Command Palette
Search for a command to run...
LongFly: 시공간적 맥락 통합을 통한 장기 예측 UAV 시각-언어 탐색
LongFly: 시공간적 맥락 통합을 통한 장기 예측 UAV 시각-언어 탐색
Wen Jiang Li Wang Kangyao Huang Wei Fan Jinyuan Liu Shaoyu Liu Hongwei Duan Bin Xu Xiangyang Ji
초록
무인 항공기(UAV)는 재해 후 수색 구조 작업에서 핵심적인 도구로, 특히 장기 시점 탐색 환경에서 높은 정보 밀도, 빠른 시점 변화, 동적 구조 등 다양한 도전 과제에 직면해 있다. 그러나 기존의 UAV 시각-언어 탐색(VLN) 기법은 복잡한 환경에서 장기 시점 공간-시간적 맥락을 효과적으로 모델링하지 못해 의미적 정렬의 정확도 저하와 불안정한 경로 계획 문제를 겪고 있다. 이를 해결하기 위해 본 연구에서는 장기 시점 UAV VLN를 위한 공간-시간 맥락 모델링 프레임워크인 LongFly를 제안한다. LongFly는 과거 정보를 인지하는 공간-시간 모델링 전략을 도입하여, 분절되고 중복되는 과거 데이터를 구조화되고 컴팩트하며 표현력 있는 형태로 변환한다. 먼저, 슬롯 기반의 과거 이미지 압축 모듈을 제안하여, 다중 시점의 과거 관측을 고정 길이의 맥락 표현으로 동적으로 정제한다. 이후, UAV의 경로 시계열 특성과 공간 구조를 포착하기 위해 공간-시간 경로 인코딩 모듈을 도입한다. 마지막으로, 기존의 공간-시간 맥락 정보와 현재 관측을 효과적으로 통합하기 위해, 프롬프트 유도 다모달 통합 모듈을 설계하여 시간 기반 추론과 강건한 웨이포인트 예측을 지원한다. 실험 결과, LongFly는 보이는 환경과 보이지 않은 환경을 가리지 않고, 최첨단 UAV VLN 기준 대비 성공률에서 7.89%, 경로 길이에 가중된 성공률에서 6.33% 향상시키며 일관된 우수한 성능을 입증하였다.
One-sentence Summary
The authors, affiliated with institutions in China including the National Natural Science Foundation of China, Chongqing Natural Science Foundation, and the National High Technology Research and Development Program, propose LongFly, a spatiotemporal context modeling framework for long-horizon UAV vision-and-language navigation that integrates history-aware visual compression, trajectory encoding, and prompt-guided multimodal fusion. By dynamically distilling multi-view historical observations into compact semantic slots and aligning them with language instructions through a structured prompt, LongFly enables robust, time-aware waypoint prediction in complex 3D environments, achieving 7.89% higher success rate and 6.33% better success weighted by path length than state-of-the-art methods across seen and unseen scenarios.
Key Contributions
-
LongFly addresses the challenge of long-horizon UAV vision-and-language navigation in complex, dynamic environments by introducing a unified spatiotemporal context modeling framework that enables stable, globally consistent decision-making despite rapid viewpoint changes and high information density.
-
The method features a slot-based historical image compression module that dynamically distills multi-view past observations into compact, fixed-length representations, and a spatiotemporal trajectory encoding module that captures both temporal dynamics and spatial structure of UAV flight paths.
-
Experimental results show LongFly achieves 7.89% higher success rate and 6.33% higher success weighted by path length than state-of-the-art baselines across both seen and unseen environments, demonstrating robust performance in long-horizon navigation tasks.
Introduction
The authors address long-horizon vision-and-language navigation (VLN) for unmanned aerial vehicles (UAVs), a critical capability for post-disaster search and rescue, environmental monitoring, and geospatial data collection in complex, GPS-denied environments. While prior UAV VLN methods have made progress in short-range tasks, they struggle with long-horizon navigation due to fragmented, static modeling of historical visual and trajectory data, leading to poor semantic alignment and unstable path planning. Existing approaches often treat history as isolated memory cues without integrating them into a unified spatiotemporal context aligned with language instructions and navigation dynamics. To overcome this, the authors propose LongFly, a spatiotemporal context modeling framework that dynamically compresses multi-view historical images into compact, instruction-relevant representations via a slot-based compression module, encodes trajectory dynamics through a spatiotemporal trajectory encoder, and fuses multimodal context with current observations using a prompt-guided integration module. This enables robust, time-aware reasoning and consistent waypoint prediction across long sequences, achieving 7.89% higher success rate and 6.33% better success weighted by path length than state-of-the-art baselines in both seen and unseen environments.
Method
The authors leverage a spatiotemporal context modeling framework named LongFly to address the challenges of long-horizon UAV visual-language navigation (VLN). The overall architecture integrates three key modules to transform fragmented historical data into structured, compact representations that support robust waypoint prediction. The framework begins by processing the current command instruction and the UAV's current visual observation, which are tokenized and projected into a shared latent space. Concurrently, historical multi-view images and waypoint trajectories are processed through dedicated modules to generate compressed visual and motion representations.
