Command Palette
Search for a command to run...
GenEnv: LLM 에이전트와 환경 시뮬레이터 간의 난이도 일치형 공진화
GenEnv: LLM 에이전트와 환경 시뮬레이터 간의 난이도 일치형 공진화
Jiacheng Guo Ling Yang Peter Chen Qixin Xiao Yinjie Wang Xinzhe Juan Jiahao Qiu Ke Shen Mengdi Wang
초록
대규모 언어 모델(LLM) 기반 에이전트의 훈련은 현실 세계 상호작용 데이터의 높은 비용과 정적 성격으로 인해 핵심적인 제약을 받고 있다. 이를 해결하기 위해 우리는 에이전트와 확장 가능한 생성형 환경 시뮬레이터 간의 난이도 조정된 공진화 게임을 구축하는 GenEnv라는 프레임워크를 제안한다. 기존의 정적 데이터셋 위에서 모델을 진화시키는 전통적인 방법과 달리, GenEnv는 데이터의 진화를 실현한다. 시뮬레이터는 동적 커리큘럼 정책으로 작용하며, 에이전트의 현재 능력 수준에 맞춰 지속적으로 맞춤형 작업을 생성한다. 이 과정은 단순하면서도 효과적인 α-커리큘럼 보상(α-Curriculum Reward)에 의해 안내되며, 작업의 난이도를 에이전트의 현재 능력과 일치시킨다. 우리는 API-Bank, ALFWorld, BFCL, Bamboogle, TravelPlanner 등 다섯 가지 벤치마크에서 GenEnv를 평가하였으며, 해당 작업들에서 7B 규모의 기준 모델 대비 최대 +40.3%의 성능 향상을 달성했고, 더 큰 모델들의 평균 성능과 동등하거나 이를 초월하는 결과를 얻었다. 기존의 Gemini 2.5 Pro 기반 오프라인 데이터 증강 방법과 비교했을 때, GenEnv는 데이터 사용량의 3.3배 적은 양으로 더 우수한 성능을 달성하였다. 정적 감독에서 적응형 시뮬레이션으로의 전환을 통해, GenEnv는 에이전트의 능력 확장을 위한 데이터 효율적인 길을 제시한다.
One-sentence Summary
Princeton University, ByteDance Seed, and et al. researchers introduce GENEnv, a framework establishing a difficulty-aligned co-evolutionary game between LLM agents and environment simulators using α-Curriculum Reward to dynamically generate tasks matched to agent capabilities, outperforming 7B baselines by up to 40.3% while using 3.3× less data than Gemini-based augmentation across five agent benchmarks including API-Bank and ALFWorld.
Key Contributions
- Addresses the bottleneck of high-cost static real-world interaction data for training LLM agents by introducing GENEnv, a framework that establishes a difficulty-aligned co-evolutionary game between an agent and a generative environment simulator.
- Proposes a data-evolving paradigm where the simulator dynamically generates tasks tailored to the agent's capabilities using an α-Curriculum Reward, replacing static datasets with adaptive simulation for continuous capability progression.
- Demonstrates significant improvements across five benchmarks (API-Bank, ALFWorld, BFCL, Bamboogle, TravelPlanner), achieving up to +40.3% gains over 7B baselines and matching larger models while using 3.3× less data than Gemini 2.5 Pro-based augmentation.
Introduction
Training capable LLM agents is critically bottlenecked by expensive static interaction data that limits exploration beyond expert demonstrations, hindering robust generalization in real-world applications. Prior methods relying on fixed datasets or offline synthetic data augmentation fail to adapt task difficulty to the agent's evolving skill level, leading to inefficient learning and capability plateaus. The authors introduce GenEnv, which establishes a difficulty-aligned co-evolutionary loop where a generative environment simulator dynamically tailors tasks to the agent's zone of proximal development using an α-Curriculum Reward, enabling efficient capability scaling through adaptive simulation rather than static supervision.
Dataset
The authors maintain two dynamically evolving datasets generated through agent-environment interactions:
-
Dataset composition and sources:
Training data originates from online interactions where an environment policy (π_env) generates task batches (𝒯_t), each containing multiple task instances with prompts, evaluation specs, and optional ground-truth actions. The agent then produces interaction traces (rollouts) stored in two pools:- Agent training pool (𝒟_train): Collects valid interaction traces (well-formed, evaluable trajectories with final actions and rewards).
- Environment SFT pool (𝒟_env): Stores environment generations as (conditioning context → task instance) pairs, weighted by environment reward (e.g., ∝ exp(λR_env)).
