Command Palette
Search for a command to run...
SpotEdit: 확산 트랜스포머에서의 선택적 영역 편집
SpotEdit: 확산 트랜스포머에서의 선택적 영역 편집
Zhibin Qin Zhenxiong Tan Zeqing Wang Songhua Liu Xinchao Wang
초록
디퓨전 트랜스포머 모델은 조건 이미지를 인코딩하고 이를 트랜스포머 레이어에 통합함으로써 이미지 편집 기술을 크게 발전시켜왔다. 그러나 대부분의 편집 작업은 소규모 영역만을 수정하는 데 그치며, 기존의 방법들은 모든 타임스텝에서 모든 토큰에 대해 동일하게 처리 및 노이즈 제거를 수행하기 때문에 불필요한 계산이 발생할 뿐만 아니라, 수정되지 않은 영역의 품질이 저하될 위험이 있다. 이에 따라 핵심적인 질문이 제기된다. 편집 과정에서 모든 영역을 다시 생성하는 것이 진정으로 필수적인가? 이를 해결하기 위해, 우리는 수정된 영역만을 선택적으로 업데이트하는 훈련이 필요 없는 디퓨전 편집 프레임워크인 SpotEdit을 제안한다. SpotEdit는 두 가지 핵심 구성 요소로 구성된다. SpotSelector는 인지적 유사성 기반으로 안정된 영역을 식별하고, 조건 이미지의 특징을 재사용함으로써 해당 영역의 계산을 생략한다. SpotFusion은 동적 융합 메커니즘을 통해 수정된 토큰과 조건 이미지의 특징을 적응적으로 혼합함으로써, 맥락의 일관성과 편집 품질을 유지한다. 불필요한 계산을 줄이고 수정되지 않은 영역의 높은 정밀도를 유지함으로써, SpotEdit는 효율적이고 정밀한 이미지 편집을 달성한다.
One-sentence Summary
The authors from the National University of Singapore and Shanghai Jiao Tong University propose SpotEdit, a diffusion transformer-based method for selective region editing that enables precise image manipulation by isolating and regenerating specific areas, outperforming prior approaches through a novel attention-guided masking mechanism that preserves global coherence while allowing fine-grained control.
Key Contributions
- Most image editing tasks require modifying only small regions, yet existing diffusion-based methods uniformly denoise the entire image, leading to redundant computation and potential artifacts in unchanged areas.
- SpotEdit introduces SpotSelector, which dynamically identifies stable, non-edited regions using perceptual similarity between reconstructed and condition image latents, eliminating the need for manual masks.
- SpotFusion adaptively fuses condition image features with edited tokens to maintain contextual coherence, achieving up to 1.9× speedup on PIE-Bench++ while preserving high edit quality and fidelity.
Introduction
Diffusion Transformer (DiT) models have enabled powerful, mask-free image editing by integrating condition images directly into transformer layers, allowing flexible semantic modifications. However, existing methods uniformly denoise every region at each timestep, even when only small areas require editing—leading to wasted computation and potential artifacts in unchanged regions. This inefficiency stems from a lack of region-aware processing, despite the fact that non-edited areas often stabilize early in the diffusion process. The authors propose SpotEdit, a training-free framework that selectively edits only modified regions. It introduces SpotSelector, which dynamically identifies stable regions using perceptual similarity between reconstructed and condition image latents, and SpotFusion, a context-aware mechanism that blends reference features adaptively to preserve coherence. By skipping computation on unmodified areas and focusing resources on edits, SpotEdit achieves up to 1.9× speedup on benchmark datasets while maintaining high visual fidelity and eliminating the need for manual masks.
Method
The authors leverage the Rectified Flow framework, which simplifies generative modeling by assuming a linear interpolation between the source and target distributions. This formulation enables a deterministic flow defined by an ordinary differential equation, where the velocity field vθ(Xt,C,t) governs the transformation from initial noise X1 to the final image X0. During inference, the model integrates this equation backward in time, guided by a condition C that includes the reference image and the editing instruction. The core of the proposed SpotEdit framework is a two-part mechanism designed to efficiently skip redundant computation on non-edited regions while preserving high-fidelity background details.

The overall process, as illustrated in the framework diagram, consists of three stages. In the initial steps, the model performs standard DiT denoising on all image tokens under the editing instruction, while caching the Key-Value (KV) values for subsequent use. This is followed by the Spot Steps, where the SpotSelector dynamically identifies regenerated and non-edited region tokens using a perceptual score. Non-edited region tokens are skipped from DiT computation, while regenerated region tokens are generated iteratively with SpotFusion. SpotFusion builds a temporally consistent condition cache by fusing cached non-edited region KV values with condition image KV values. The final stage is Token Replacement, where regenerated tokens are updated through DiT, and non-edited tokens are directly covered by the corresponding reused tokens before decoding into an image, ensuring background fidelity with reduced computation.

