Command Palette
Search for a command to run...
HY-Motion 1.0: 텍스트에서 모션 생성을 위한 플로우 매칭 모델의 스케일링
HY-Motion 1.0: 텍스트에서 모션 생성을 위한 플로우 매칭 모델의 스케일링
초록
우리는 텍스트 기반 설명으로 3차원 인간 동작을 생성할 수 있는 최첨단 대규모 동작 생성 모델인 HY-Motion 1.0을 소개한다. HY-Motion 1.0은 동작 생성 분야에서 Diffusion Transformer(DiT) 기반의 플로우 매칭 모델을 빌리언 파라미터 규모로 확장한 최초의 성공적인 시도로, 현재 공개된 벤치마크 대비 훨씬 뛰어난 지시어 따르기 능력을 제공한다. 특히, 본 연구는 대규모 사전 훈련(3,000시간 이상의 동작 데이터 기반), 정교한 데이터를 활용한 고품질 미세조정(400시간), 그리고 인간 피드백과 보상 모델을 기반으로 한 강화 학습을 포함하는 종합적이고 전 단계에 걸친 훈련 프레임워크를 제안한다. 이를 통해 텍스트 지시어와의 정확한 일치성과 높은 동작 품질을 보장한다. 이 프레임워크는 엄격한 동작 정제 및 캡션 생성을 수행하는 철저한 데이터 전처리 파이프라인에 의해 뒷받침된다. 결과적으로 본 모델은 6개 주요 클래스에 걸쳐 200개 이상의 동작 카테고리에 걸쳐 가장 광범위한 커버리지를 달성하였다. 본 연구는 향후 연구를 촉진하고 3차원 인간 동작 생성 모델의 상용화를 가속화하기 위해 HY-Motion 1.0을 오픈소스 커뮤니티에 공개한다.
One-sentence Summary
The Tencent Hunyuan 3D Digital Human Team presents HY-Motion 1.0, a billion-parameter DiT-based flow matching model that enables high-fidelity 3D motion generation from text via a full-stage training pipeline combining large-scale pretraining, curated fine-tuning, and reinforcement learning, achieving superior instruction alignment and coverage across 200+ motion categories, with open-source release to advance commercial adoption in digital human applications.
Key Contributions
- HY-Motion 1.0 is the first to scale a Diffusion Transformer (DiT)-based flow matching model to over one billion parameters for text-to-motion generation, achieving state-of-the-art instruction-following capabilities that significantly surpass existing open-source models.
- The model employs a comprehensive three-stage training paradigm—large-scale pretraining on 3,000+ hours of motion data, high-quality fine-tuning on 400 hours of curated text-motion pairs, and reinforcement learning from human feedback and reward models—to jointly optimize motion quality and semantic alignment.
- A meticulously designed data curation pipeline, combining automated cleaning with extensive manual refinement, produces a large-scale dataset with over 200 motion categories across six major classes, enabling the model to generate diverse, realistic, and instruction-accurate 3D human motions.
Introduction
The authors leverage diffusion models and flow matching to advance text-to-motion generation, a critical capability for creating realistic 3D human animations in applications like virtual reality, digital humans, and robotics. Prior work faced key limitations: small models lacked complexity and semantic understanding, while LLM-based approaches using discrete motion tokens suffered from motion quality degradation due to quantization. Additionally, the field lacked large-scale, high-quality datasets and effective scaling strategies for diffusion-based motion models. To address these challenges, the authors introduce HY-Motion 1.0, the first billion-parameter DiT-based flow matching model for text-to-motion generation. Their main contribution is a full-stage training paradigm combining large-scale pretraining on 3,000+ hours of diverse motion data, high-quality fine-tuning on 400 hours of meticulously curated text-motion pairs, and reinforcement learning with human and reward model feedback. This approach enables superior motion fidelity, naturalness, and instruction-following accuracy. They also release a new open-source dataset with over 200 motion categories, built via a hybrid automated and manual curation pipeline, setting a new benchmark for data quality and scale in the domain.
Dataset
- The dataset is composed of three primary sources: in-the-wild human motion videos (12 million clips from HunyuanVideo), motion capture data (~500 hours), and 3D animation assets from game production.
- The video data underwent shot boundary detection and human detection to isolate relevant clips, followed by 3D human motion reconstruction using GVHMR to extract SMPL-X parameters.