-
Key subset details:
- GenEnv-Random: Uses Qwen2.5-7B-Instruct to dynamically generate 4 task variations per prompt per epoch. No model updates occur (fixed weights).
- GenEnv-Static: Pre-generates 5 variations for each of 544 base training samples, creating a fixed 3,264-sample dataset.
- Gemini-Offline: Gemini 2.5 Pro generates filtered variations—957 samples (1.76× base) for "Gemini-2x" and 1,777 samples (3.27×) for "Gemini-4x".
-
Data usage in training:
𝒟_train forms an evolving mixture of base data, historical traces, and new on-policy traces. The agent samples from this pool for continuous learning. 𝒟_env trains π_env via reward-weighted regression (RWR), adjusting task difficulty to target a success rate α. Both pools update each epoch, closing the data-evolution loop. -
Processing details:
Traces enter 𝒟_train only if valid (e.g., tool calls parse correctly, outputs match schema). 𝒟_env records weight environment generations by exp(λR_env) (λ=1.0). No cropping is applied; metadata like success statistics inform π_env’s conditioning context.
Method
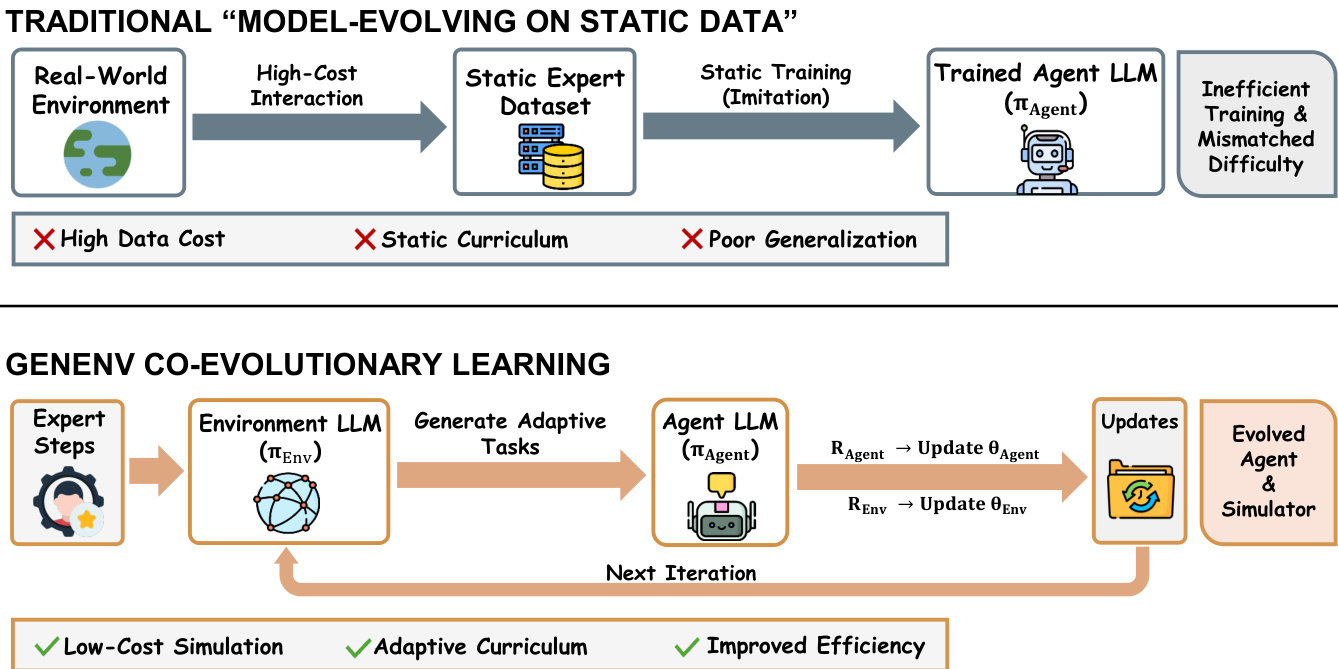
The authors leverage a co-evolutionary framework called GENEnv, which reimagines agent training as a two-player curriculum game between an Agent Policy πagent and an Environment Policy πenv. Unlike traditional methods that rely on static expert datasets, GENEnv dynamically generates training data through an LLM-based environment simulator, enabling adaptive curriculum learning that evolves in tandem with the agent’s capabilities. This paradigm shift replaces costly real-world interaction with low-cost, scalable simulation, as illustrated in the framework diagram comparing traditional static training to GENEnv’s co-evolutionary loop.
