Command Palette
Search for a command to run...
주의는 당신이 필요로 하는 것이 아님
주의는 당신이 필요로 하는 것이 아님
Zhang Chong
초록
시퀀스 모델링의 기본적인 질문을 다시 고찰한다: 강력한 성능과 추론 능력을 위해서 실제로 명시적인 자체 주목(self-attention)이 필요할까? 우리는 기존의 다중 헤드 주목(multi-head attention)이 텐서 상승(tensor lifting)의 형태로 이해되어야 한다고 주장한다. 즉, 숨겨진 벡터들이 쌍별 상호작용의 고차원 공간으로 매핑되며, 그 후 경사 하강법을 통해 이 상승된 텐서에 대한 제약 조건을 학습함으로써 모델이 발전한다. 이 메커니즘은 매우 표현력이 풍부하지만 수학적으로는 명확하지 않다. 많은 층을 거치면서 모델의 동작을 작은 명시적 불변량의 집합으로 설명하는 것은 매우 어렵게 된다.이 대안을 탐구하기 위해, 그라스만 흐름(Grassmann flows) 기반의 주목 없는 아키텍처를 제안한다. 주목 행렬을 L×L 크기로 형성하는 대신, 우리의 인과적 그라스만 층(Causal Grassmann layer)은 (i) 토큰 상태를 선형적으로 축소하고, (ii) 플뤼커 좌표(Plücker coordinates)를 통해 국소적인 토큰 쌍을 그라스만 다양체 상의 이차원 부분공간으로 인코딩하며, (iii) 게이트형 혼합을 통해 이러한 기하학적 특징을 다시 숨겨진 상태에 융합한다. 따라서 정보는 다중 스케일의 국소 창 안에서 낮은 질량의 부분공간들의 제어된 변형을 통해 전파되며, 핵심 계산은 무구조적인 텐서 공간이 아닌 유한 차원의 다양체 위에서 이루어진다.위키텍스트-2 언어 모델링 벤치마크에서, 1300만에서 1800만 개의 파라미터를 가진 순수 그라스만 기반 모델은 크기 대응하는 트랜스포머 모델과 비교해 검증 난이도(perplexity)에서 약 10~15% 내외의 성능을 달성한다. SNLI 자연어 추론 작업에서는 디스틸베르트(DistilBERT) 위에 그라스만-플뤼커 헤드를 적용한 모델이 트랜스포머 헤드보다 약간 더 뛰어난 성능을 보였으며, 최고 검증 정확도는 0.8550, 테스트 정확도는 0.8538을 기록했고, 트랜스포머 헤드의 최고 성능인 0.8545 및 0.8511보다 각각 약간 우수하였다. 우리는 그라스만 혼합의 복잡도를 분석하고, 고정된 질량에서 시퀀스 길이에 대해 선형 스케일링이 발생함을 보였으며, 이러한 다양체 기반 설계가 신경망 추론의 기하학적 및 불변량 기반 해석으로 나아가는 더 구조적인 접근법을 제공할 수 있다고 주장한다.
One-sentence Summary
The authors propose a novel attention-free sequence model based on Grassmann flows, leveraging low-rank subspace dynamics on Gr(2, r) and Plücker embeddings to enable geometric, linearly scalable information fusion—achieving competitive performance on language modeling and natural inference tasks while offering a more analytically tractable alternative to dense self-attention.
Key Contributions
-
The paper challenges the assumption that dense or approximate self-attention is essential for strong language modeling, reframing attention as a high-dimensional tensor lifting operation that obscures model behavior due to its analytical intractability across layers and heads.
-
It introduces a novel attention-free architecture based on Grassmann flows, where local token pairs are modeled as 2D subspaces on a Grassmann manifold Gr(2, r), embedded via Plücker coordinates and fused through a gated mixing block, enabling geometric evolution of hidden states without explicit pairwise weights.
-
Evaluated on Wikitext-2 and SNLI, the Grassmann-based model achieves competitive performance—within 10–15% of a Transformer baseline in perplexity and slightly better accuracy in classification—while offering linear complexity in sequence length for fixed rank, contrasting with the quadratic cost of self-attention.
