Command Palette
Search for a command to run...
SpatialTree: MLLMs에서 공간 능력이 어떻게 분기되는가
SpatialTree: MLLMs에서 공간 능력이 어떻게 분기되는가
Yuxi Xiao Longfei Li Shen Yan Xinhang Liu Sida Peng Yunchao Wei Xiaowei Zhou Bingyi Kang
초록
인지과학은 공간 능력이 인지(perception)에서 사고(reasoning)와 상호작용(interaction)으로 이어지는 점진적인 발달 과정을 거친다고 제안한다. 그러나 다중모달 대규모 언어모델(Multimodal Large Language Models, MLLMs)에서는 이 계층 구조가 여전히 잘 이해되지 않고 있으며, 대부분의 연구는 좁은 범위의 과제에 집중하고 있다. 본 연구에서는 인지과학에 영감을 받은 ‘SpatialTree’라는 계층 구조를 제안한다. 이는 공간 능력을 네 가지 수준으로 체계화한다: 저수준 인지(L1), 정신적 지도 구성(L2), 시뮬레이션(L3), 그리고 에이전트적 능력(L4). 이 분류 체계를 바탕으로, 주류 MLLMs의 27개 하위 능력에 걸쳐 종합적으로 평가할 수 있는 세계 최초의 능력 중심 계층적 벤치마크를 구축하였다. 평가 결과는 명확한 구조를 보였다. L1 능력들은 대부분 서로 수직적(orthogonal)이며, 고수준 능력들은 강하게 상관관계를 보이며, 이는 점점 더 높은 상호의존성을 나타낸다. 타겟된 지도형 미세조정(supervised fine-tuning)을 통해 우리는 놀라운 전이 동역학을 발견하였다: L1 내에서는 부정적 전이(negative transfer)가 나타나지만, 저수준에서 고수준 능력으로의 수직적 전이(vertical transfer)는 강하고, 상호보완적인 상호작용이 두드러진다. 마지막으로, 전체 계층 구조를 개선하는 방법을 탐구하였다. 결과적으로, 단순히 광범위한 ‘사고’를 장려하는 난이도 높은 강화학습(RL) 전략은 신뢰할 수 없다는 점을 발견하였다. 이는 복잡한 추론에는 도움이 되지만, 직관적 인지 능력에는 해로운 영향을 미친다. 이를 해결하기 위해, 불필요한 사고 과정을 억제하는 간단한 자동 사고(auto-think) 전략을 제안한다. 이 전략은 RL이 모든 수준에서 일관되게 성능을 향상시킬 수 있도록 한다. SpatialTree를 구축함으로써, MLLMs 내에서 공간 능력을 이해하고 체계적으로 확장할 수 있는 개념적 프레임워크를 제시한다.
One-sentence Summary
Researchers from Zhejiang University, ByteDance Seed, and Beijing Jiaotong University propose SpatialTree, a cognitive-science-inspired four-level hierarchy for spatial abilities in multimodal LLMs. Their benchmark reveals orthogonal low-level perception skills but strongly correlated higher-level reasoning abilities, uncovering cross-level transfer benefits. They introduce an auto-think strategy that suppresses unnecessary deliberation during reinforcement learning, consistently enhancing performance across all levels unlike prior unreliable methods for systematically scaling spatial cognition.
Key Contributions
- Introduces SpatialTree, a cognitive-science-inspired hierarchical taxonomy organizing spatial abilities in multimodal LLMs into four progressive levels (L1 perception to L4 agentic competence), addressing the lack of structured understanding beyond narrow task-centric evaluations. This framework enables systematic analysis of spatial skill dependencies, revealing through evaluation across 27 sub-abilities that L1 skills are largely orthogonal while higher-level skills exhibit strong correlations.