The training process unfolds in three distinct stages per iteration. In Stage 1, the Environment LLM generates a batch of tasks conditioned on the agent’s historical performance, and the Agent LLM attempts them, producing execution traces. These traces are then evaluated in Stage 2 to compute two distinct rewards: the agent reward Ragent, which measures task success via exact match for structured actions or soft similarity for free-form outputs, and the environment reward Renv, which evaluates task difficulty alignment. The environment reward is defined as Renv(p^)=exp(−β(p^−α)2), where p^ is the empirical success rate over the batch and α is the target success rate (typically 0.5), ensuring tasks are neither too easy nor too hard. A difficulty filter excludes batches where ∣p^−α∣>kmin to prevent overfitting to transient performance spikes.
In Stage 3, both policies are updated simultaneously. The agent policy is optimized via Group Relative Policy Optimization (GRPO) to maximize E[Ragent], while the environment policy is fine-tuned using Reward-Weighted Regression (RWR) on a weighted supervised fine-tuning set, where weights are proportional to exp(λRenv(p^)). To ensure stability, environment updates are regularized with a KL penalty relative to the initial simulator and capped by a maximum KL threshold. Valid agent traces and weighted environment generations are then aggregated into respective training pools for subsequent iterations, closing the co-evolutionary loop.
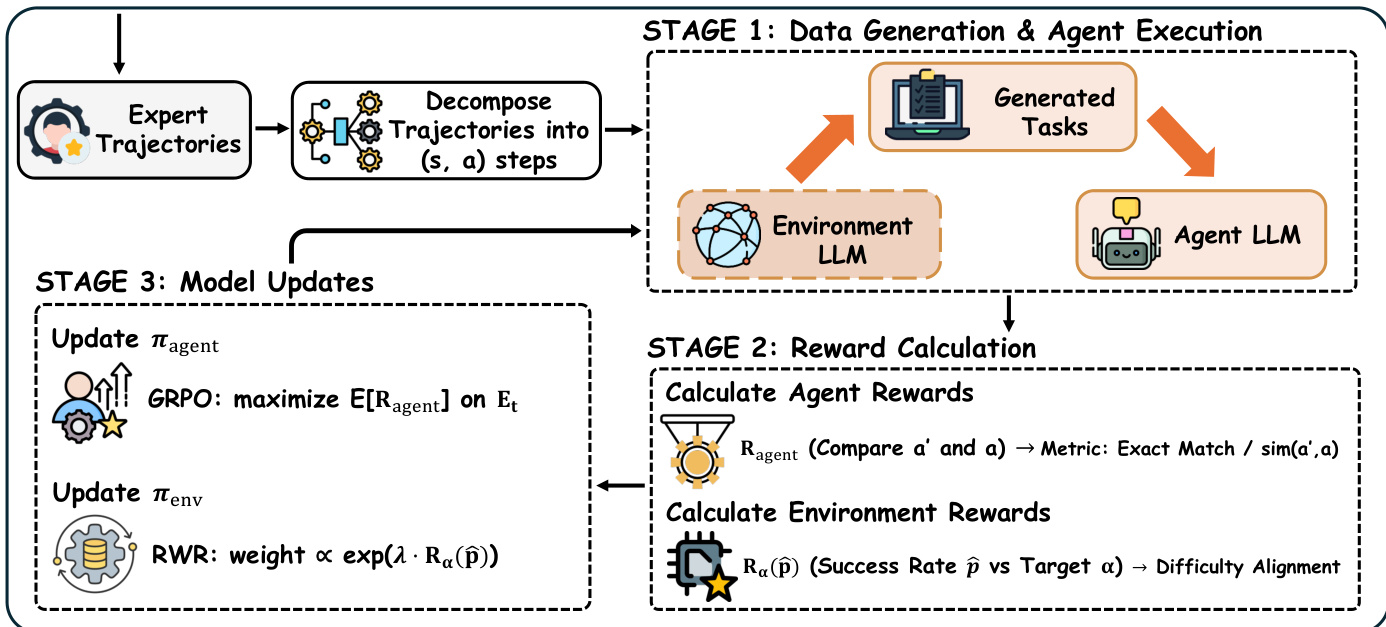
This architecture enables the environment simulator to learn to generate tasks that target the agent’s “zone of proximal development,” maximizing the learning signal for the agent while maintaining data efficiency. Theoretical analysis confirms that intermediate difficulty tasks (where success probability p(τ)=0.5) yield the strongest gradient signal for policy updates, and the α-Curriculum Reward provides a statistically consistent signal for ranking task difficulty, ensuring the simulator converges to generating optimally challenging tasks over time.
