mode, overcoming the high latency of bidirectional, many-step diffusion models that hinder real-time human-AI interaction.
-
It introduces an improved distillation framework that stabilizes on-policy training under complex multimodal conditions through refined input conditioning, converged ODE initialization, and an aggressive optimization schedule, significantly reducing visual artifacts like flickering and black frames while preserving high-fidelity output.
-
Evaluated on HDTF, AVSpeech, and CelebV-HQ benchmarks, the distilled model achieves 20× faster inference and sub-second latency compared to bidirectional baselines, and when integrated into the LiveTalk system with Anchor-Heavy Identity Sinks, it enables real-time, long-form, coherent multi-turn avatar interactions outperforming Sora2 and Veo3 in both quality and responsiveness.
Introduction
Real-time multimodal interactive video generation is critical for building natural, responsive AI avatars capable of engaging in dynamic conversations using text, image, and audio inputs. However, standard diffusion models rely on computationally expensive, bidirectional denoising across all frames, leading to latencies of 1–2 minutes—prohibitive for real-time interaction. While prior distillation methods enable faster autoregressive generation, they primarily target text-to-video and struggle with multimodal conditioning, resulting in visual artifacts like flickering and degraded quality. The authors address this by introducing an improved on-policy distillation framework that stabilizes training under complex multimodal conditions through three key enhancements: high-quality, motion-focused multimodal conditioning; converged ODE initialization before on-policy training; and aggressive optimization schedules with tuned classifier guidance. Their distilled model achieves 20× faster inference with sub-second latency while matching or exceeding the visual quality of larger, bidirectional baselines. Building on this, they develop LiveTalk, a real-time interactive avatar system that integrates audio language models and a novel Anchor-Heavy Identity Sinks technique to maintain long-term visual consistency. System evaluations show LiveTalk outperforms Sora2 and Veo3 in multi-turn coherence, content quality, and response latency, enabling seamless, human-like multimodal interaction.
Dataset
- The dataset is composed of nine distinct evaluation dimensions designed to assess visual interaction performance and interaction content quality in multimodal models.
- Each dimension is evaluated using structured prompts tailored to specific scoring criteria, enabling consistent and measurable assessment across tasks.
- The evaluation framework is implemented through a multi-round protocol, where a Vision-Language Model (VLM) processes each prompt and generates responses for scoring.
- The dataset supports both qualitative and quantitative analysis, with detailed implementation guidelines provided for reproducibility.
- The data is used in the model training and evaluation pipeline to refine interaction capabilities, with mixture ratios and split configurations optimized for balanced representation across dimensions.
- No explicit cropping or metadata construction is applied; instead, the focus is on prompt engineering and response alignment to ensure high-fidelity assessment of interaction dynamics.
Method
The authors leverage a two-stage distillation framework to transform a bidirectional, many-step diffusion model into a causal, few-step autoregressive (AR) model suitable for real-time video generation. The overall architecture, as illustrated in the figure below, integrates a distilled video diffusion model with a large language model to form a complete real-time multimodal interactive system. The core of the method involves an ODE initialization stage followed by on-policy distillation using distribution matching distillation (DMD).

During ODE initialization, the student model is trained to predict the clean latent frames x0 from a few sampled timesteps of the teacher's denoising trajectory. This is achieved by minimizing the trajectory distillation loss, which encourages the student to match the teacher's output at specific time steps. The student model is designed to generate video in a block-wise manner, where each block consists of multiple latent frames, enabling efficient streaming. The architecture supports causal attention and key-value (KV) cache for autoregressive generation, allowing the model to maintain visual consistency across blocks by prefiling clean KV cache from previous blocks.
Following ODE initialization, the model undergoes on-policy distillation with DMD to mitigate exposure bias. This stage involves a generator gϕ and a trainable critic sψ, with a frozen teacher score network sθ. The critic learns to track the generator's evolving distribution by minimizing a denoising objective, while the generator is updated to align its output with the teacher's score. The gradient update for the generator incorporates the difference between the teacher and critic scores, ensuring the generator learns to produce outputs that match the teacher's distribution. This process is conducted using self-generated rollouts, where the model generates sequences that are then used for training.