The SpotSelector module addresses the challenge of identifying which tokens require modification. It leverages the property of Rectified Flow that allows for a closed-form reconstruction of the fully denoised latent state X^0 at any timestep ti. By comparing this early reconstruction with the condition image latent Y, the module can determine which regions have stabilized. To obtain a similarity measure that aligns with human perception, it introduces a token-level perceptual score inspired by LPIPS, computed from VAE decoder activations. This score, defined as sLPIPS(i)=∑l∈Lwlϕ^l(X^0)i−ϕ^l(Y)i22, maps differences in early decoder features to a token-wise perceptual discrepancy. Using a threshold τ, the module defines a binary routing indicator rt,i to classify tokens into a regenerated set At and a non-edited set Rt. Tokens in Rt are removed from the DiT computation, while tokens in At proceed with the full denoising update.
The SpotFusion module tackles the problem of contextual degradation that arises when non-edited tokens are removed from the computation. It proposes a temporally consistent feature-reuse mechanism that blends cached non-edited features with reference-image features. The module first caches the KV pairs of both the reference branch and the non-edited region tokens. To avoid temporal mismatch with the evolving regenerated tokens, SpotFusion smoothly interpolates the cached features toward the reference features at every block and timestep. The updated hidden state for non-edited tokens is given by h~x(b,t)=α(t)h~x(b,t+1)+(1−α(t))hy(b), where α(t)=cos2(2πt). This interpolation is applied directly to the KV pairs, ensuring that the contextual signals for regenerated tokens remain coherent and temporally consistent.
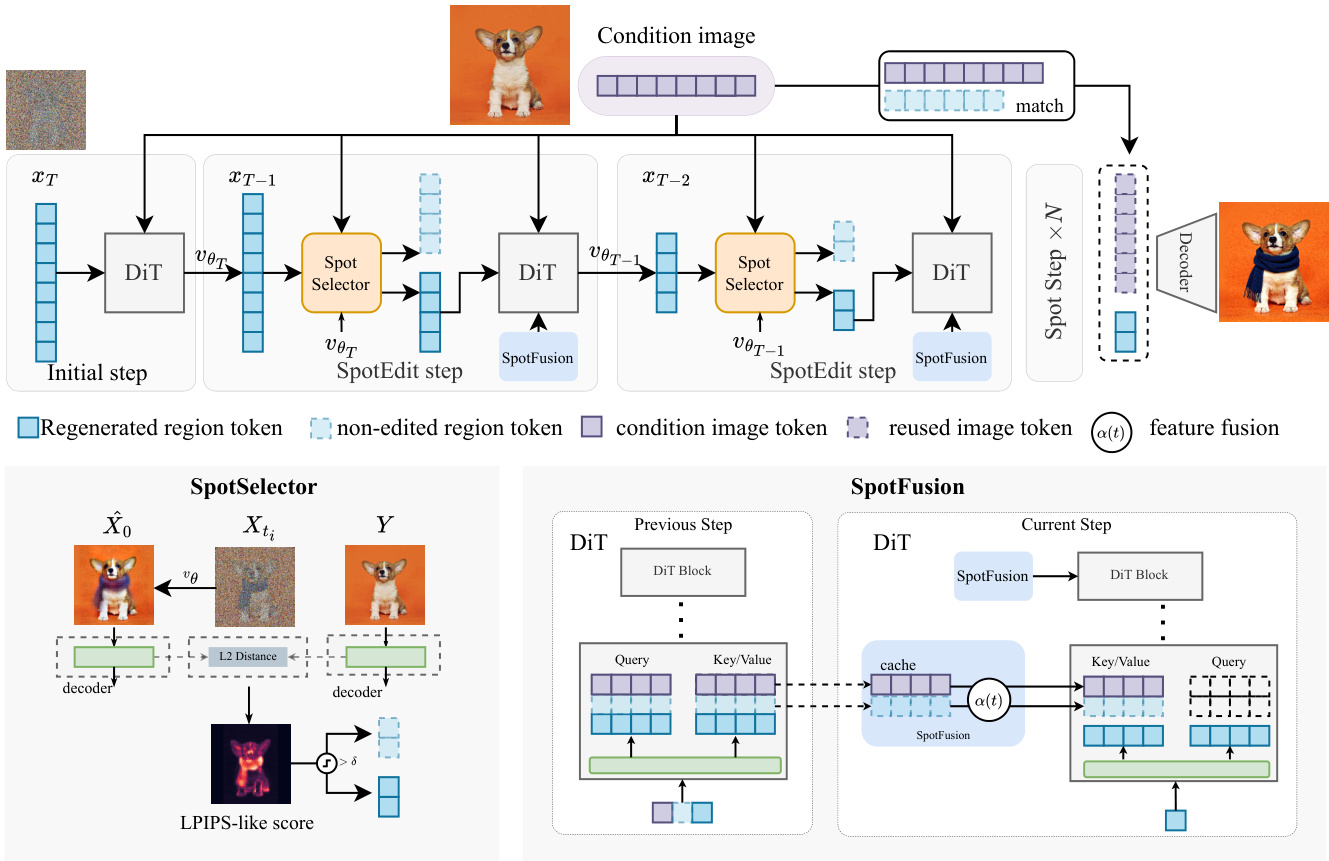
The authors analyze the temporal behavior of hidden states in non-edited regions, observing that the trajectories of non-edited tokens and condition image tokens converge to the same latent subspace as denoising proceeds. This convergence suggests that non-edited regions evolve smoothly toward the condition image, admitting a consistent feature representation that can be gradually reinforced. This insight motivates the SpotFusion design, which avoids the temporal drift and context mismatch associated with static KV caching. The framework further employs a partial attention calculation, where only the regenerated tokens and instruction-prompt tokens are active queries. The full Key-Value set is constructed by concatenating the active queries with the cached features from the non-edited and condition image regions, allowing the DiT to perform attention using a small set of queries while retaining full spatial context.
Experiment
- SpotEdit validates its effectiveness in balancing editing fidelity and computational efficiency through experiments on imgEdit-Benchmark and PIE-Bench++. On imgEdit-Benchmark, it achieves a 1.67× speedup while matching original inference quality, and on PIE-Bench++, it attains 1.95× speedup with 18.73 PSNR and 0.792 SSIMc, outperforming all baselines in quality.