- Proposes the first capability-centric benchmark for spatial intelligence, rigorously assessing mainstream MLLMs and uncovering critical transfer dynamics: negative transfer occurs within L1 perception skills during fine-tuning, but strong cross-level transfer emerges from low- to high-level abilities with notable synergy, highlighting pathways for efficient capability scaling.
- Identifies limitations in reinforcement learning for spatial tasks—where extensive "thinking" improves complex reasoning but degrades intuitive perception—and introduces an auto-think strategy that suppresses unnecessary deliberation, enabling RL to consistently enhance performance across all hierarchical levels as validated in the benchmark.
Introduction
Spatial intelligence—the ability to perceive, reason about, and interact with 2D/3D spaces—is critical for multimodal large language models (MLLMs) to handle real-world tasks like navigation or physical reasoning, yet its complexity has hindered systematic study. Prior work fragmented spatial abilities into isolated task-specific evaluations, such as single-image positioning or 3D point cloud analysis, failing to reveal how foundational skills compose hierarchically or transfer across contexts. The authors address this by introducing SpatialTree, the first capability-centric framework that organizes spatial intelligence into a four-layer cognitive hierarchy (L1–L4), enabling structured analysis of ability emergence and targeted scaling strategies for MLLMs through strategic data utilization.
Dataset
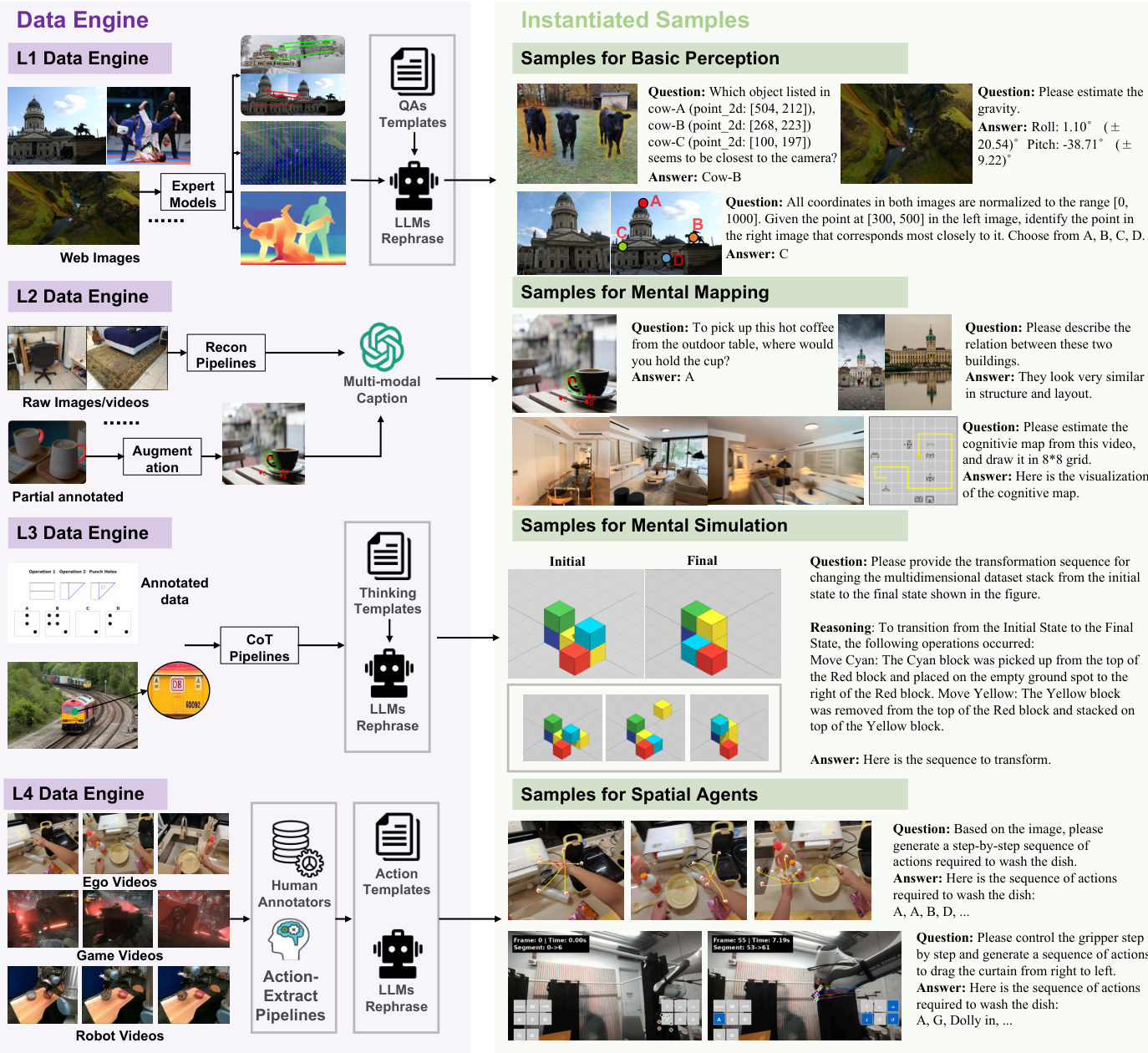
The authors introduce SpatialTree-Bench, a capability-centric benchmark for spatial intelligence, structured into four hierarchical levels. Here's a concise overview:
-
Composition and sources:
- Built by unifying 10+ existing datasets (e.g., CameraBench, MMSI-Bench) covering L1–L3 spatial abilities.
- Augmented with SpatialPlus, a new dataset targeting gaps (especially L4), generated via the SpatialEngine using 3D reconstruction data, game footage, egocentric videos, and robotics datasets.
-
Key subset details:
- L1 Perception (size: ~15K samples): Uses expert models (DepthAnything3, SpatialTracker) to extract geometric attributes (distance, size, motion). Filtered via QA templates and LLM rephrasing.
- L2 Mental Mapping (size: ~8K samples): Processes BEV maps from 3D reconstruction pipelines; augmented with spatial captions and memory-retrieval QAs via multimodal LLMs.
- L3 Mental Simulation (size: ~12K samples): Enhances reasoning tasks with structured Chain-of-Thought templates; filters prioritize causal/relational problem-solving.
- L4 Spatial Agent (size: ~5K samples): Curates Internet-sourced navigation/manipulation data (human hands, robots); filters enforce multi-step action sequences via manual annotation.
-
Usage in training/evaluation:
- Training splits combine SpatialPlus with general visual-instruction data (LLaVA-Video, LLaVA-NeXT) using VST’s mixture ratio (80% general data, 20% spatial data).
- Evaluated via hybrid multi-option + LLM-as-a-Judge protocols for granular capability assessment.
- SFT/RL experiments reveal hierarchical dependencies: L1 skills transfer to higher levels, while RL exposes reasoning/perception trade-offs.
-
Processing strategies:
- L4 actions discretized into high-level motion primitives (e.g., "Dolly In," "Pan Left") via an Action-Extraction Pipeline.
- Multi-format QA generation (e.g., multiple-choice, abstract descriptions) boosts diversity for single problems.
- Human annotators convert interaction sequences into executable multi-step tasks; LLMs rephrase QAs for linguistic consistency.
Method
The authors leverage a hierarchical taxonomy, termed SpatialTree, to structure and evaluate spatial intelligence across four progressive levels, from foundational perception to agentic execution. This framework is designed to mirror cognitive development, where lower layers provide the perceptual scaffolding necessary for higher-order reasoning and action. The architecture is not merely descriptive but operationalized through a multi-stage data engine and a weighted aggregation metric that reflects the dependency structure of spatial capabilities.