The system further incorporates several improvements to enhance the distillation process. Multimodal conditions are refined to provide high-quality training signals, with specific curation strategies applied to image and text inputs based on dataset characteristics. ODE initialization is trained to convergence to establish a robust starting point, and an aggressive learning rate schedule is employed during DMD to maximize learning within the limited effective window. These enhancements ensure strong audio-visual alignment and high visual quality in the generated videos.
The distilled model is integrated into a real-time interactive system, where it functions as the performer module, rendering synchronized talking avatars. The system uses overlapped windowing for audio conditioning to provide rich acoustic context while maintaining real-time responsiveness. To preserve speaker identity over long video streams, a training-free method called Anchor-Heavy Identity Sinks (AHIS) is employed, which allocates a portion of the KV cache as identity anchors to store high-fidelity early frames. Additionally, pipeline parallelism is used to execute diffusion denoising and VAE decoding in parallel, reducing per-block latency and enabling non-stalling streaming.
Experiment
- Identified three key issues in existing distillation recipes: data quality problems due to low-quality reference images, insufficient ODE initialization leading to unstable training, and a limited learning window causing premature degradation in multimodal video diffusion distillation.
- Proposed and validated four improvements: curated high-quality multimodal conditions, converged ODE initialization (20k steps), aggressive learning rate scheduling, and tuned teacher score CFG guidance, which collectively eliminate visual degradation and improve stability.
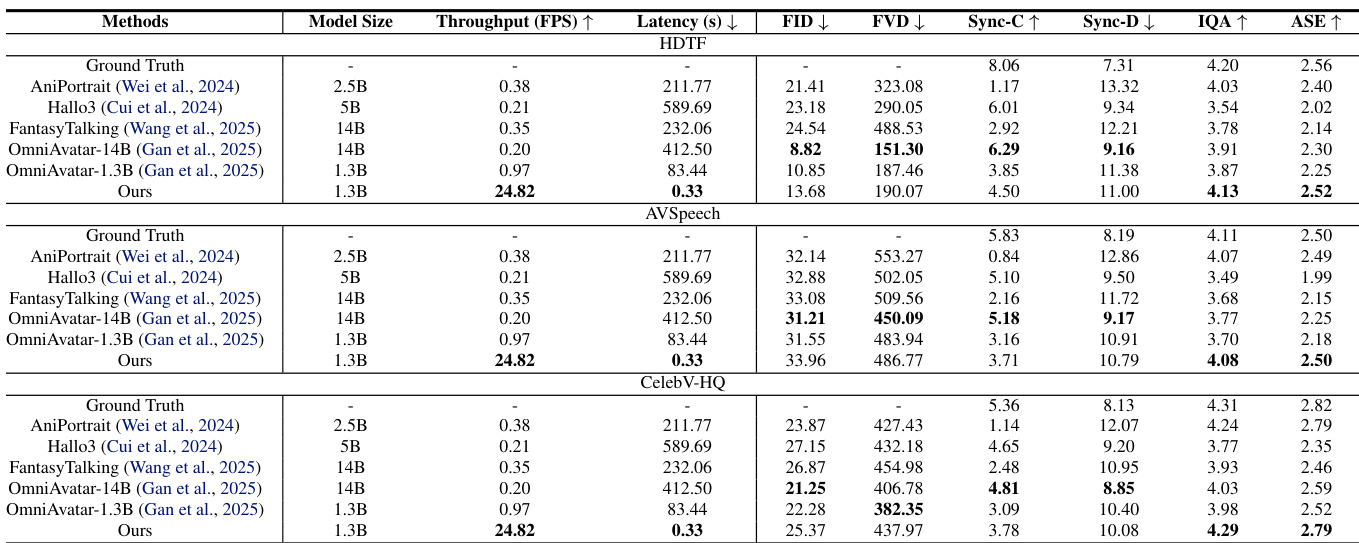
- On the HDTF, AVSpeech, and CelebV-HQ benchmarks, the distilled model achieves comparable or superior visual quality (FID, FVD, IQA, ASE), lip-sync accuracy (Sync-C/D), and conversational coherence to larger bidirectional models (e.g., OmniAvatar-1.3B, 14B), while delivering 25× higher throughput (24.82 FPS vs. 0.97 FPS) and 250× faster first-frame latency (0.33s vs. 83.44s).