- All motion data was standardized to the SMPL-H skeleton (22 joints, no hands) through retargeting, with mesh fitting or skeletal mapping for non-SMPL-H formats.
- A comprehensive filtering pipeline removed duplicates, abnormal poses, joint velocity outliers, static motions, anomalous displacements, and artifacts like foot-sliding.
- Post-filtering, motions were canonicalized: resampled to 30 fps, split into clips under 12 seconds, and aligned to a canonical coordinate frame (Y-axis up, origin-centered, ground-aligned, facing positive Z-axis).
- The final dataset contains over 3,000 hours of motion data, including 400 hours of high-quality motion, with each motion represented as a sequence of 201-dimensional vectors (translation, global orientation, local rotations, and joint positions) using 6D rotation representation.
- A three-level hierarchical motion taxonomy organizes the data into six top-level categories—Locomotion, Sports & Athletics, Fitness & Outdoor Activities, Daily Activities, Social Interactions & Leisure, and Game Character Actions—expanding to over 200 fine-grained motion classes.
- The full dataset Dall is used in large-scale pretraining with a Flow Matching objective, leveraging both high-quality and noisy data to establish a broad semantic and kinematic prior.
- Text descriptions range from manual annotations to VLM-generated captions, supporting semantic generalization during pretraining.
- The model is trained with a constant learning rate to rapidly learn diverse motion patterns, resulting in a high-entropy, semantically rich initialization that captures general movement dynamics but includes artifacts due to noisy inputs.
- This pretraining stage serves as a foundation for subsequent fine-tuning, where motion quality is refined while preserving semantic fidelity.
Method
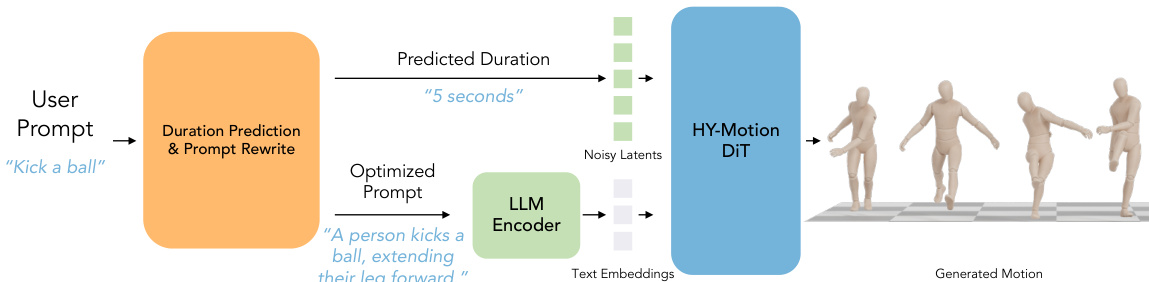
The authors leverage a hybrid Transformer architecture, termed HY-Motion DiT, as the core model for generating 3D human motions from text. The overall framework, illustrated in the diagram below, begins with a user prompt that is processed by a dedicated LLM module for duration prediction and prompt rewriting. This module outputs an optimized prompt and a predicted duration, which are then used to condition the HY-Motion DiT model. The model accepts noisy motion latents, the optimized text prompt, and a timestep as inputs, and generates a sequence of 3D human motion as output. The framework is supported by a comprehensive data processing pipeline that ensures high-quality training data.
The HY-Motion DiT model employs a hybrid architecture that combines dual-stream and single-stream processing to model the joint distribution of motion and text. The network starts with dual-stream blocks, where motion latents and text tokens are processed via independent QKV projections and MLPs. These streams interact through a joint attention mechanism, allowing motion features to query semantic cues from the text while preserving their distinct modality-specific representations. The streams subsequently merge in the single-stream blocks, where motion and text tokens are concatenated into a unified sequence. Here, parallel spatial and channel attention modules facilitate deep multimodal fusion and information exchange.
