Command Palette
Search for a command to run...
비디오 아바타를 통한 폐쇄 루프 월드 모델링을 통한 능동 지능
비디오 아바타를 통한 폐쇄 루프 월드 모델링을 통한 능동 지능
Xuanhua He Tianyu Yang Ke Cao Ruiqi Wu Cheng Meng Yong Zhang Zhuoliang Kang Xiaoming Wei Qifeng Chen
초록
현재의 비디오 아바타 생성 기법들은 정체성 유지와 운동 정렬 측면에서 뛰어나지만, 진정한 자율성은 부족하며, 환경에 적응적으로 상호작용하면서 장기적인 목표를 자율적으로 추구할 수 없다. 이를 해결하기 위해 우리는 장기적 시점에서 상호작용 가능한 비디오 아바타를 평가하기 위한 작업 및 벤치마크인 L-IVA(Long-horizon Interactive Visual Avatar)와, 비디오 아바타에 능동적 지능을 가능하게 하는 최초의 프레임워크인 ORCA(Online Reasoning and Cognitive Architecture)를 제안한다. ORCA는 내부 세계 모델(Internal World Model, IWM)의 능력을 실현하기 위해 두 가지 핵심 혁신을 도입한다. 첫째, 예측된 결과를 실제 생성 결과와 지속적으로 비교 검증함으로써 생성 불확실성 하에서도 강건한 상태 추적을 유지하는 폐쇄형 OTAR 주기(관찰-사고-행동-반성)이며, 둘째, 전략적 사고를 수행하는 시스템 2와 추상적인 계획을 모델에 특화된 정밀한 행동 명령어로 변환하는 시스템 1로 구성된 계층적 이중 시스템 아키텍처이다. ORCA는 아바타 제어를 부분 관측 마르코프 결정 과정(POMDP)으로 공식화하고, 결과 검증을 통한 지속적인 신념 업데이트를 구현함으로써, 개방형 도메인 환경에서 자율적인 다단계 작업 수행을 가능하게 한다. 광범위한 실험 결과는 ORCA가 오픈 루프 및 반성 없는 기존 벤치마크 대비 작업 성공률과 행동 일관성에서 뚜렷한 성능 우위를 보이며, 비디오 아바타의 지능을 수동적 애니메이션에서 능동적이고 목표 지향적인 행동으로 진화시키는 데 있어 IWM 기반 설계의 타당성을 입증한다.
One-sentence Summary
Researchers from The Hong Kong University of Science and Technology, Meituan, and University of Science and Technology of China propose ORCA, the first framework enabling autonomous video avatars through its closed-loop OTAR cycle and hierarchical dual-system architecture, which formulates control as a POMDP with continuous belief updating to advance goal-directed behavior in open-domain scenarios beyond passive animation.
Key Contributions
- Current video avatar methods lack autonomous goal pursuit despite strong identity preservation, prompting the introduction of L-IVA, a benchmark for evaluating long-horizon planning in stochastic generative environments where avatars must complete open-domain tasks through multi-step interactions.
- ORCA enables active intelligence via a closed-loop OTAR cycle (Observe-Think-Act-Reflect) for robust state tracking under generative uncertainty and a hierarchical dual-system architecture where System 2 handles strategic reasoning with state prediction while System 1 translates plans into precise action captions for execution.
- Experiments on L-IVA show ORCA significantly outperforms open-loop and non-reflective baselines in task success rate and behavioral coherence, validating its Internal World Model-inspired design for transitioning avatars from passive animation to goal-oriented behavior.
Introduction
Video avatars have advanced to generate high-fidelity human motions from inputs like speech or pose sequences, enabling applications such as virtual assistants. However, existing methods remain passive, executing predefined actions without autonomous goal pursuit—limiting their use in dynamic scenarios like product demonstrations where multi-step planning and environmental interaction are essential. Prior work fails to address two core challenges: (1) state estimation under generative uncertainty, where stochastic video outputs prevent reliable internal state tracking, and (2) open-domain action planning, as semantic commands lack the precision needed for consistent execution in unbounded action spaces. The authors introduce ORCA, the first framework embedding active intelligence into video avatars via a closed-loop Observe-Think-Act-Reflect cycle that continuously verifies outcomes to correct state errors, coupled with a dual-system architecture where high-level reasoning translates goals into model-specific control signals for precise execution. This enables reliable long-horizon task completion in stochastic generative environments.
Dataset
The authors introduce the L-IVA Benchmark, a novel evaluation dataset for active agency in video generation, comprising 100 tasks across five real-world scenarios (Kitchen, Livestream, Workshop, Garden, Office). Key details:
-
Composition and sources:
- Hybrid dataset with 92 synthetic images and 8 real-world images.