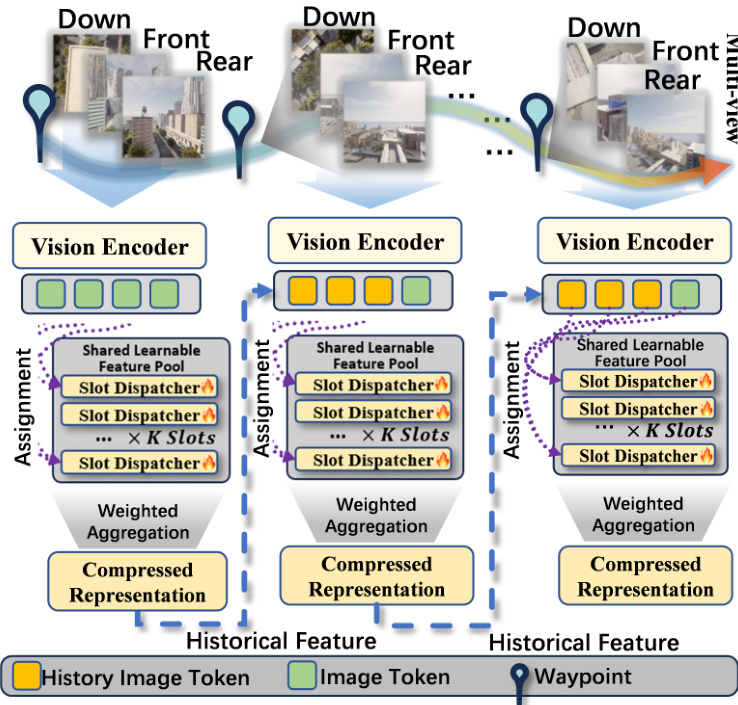
The first module, Slot-based Historical Image Compression (SHIC), addresses the challenge of efficiently storing and retrieving long-horizon visual information. It processes the sequence of historical multi-view images R1,R2,…,Rt−1 using a CLIP-based visual encoder Fv to extract visual tokens Zi at each time step. These tokens are then used to update a fixed-capacity set of learnable visual memory slots Si. The update mechanism treats each slot as a query and the visual tokens as keys and values, computing attention weights to perform a weighted aggregation of the new visual features. This process is implemented using a gated recurrent unit (GRU) to update the slot memory, resulting in a compact visual memory representation St−1 that captures persistent landmarks and spatial layouts. This approach reduces the memory and computational complexity from O(t) to O(1).

The second module, Spatio-temporal Trajectory Encoding (STE), models the UAV's motion history. It takes the historical waypoint sequence P1,P2,…,Pt−1 and transforms the absolute coordinates into relative motion representations. For each step, the displacement vector ΔPi is computed, which is then decomposed into a unit direction vector di and a motion scale ri. These are concatenated to form a 4D motion descriptor Mi. To encode temporal ordering, a time embedding τi is added, resulting in a time-aware motion representation Mi. This representation is then projected into a d-dimensional trajectory token ti using a residual MLP encoder, producing a sequence of trajectory tokens Tt−1 that serve as an explicit motion prior.

The third module, Prompt-Guided Multimodal Integration (PGM), integrates the historical visual memory, trajectory tokens, and the current instruction and observation into a structured prompt for the large language model. The natural language instruction L is encoded using a BERT encoder and projected into a unified latent dimension. The compressed visual memory St−1 and trajectory tokens Tt−1 are also projected into the same space. These components, along with the current visual observation Rt, are organized into a structured prompt that includes the task instruction, a Qwen-compatible conversation template, and UAV history status information. This prompt is then fed into a large language model (Qwen2.5-3B) to predict the next 3D waypoint Pt+1 in continuous space. This design enables coherent long-horizon multimodal reasoning without requiring additional feature-level fusion mechanisms.
Experiment
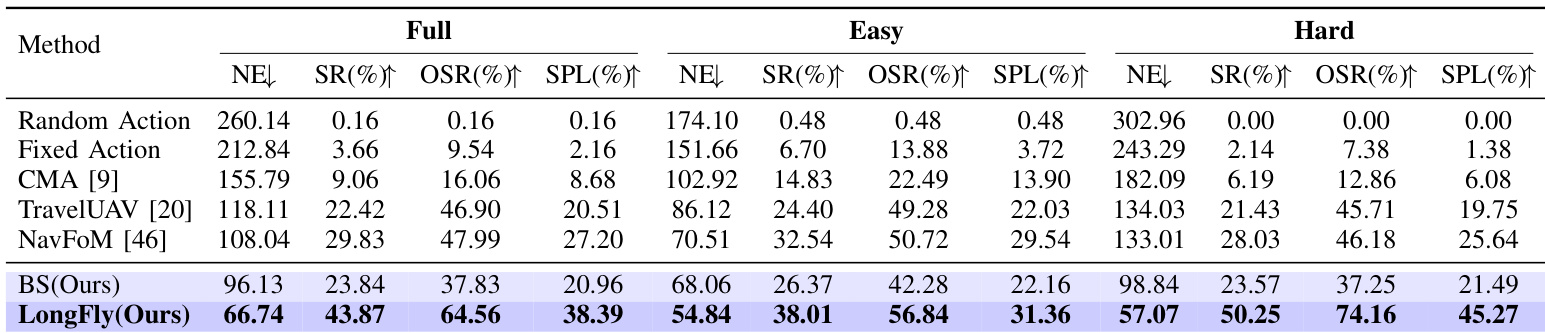
- LongFly demonstrates superior performance on the OpenUAV benchmark, achieving 33.03m lower NE, 7.22% higher SR, and over 6.04% improvement in OSR and SPL compared to baselines on the seen dataset, with the largest gains on the Hard split.