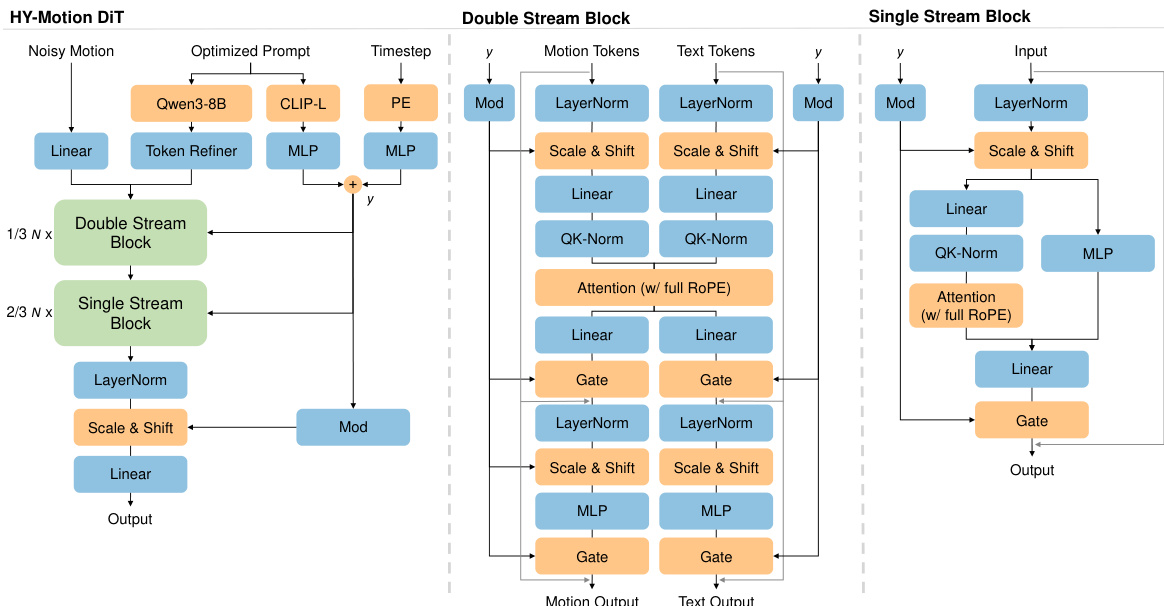
Text encoders utilize a hierarchical dual-conditioning strategy to integrate both fine-grained and global text guidance. The authors employ Qwen3-8B to extract rich, token-wise semantic embeddings. To address the limitation of causal attention in LLMs, they adopt a Bidirectional Token Refiner, which transforms the causal LLM features into bidirectional representations before injecting them into the dual-stream blocks. Complementarily, they use CLIP-L to extract a global text embedding, which is concatenated with the timestep embedding and injected via a separate AdaLN mechanism to adaptively regulate feature statistics throughout the network.
The attention mechanism incorporates specific masking strategies for both cross-modal interaction and temporal modeling. An asymmetric attention mask is enforced to regulate multimodal information flow: motion tokens attend globally to the text sequence to extract semantic cues, while text tokens are explicitly masked from the motion latents to prevent the diffusion noise from propagating back to the text embeddings. For temporal modeling within the motion branch, a narrow band mask strategy is implemented, restricting attention to a sliding window of 121 frames under 30 fps to impose a locality inductive bias. To spatially ground these attention interactions, the model uses full Rotary Positional Embeddings (RoPE), which are applied across a unified sequence of concatenated text and motion embeddings to establish a continuous relative coordinate system.
The training objective is based on Flow Matching, which constructs a continuous probability path between the standard Gaussian noise distribution and the complex motion data distribution. The authors adopt the optimal transport path, defined as a linear interpolation xt=(1−t)x0+tx1, which implies a constant target velocity. The training objective is to minimize the Mean Squared Error (MSE) between the predicted and ground-truth velocity:
LFM=Et,x0,x1[∣∣vθ(xt,c,t)−vt∣∣D2],where x1 represents the clean motion data, x0∼N(0,I) is the initial noise, and the target velocity is given by vt=x1−x0. During inference, the generation process is formulated as an Ordinary Differential Equation (ODE): dx/dt=vθ(xt,c,t). Starting from random noise x0, the model recovers the clean motion x1 by numerically integrating this ODE using an ODE solver.
Experiment
- High-Quality Fine-Tuning: Transitioning to the curated DHQ dataset with a reduced learning rate (ηfit=0.1×ηpre) refines motion quality and semantic precision without sacrificing diversity, significantly reducing noise, jitter, and foot sliding while improving anatomical consistency and fine-grained instruction adherence.
- State-of-the-Art Comparison: On a test set of 2000+ prompts across six motion categories, HY-Motion 1.0 outperforms DART, LoM, GoToZero, and MoMask in both instruction-following capability and motion quality, achieving higher human ratings and superior SSAE scores via video-VLM-based evaluation.