Experiment
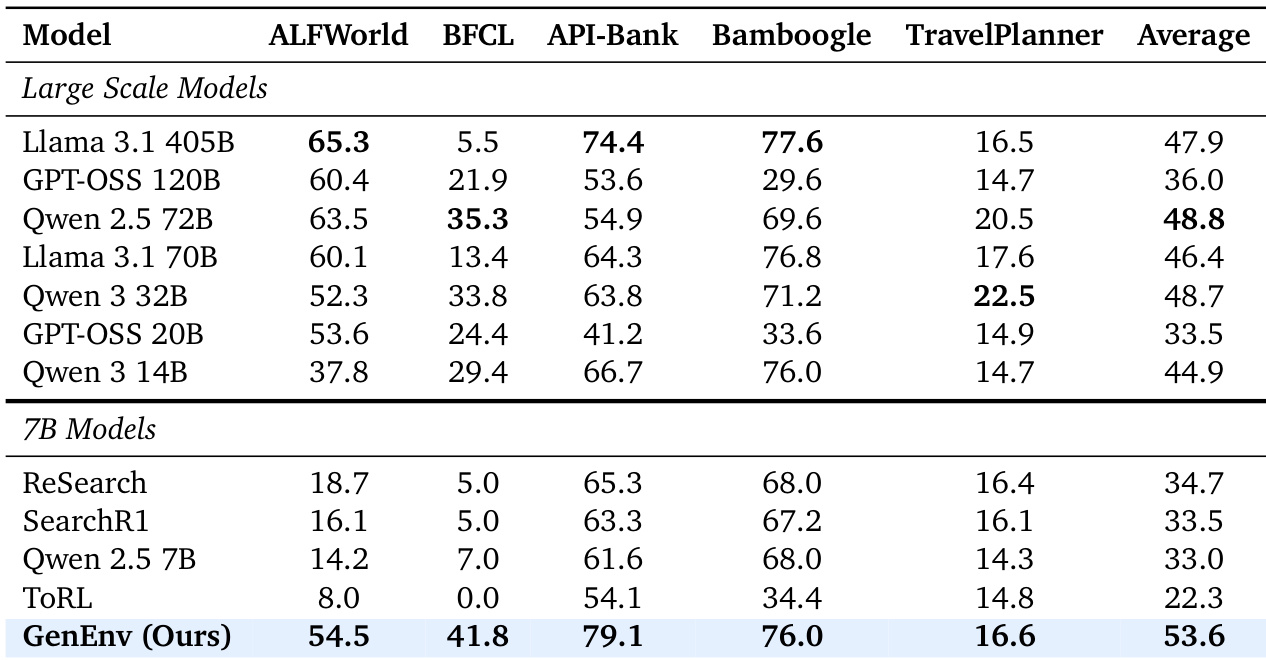
- GenEnv (7B) outperforms all 7B baselines across five benchmarks, achieving 54.5% on ALFWORLD (vs 14.2% base) and 79.1% on API-Bank, with an average score of 53.6 that surpasses the average performance of several 72B/405B models.
- The co-evolutionary process validates emergent curriculum learning, where task complexity (measured by response length) increases by 49% during training while maintaining stable success rates, confirming difficulty-aligned progression.
- GenEnv demonstrates superior data efficiency, exceeding Gemini-Offline (3.3x data) by 2.0% in validation score using only dynamically generated on-policy data, and outperforming GenEnv-Random by 12.3% due to reward-guided simulation.
- The α-Curriculum Reward successfully calibrates task difficulty, with agent success rates converging to the target band [0.4, 0.6] around α=0.5, ensuring tasks remain in the zone of proximal development throughout training.
The authors use GenEnv, a 7B model trained with a co-evolving environment simulator, to outperform other 7B baselines and match or exceed the average performance of several larger models up to 405B parameters across five diverse benchmarks. Results show GenEnv achieves 54.5% on ALFWorld and 79.1% on API-Bank, significantly improving over static-data baselines and demonstrating that difficulty-aligned data generation can rival or surpass scaling model size alone. The framework’s emergent curriculum and stable training dynamics enable this performance without reward collapse or manual difficulty scheduling.