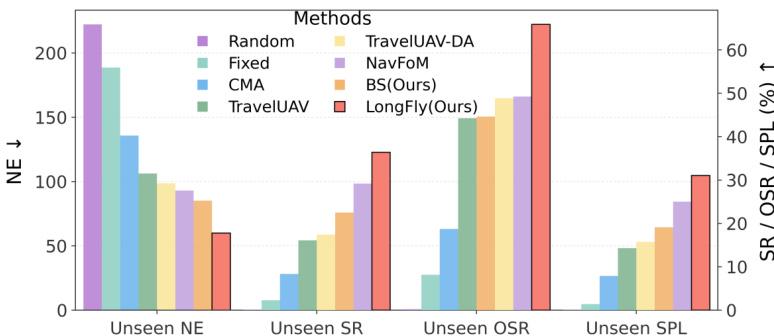
- On the unseen object set, LongFly achieves 43.87% SR and 64.56% OSR, outperforming NavFoM by 14.04% in SR and 16.57% in OSR, with significant gains in NE and SPL on the Hard subset.
- On the unseen map set, LongFly attains 24.88% OSR and 7.98% SPL in the Hard split, the only method to maintain reasonable performance, while others fail (OSR ≈ 0), highlighting its robustness to novel layouts.
- Ablation studies confirm that both SHIC and STE modules are essential, with their combination yielding the best results; prompt-guided fusion and longer history lengths significantly improve performance, especially in long-horizon tasks.
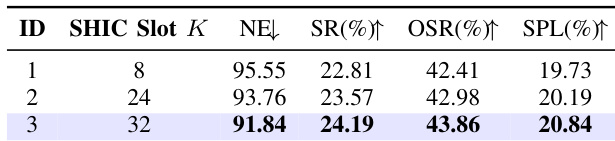
- SHIC slot number analysis shows optimal performance at K=32, with improvements in SR, SPL, and NE as slots increase.
- Qualitative results demonstrate LongFly’s ability to maintain global consistency and avoid local traps through spatiotemporal context integration, unlike the baseline that drifts due to myopic reasoning.
Results show that LongFly significantly outperforms all baseline methods across unseen environments, achieving the lowest NE and highest SR, OSR, and SPL. The model demonstrates robust generalization, particularly in unseen object and map settings, with the largest gains observed in challenging long-horizon scenarios.
Results show that LongFly significantly outperforms all baseline methods across all difficulty levels, achieving the lowest NE and highest SR, OSR, and SPL. On the Full split, LongFly reduces NE by 29.39 compared to the baseline BS and improves SR by 20.03 percentage points, demonstrating its effectiveness in long-horizon navigation.
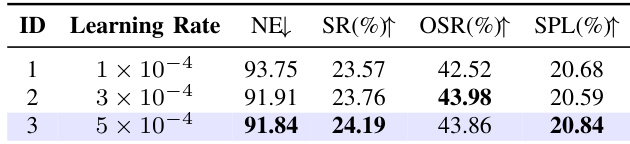
Results show that the model achieves the best performance at a learning rate of 5 × 10⁻⁴, with the highest success rate (SR) of 24.19% and the highest SPL of 20.84%, while maintaining a low NE of 91.84. Performance remains stable across different learning rates, with only minor variations in SR, OSR, and SPL, indicating robustness to learning rate changes.
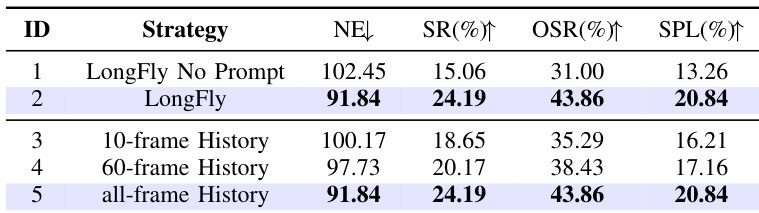
Results show that LongFly with prompt-guided fusion achieves significantly better performance than the version without prompts, reducing NE from 102.45 to 91.84 and increasing SR, OSR, and SPL. The model with all-frame history performs as well as the 60-frame version, indicating that longer history provides diminishing returns, while prompt guidance is essential for aligning spatiotemporal context with instructions.
The authors conduct an ablation study on the number of SHIC slots, showing that increasing the slot count from 8 to 32 improves performance across all metrics. With 32 slots, the model achieves the best results, reducing NE to 91.84, increasing SR to 24.19%, OSR to 43.86%, and SPL to 20.84%.