- Scaling Experiments: Larger model sizes improve instruction-following capability, but motion quality saturates beyond 0.46B parameters; the 3,000-hour pretraining dataset is critical for instruction accuracy, leading to the release of DiT-1B as the main model and DiT-0.46B as a lightweight variant.
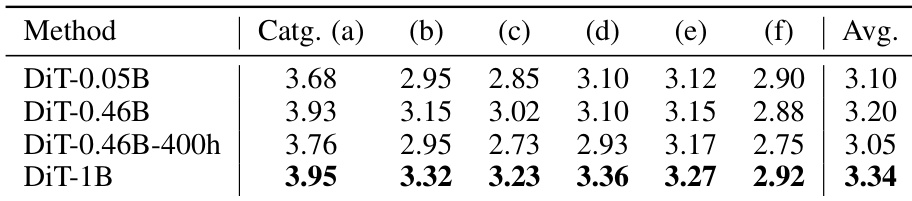
Results show that increasing model size improves instruction-following capability, with the DiT-1B model achieving the highest average score. However, motion quality plateaus beyond the 0.46B parameter size, as indicated by the consistent performance across categories in the table.
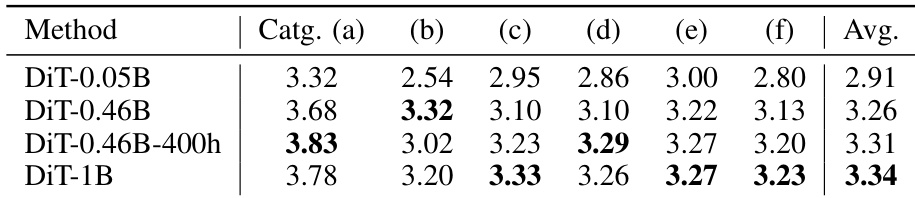
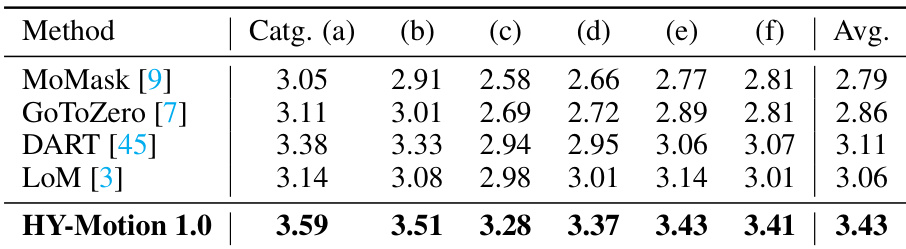
Results show that HY-Motion 1.0 outperforms all compared models in instruction-following capability across all motion categories, achieving the highest average score of 3.43. The model demonstrates superior alignment with textual prompts, particularly in distinguishing fine-grained actions, while maintaining strong performance across diverse motion types.
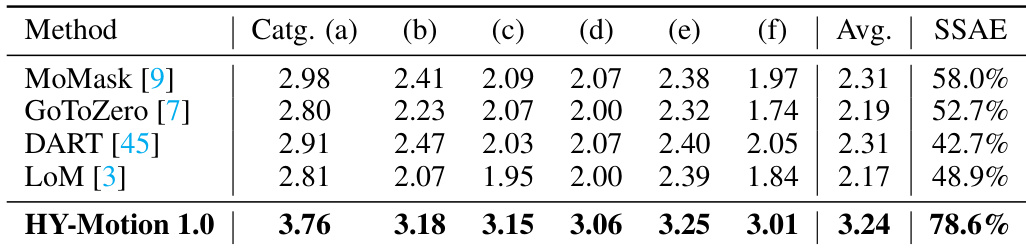
Results show that HY-Motion 1.0 significantly outperforms existing models in instruction-following capability across all motion categories, achieving the highest average score of 3.24 compared to 2.17–2.31 for other methods. The model also achieves the best SSAE score of 78.6%, indicating superior alignment between generated motions and textual instructions.
Results show that increasing model size improves instruction-following capability, with the DiT-1B model achieving the highest average score across all motion categories. The DiT-0.46B-400h model, trained on a smaller dataset, underperforms compared to models trained on the larger 3,000-hour dataset, indicating that data volume significantly impacts instruction-following ability.