- SpotEdit achieves the highest VL score (3.77) on imgEdit-Benchmark, excelling in complex tasks like Replace (4.41) and Compose (2.65), with only a minor drop (-0.14) from original inference, demonstrating strong semantic alignment and structural consistency.
- Ablation studies confirm the necessity of Token Fusion (adaptive blending), Condition Cache (caching both condition and unedited features), and Reset mechanism (periodic refresh to prevent error accumulation), with each component significantly improving fidelity and stability.
- When applied to Qwen-Image-Edit, SpotEdit maintains near-perfect background fidelity (+0.01 PSNR, -0.01 DISTS on imgEdit) and improves performance on PIE-Bench++ (+1.08 PSNR, +0.03 SSIMc) while achieving 1.72× acceleration.
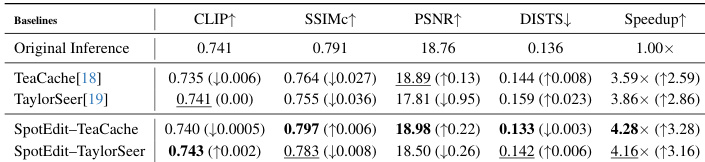
- Integration with cache-based methods like TeaCache and TaylorSeer remains stable and further enhances efficiency without degrading quality, confirming compatibility and robustness.
Results show that SpotEdit achieves a favorable trade-off between editing quality and computational efficiency, matching or slightly surpassing original inference results on the imgEdit-Benchmark while achieving a 1.67× speedup. On PIE-Bench++, SpotEdit maintains high structural consistency with 18.73 PSNR and 0.792 SSIMc, outperforming all baselines in quality while still reaching a 1.95× speedup.

The authors use a reset mechanism to maintain numerical stability during denoising, and results show that disabling it increases speedup to 2.25× but reduces PSNR by 1.6 dB and increases DISTS by 0.018, indicating that periodic reset is essential for preserving edit quality.

Results show that SpotEdit achieves a 4.28× speedup on the imgEdit-Benchmark while maintaining high editing quality, with CLIP and SSIM scores close to the original inference. The method outperforms cache-based baselines like TeaCache and TaylorSeer in both speed and quality, demonstrating effective computation allocation to edited regions.
Results show that removing the condition cache in SpotEdit leads to a significant drop in speedup from 1.95× to 1.24×, while slightly improving PSNR from 18.73 to 19.15. This indicates that caching the condition image is crucial for efficiency without substantially compromising visual quality.

Results show that SpotEdit achieves the highest average VL score of 3.77 on the imgEdit-Benchmark, outperforming all baselines across most editing tasks while maintaining strong performance on complex instructions like Replace and Compose. The method preserves non-edited regions effectively, as evidenced by its superior background fidelity and minimal deviation from original inference, while also achieving a 1.67× speedup in inference.