- In multi-round interaction evaluation using a VLM-based benchmark, the model outperforms Veo3 and Sora2 in multi-video coherence and content quality, demonstrating superior temporal consistency and contextual awareness through AR generation with KV cache and Qwen3-Omni memory mechanisms.
- Ablation studies confirm that each proposed component contributes incrementally to performance, with curated data and converged ODE initialization being essential for stable and high-quality distillation.
The authors conduct an ablation study to evaluate the impact of four key improvements on distillation quality, showing that each component contributes incrementally to performance. The final configuration achieves the best results across all metrics, with the most significant improvements in FID, FVD, Sync-C, and Sync-D, while the absence of curated multimodal conditions leads to a substantial drop in quality, highlighting the critical role of data quality.

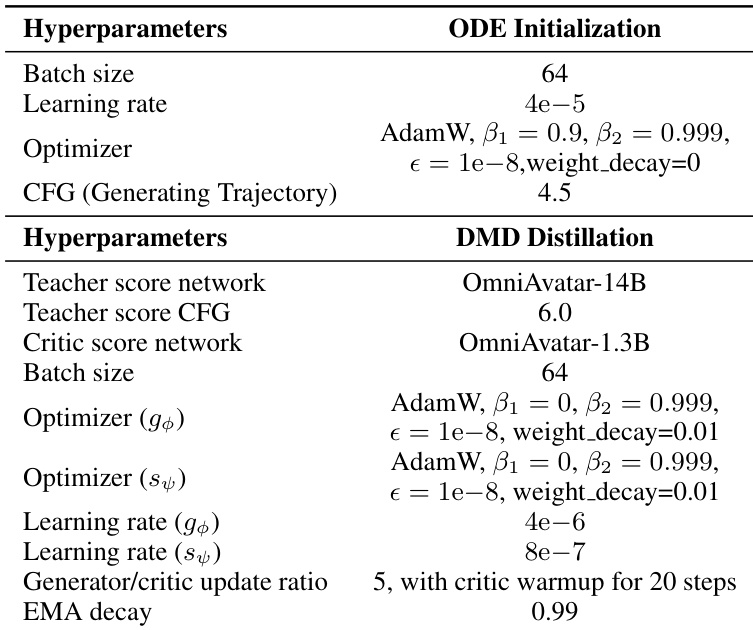
The authors use a two-stage distillation pipeline consisting of ODE initialization and DMD distillation, with distinct hyperparameters for each stage. Results show that the DMD distillation stage employs a 5:1 update ratio between the generator and critic networks, with the critic network updated for 20 steps before generator training begins, and uses an EMA decay of 0.99 from step 200 onward.
The authors evaluate their distilled model against baselines Veo3 and Sora2 on a multi-round interaction benchmark, showing that LiveTalk outperforms both in multi-video coherence and content quality metrics while maintaining competitive performance on other visual interaction dimensions. LiveTalk achieves this through AR generation with KV cache for visual memory and a Qwen3-Omni module for textual memory, enabling coherent multi-turn generation with significantly lower latency and higher throughput.

The authors use a distilled model to evaluate performance against several baselines on multimodal avatar generation benchmarks, achieving comparable or superior visual quality, aesthetics, and lip-sync accuracy to larger bidirectional models while significantly improving throughput and latency. Results show that the distilled model outperforms or matches the performance of models like OmniAvatar-1.3B and OmniAvatar-14B across in-domain and out-of-domain datasets, with a 25× speedup in throughput and over 250× faster first-frame latency.