- 100 tasks total (20 per scenario category), including 5 two-person collaborative tasks per category.
- Each task requires 3–8 interaction steps involving >3 objects, averaging 5.0 sub-goals.
-
Subset specifics:
- Real-world subset (8 images): Sourced from Pexels, filtered for scenes with interactive objects enabling multi-step physical manipulations. Initial high-level intentions are manually defined.
- Synthetic subset (92 images): Generated via Nanobanana using a "design-then-generate" approach—high-level intentions are defined first, then scenes are crafted via text prompts to ensure logical solvability of object interactions.
-
Annotation and processing:
- All samples include object inventories (names, positions, states), natural language intentions, and reference action sequences.
- Real-data metadata (subgoals, object descriptions, action prompts) is generated using Gemini-2.5-Pro from images and intentions.
- Annotations are stored as image-YAML pairs, with evaluation focusing on goal completion (not trajectory matching) and accepting alternative valid action sequences.
-
Usage in the paper:
- Exclusively used for evaluation (not training) to test three agent paradigms: Open-Loop Planner, Reactive Agent, and VAGEN-style CoT.
- Assessed via metrics including Task Success Rate (TSR), Physical Plausibility Score (PPS), and Action Fidelity Score (AFS), with human preference studies.
- Tasks employ fixed-viewpoint, single-room settings to avoid spatial inconsistencies in video generation models.
Method
The authors leverage a novel framework called ORCA (Online Reasoning and Cognitive Architecture) to enable goal-directed, long-horizon interaction in generative video avatars. ORCA is designed around two core innovations: a closed-loop Observe-Think-Act-Reflect (OTAR) cycle and a hierarchical dual-system architecture, both inspired by Internal World Model (IWM) theory. These components work in concert to maintain accurate belief states despite the stochastic nature of image-to-video (I2V) generation and to bridge the gap between high-level strategic reasoning and low-level execution fidelity.
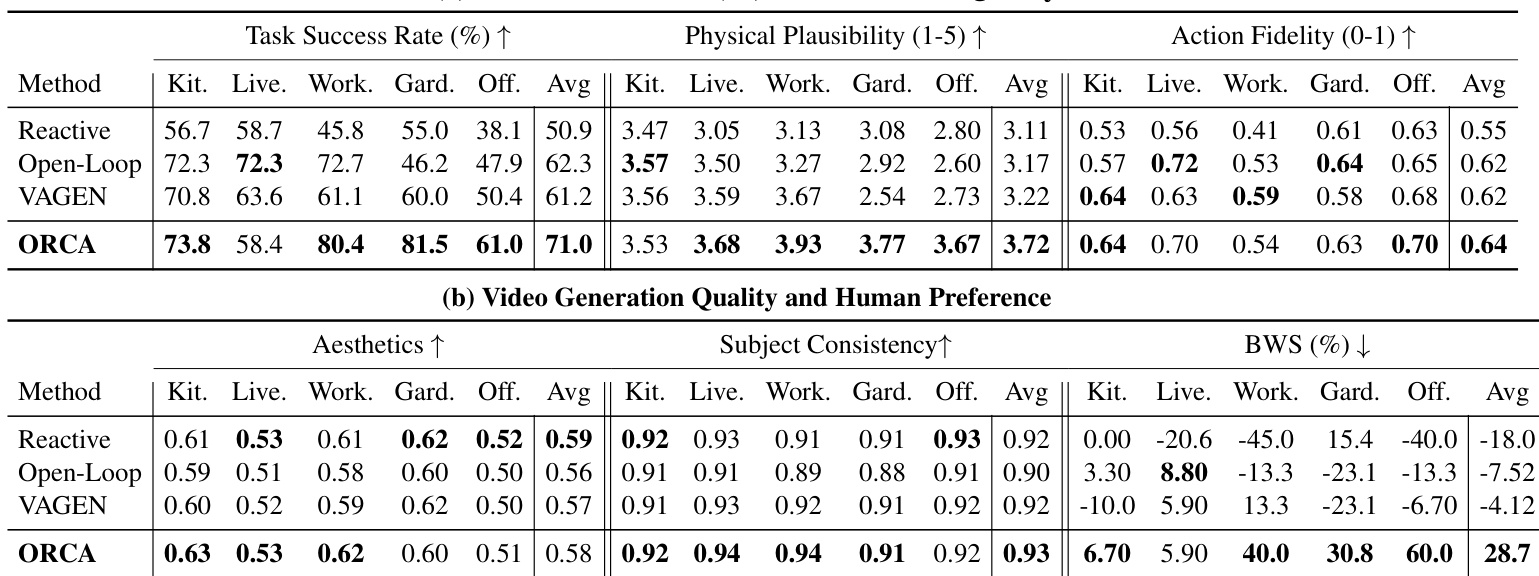
The framework operates as a continuous loop, beginning with an initial scene and user intention. System 2, the strategic planner, first initializes the belief state s^0 by analyzing the scene and decomposing the intention into a structured plan of sub-goals. This process is guided by a carefully engineered prompt that enforces sequential, verifiable outcomes and leverages the broad world knowledge of pre-trained vision-language models (VLMs). As shown in the framework diagram, this initialization phase sets the stage for subsequent reasoning by establishing a task checklist and tracking object states.