At the base, Level 1 (Perception) encapsulates primitive visual sensing abilities: Geometry (Distance, Size, Shape), Motion (Egocentric, Allocentric), Orientation (Gravity, Object), Relation (Topology, Correspondence), and Localization (Detection, Grounding). These are instantiated via automated pipelines that leverage expert models and LLMs to generate question-answer pairs from web images, ensuring broad coverage of real-world spatial cues. As shown in the figure below, these perceptual primitives are the building blocks for all subsequent layers.
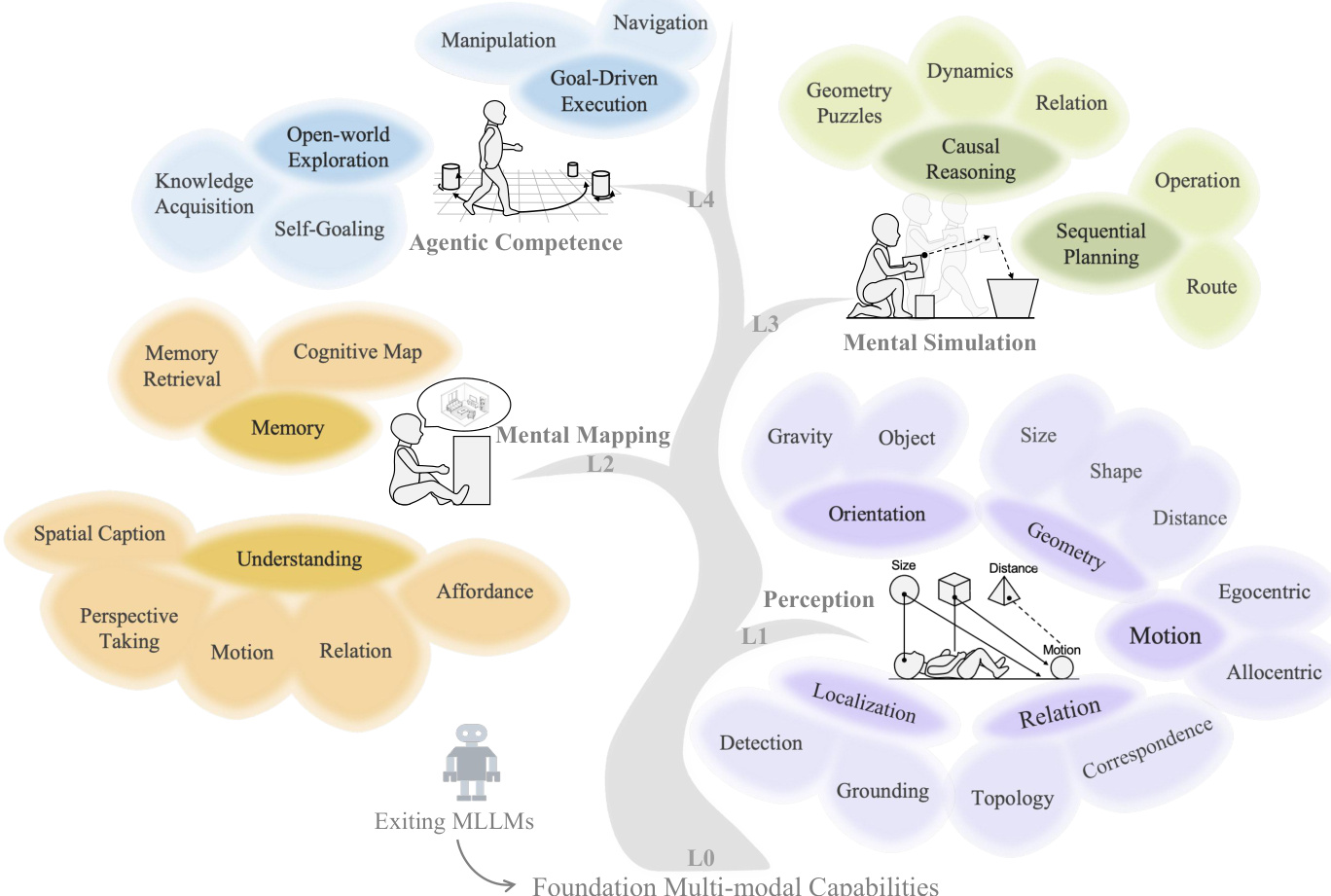
Level 2 (Mental Mapping) transitions from raw perception to semantic alignment. It comprises Understanding—translating visual scenes into linguistic descriptions, recognizing affordances, and taking alternative perspectives—and Memory, which constructs and retrieves cognitive maps from fragmented observations. The data engine for this level ingests raw images and videos, applies reconstruction and augmentation pipelines, and uses multi-modal captioning to generate prompts that test spatial understanding and memory retrieval. The figure below illustrates how this layer bridges perception with language and memory, enabling the system to reason about object function and spatial history.