At each time step t, the Observe stage updates the belief state s^t using the latest video clip ot and the previous belief s^t−1. This update incorporates scene changes, object state transitions, and sub-goal completion status, ensuring the agent maintains an accurate internal model of the environment. The Think stage then follows, where System 2 reasons over the current belief state s^t, the original intention I, and the current observation ot to generate a textual command gt and a predicted next state gs^. This strategic reasoning is formalized as:
gt,gs^=πSys2(s^t,I)The generated command and predicted state are then passed to System 1, the action grounder, which translates the abstract plan into a precise, model-specific action caption at. This grounding is critical for reliable generation, as different I2V models respond differently to prompt phrasing. The grounding policy is defined as:
at=πSys1(gt,gs^,ot,s^t)The Act stage then executes the action by sampling a video clip vt+1 from the I2V model Gθ conditioned on the current scene ot and the generated caption at:
vt+1∼Gθ(ot,at)The Reflect stage is where ORCA’s closed-loop design becomes critical. System 2 compares the actual outcome ot+1 against the predicted state gs^ to determine whether the action was successful. This verification produces a binary decision δt∈{accept,reject}. If the outcome is rejected, the system either retries the action with a revised caption (up to a maximum number of retries) or triggers adaptive re-planning for the next iteration. This prevents belief corruption from failed generations and ensures the agent’s internal state remains aligned with reality. The cycle continues until all sub-goals are completed.

The entire process is implemented without task-specific training, relying instead on structured prompting of pre-trained VLMs such as Gemini-2.5-Flash for both System 1 and System 2, and a distilled I2V model (Wanx2.2 with LoRA) for video generation. The prompts for each module—initialization, observation, thinking, action grounding, and reflection—are meticulously designed to enforce structured outputs and domain-specific constraints, ensuring both strategic coherence and execution fidelity across diverse, open-domain scenarios.
Experiment
- Evaluated on L-IVA benchmark using hybrid human-VLM metrics: ORCA achieves 71.0% average Task Success Rate (TSR) and 3.72 Physical Plausibility Score across 5 scenarios (Kitchen, Livestream, Workshop, Garden, Office), surpassing all baselines.
- Outperforms in high-dependency tasks (Garden/Workshop) where closed-loop reflection prevents error accumulation, while Open-Loop Planner remains competitive in low-dependency scenarios (Kitchen/Livestream) due to step-budget efficiency.
- Achieves highest human preference via Best-Worst Scaling (BWS) and Subject Consistency, validating that closed-loop world modeling balances task completion with execution reliability.
- Ablation studies confirm criticality of belief state tracking (TSR drops severely without it), reflection for outcome verification, and hierarchical action specification for precise command grounding.
The authors evaluate ablated variants of ORCA on the Workshop scene, showing that removing System 1, Reflect, or Belief State each degrades performance. ORCA (Full) achieves the highest Task Success Rate (77%), Subject Consistency (0.94), and Best-Worst Scaling score (26.7%), confirming that all three components are critical for robust long-horizon execution. Removing Belief State causes the largest TSR drop, while omitting Reflect most harms human preference.
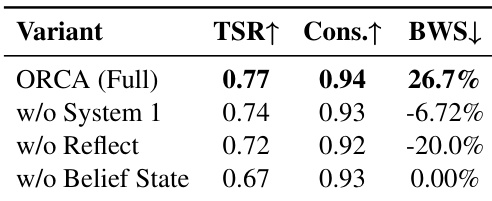
The authors use a hybrid human-VLM evaluation framework to assess agents on the L-IVA benchmark, measuring task success, physical plausibility, action fidelity, subject consistency, and human preference across five scenarios. Results show ORCA achieves the highest average Task Success Rate (71.0%) and Physical Plausibility (3.72), while also leading in Subject Consistency (0.93) and human preference (BWS 28.7%), demonstrating the effectiveness of its closed-loop architecture with reflection. Although Open-Loop Planner performs competitively in low-dependency scenarios like Kitchen and Livestream, it suffers from poor subject consistency and negative human preference due to undetected execution errors, while Reactive Agent and VAGEN show lower task completion and physical plausibility due to lack of world modeling or uncorrected hallucinations.