Level 3 (Mental Simulation) introduces causal and sequential reasoning over spatial configurations. It includes tasks such as geometry puzzles, route planning, and operation sequencing, which require the agent to simulate transformations and predict outcomes. The data engine for this level uses Chain-of-Thought (CoT) pipelines and LLM rephrasing to generate complex reasoning prompts from annotated datasets, such as block manipulation sequences. This layer demands the integration of memory and understanding to simulate spatial dynamics before execution.
Level 4 (Agentic Competence) represents the culmination: the ability to translate internal plans into executable actions in 3D environments. The authors formalize the agent’s decision-making as a probabilistic model:
(St,At,Mt)∼Pθ(⋅Ot,Ht−1),whereHt−1={(O0,A0,M0),…,(Ot−1,At−1,Mt−1)}where Ot is the multi-modal observation, St the latent state, At the action, and Mt the updated memory. Actions are mapped to a standardized 6-DoF motion space for navigation (e.g., dolly, truck, pedestal, pan, tilt, roll) and a 7-DoF space for manipulation (including gripper state), enabling cross-domain evaluation. The data engine for L4 curates action annotations from game videos, robotic datasets, and human-hand manipulation clips, using human annotators and action-extraction pipelines to generate prompts that require step-by-step control sequences.
To evaluate performance across this hierarchy, the authors implement a bottom-up weighted aggregation scheme. As shown in the figure below, each node in the SpatialTree is assigned a weight reflecting its foundational importance, with L1 receiving the highest weight (0.25) due to its role as a prerequisite for higher layers. The final score is computed recursively: the score of a parent node is the weighted sum of its children’s scores. This ensures the metric is both theoretically grounded in cognitive hierarchy and empirically validated through correlation analysis of model performance.

The training and evaluation process is thus not monolithic but tiered: models are assessed on increasingly complex tasks, with performance at each level informing the next. The data engines ensure scalability and diversity, while the action mapping and prompt templates standardize output formats for fair comparison. This architecture enables a granular, interpretable assessment of spatial intelligence, moving beyond single-task benchmarks to a unified, multi-layered evaluation framework.
Experiment
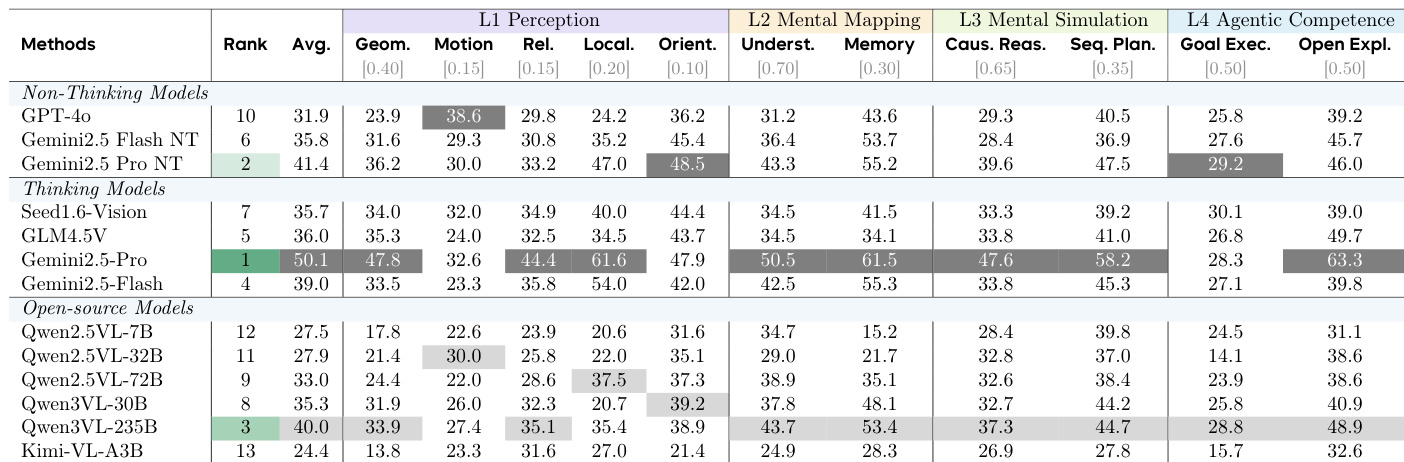
- Evaluated MLLMs on SpatialTree-Bench across 27 sub-abilities: Gemini 2.5 Pro achieved 50.1 overall, with Qwen3-VL (open-source) scoring 40.0; revealed L1 skills as orthogonal while higher levels (L3-L4) showed strong correlations indicating interdependency.
- Supervised fine-tuning on low-level abilities (e.g., distance, size) demonstrated negative intra-L1 transfer but significant cross-level gains, improving robotic manipulation by 27.1% and complex reasoning by 36.0%; blended training of multiple abilities yielded +1.1 overall synergy.
- Hierarchy-aware reinforcement learning with auto-think strategy suppressed excessive deliberation for intuitive tasks, enabling consistent performance improvements across all spatial levels compared to unreliable naive RL approaches.
The authors evaluate Qwen2.5-VL-7B under various reinforcement learning strategies, finding that full RL with auto-think yields the highest average score (30.8) and improves most sub-abilities, particularly in L4 Agentic Competence. In contrast, naive RL without auto-think harms performance in L2 Mental Mapping and L3 Mental Simulation, while targeted RL per level shows mixed gains, indicating that hierarchical reward design is critical for balanced spatial ability development.

The authors evaluate fine-tuned multimodal LLMs across a hierarchical spatial benchmark, finding that combining multiple low-level perception abilities (distance, size, correspondence) yields synergistic gains in higher-level tasks, while individual fine-tuning often harms performance within the same level. Results show that blended training improves overall scores and mitigates negative transfer, particularly benefiting mental mapping and agentic competence.

The authors evaluate multimodal LLMs across a hierarchical spatial benchmark, finding that Gemini 2.5 Pro achieves the highest overall score (50.1), while Qwen3VL-235B leads among open-source models (40.0). Results show strong performance in higher-level tasks like goal execution and open exploration for thinking models, whereas non-thinking models such as GPT-4o and Gemini 2.5 Pro NT lag behind in agentic competence despite competitive perception scores. Open-source models generally underperform, with Qwen3VL-235B showing the best balance across levels but still trailing proprietary thinking models in simulation and agentic tasks.
The authors use Pearson correlation analysis to reveal that higher-level spatial abilities (L3–L4) are strongly interdependent, while lower-level perception skills (L1) show weak correlations, indicating they operate largely independently. Results show that fine-tuning on specific low-level abilities can yield negative transfer within the same level but enable positive cross-level transfer to higher-order reasoning and execution tasks. The observed structure supports a hierarchical model of spatial intelligence, where foundational perception skills underpin increasingly complex, interdependent reasoning capabilities.