Introduction
The authors challenge the foundational role of self-attention in sequence modeling, which has become the default mechanism in Transformers due to its expressiveness and parallelizability. While prior work has focused on optimizing attention—reducing its quadratic complexity through sparsification, approximation, or memory augmentation—these approaches still rely on computing or approximating an L×L attention matrix. The key limitation is that attention is treated as indispensable, despite being just one way to implement geometric lifting of representations. The authors propose Grassmann flows as a fundamentally different alternative: instead of pairwise interactions via attention, they model sequence dynamics through the evolution of subspaces on a Grassmann manifold, using Plücker coordinates to encode geometric relationships. This approach eliminates the need for explicit attention entirely, offering a geometry-driven mechanism for sequence modeling that is both mathematically principled and computationally efficient. Their main contribution is integrating this Grassmann–Plücker pipeline into a Transformer-like architecture, demonstrating that geometric mixing can replace attention while preserving strong performance, with potential for future extensions incorporating global invariants.
Dataset
- The dataset used is Wikitext-2-raw, a widely adopted benchmark for language modeling tasks.
- Text sequences are created by splitting the raw text into contiguous chunks of fixed length, with block sizes of either 128 or 256 tokens.
- A WordPiece-like vocabulary of approximately 30,522 tokens is employed, consistent with BERT-style tokenization.
- The authors compare two model architectures: TransformerLM, a standard decoder-only Transformer, and GrassmannLM, which replaces each self-attention block with a Causal Grassmann mixing block.
- Two model depths are evaluated: Shallow (6 layers) and Deeper (12 layers), with both models maintaining identical embedding dimensions (d=256), feed-forward dimensions (d_ff=1024), and 4 attention heads.
- For GrassmannLM, a reduced dimension of r=32 is used, and multi-scale window patterns are applied: {1, 2, 4, 8, 12, 16} for the 6-layer model, and a repeated pattern (1, 1, 2, 2, 4, 4, 8, 8, 12, 12, 16, 16) across layers for the 12-layer model.
- Both models are trained for 30 epochs using the same optimizer and learning rate schedule, differing only in the mixing block type.
- Best validation perplexity is reported across training, with batch sizes of 32 for L=128 and 16 for L=256.
Method
The authors leverage a geometric reinterpretation of self-attention to propose an alternative sequence modeling framework that replaces the standard attention mechanism with a structured, attention-free process based on Grassmann flows. This approach rethinks the core interaction mechanism in sequence models by shifting from unstructured tensor lifting to a controlled geometric evolution on a finite-dimensional manifold. The overall architecture, referred to as the Causal Grassmann Transformer, follows the general structure of a Transformer encoder but substitutes each self-attention block with a Causal Grassmann mixing layer. This layer operates by reducing the dimensionality of token representations, encoding local pairwise interactions as geometric subspaces on a Grassmann manifold, and fusing the resulting features back into the hidden state space through a gated mechanism.
The process begins with token and positional embeddings, where input tokens are mapped to a d-dimensional space using a learned embedding matrix and augmented with positional encodings. This initial sequence of hidden states is then processed through N stacked Causal Grassmann mixing layers. Each layer performs a sequence of operations designed to capture local geometric structure without relying on explicit pairwise attention weights. First, a linear reduction step projects each hidden state ht∈Rd into a lower-dimensional space via zt=Wredht+bred, resulting in Z∈RL×r, where r≪d. This reduction step serves to compress the representation while preserving essential local information.
As shown in the figure below, the framework proceeds by constructing local pairs of reduced states (zt,zt+Δ) for a set of multi-scale window sizes W, such as {1,2,4,8,12,16}, ensuring causality by only pairing each position t with future positions. For each such pair, the authors interpret the span of the two vectors as a two-dimensional subspace in Rr, which corresponds to a point on the Grassmann manifold Gr(2,r). This subspace is encoded using Plücker coordinates, which are derived from the exterior product of the two vectors. Specifically, the Plücker vector pt(Δ)∈R(2r) is computed as pij(Δ)(t)=zt,izt+Δ,j−zt,jzt+Δ,i for 1≤i<j≤r. These coordinates represent the local geometric structure of the pair in a finite-dimensional projective space, subject to known algebraic constraints.
The Plücker vectors are then projected back into the model's original dimensionality through a learned linear map gt(Δ)=Wplu¨p^t(Δ)+bplu¨, where p^t(Δ) is a normalized version of the Plücker vector for numerical stability. The resulting features are aggregated across all valid offsets at each position t to form a single geometric feature vector gt. This vector captures multi-scale local geometry and is fused with the original hidden state ht via a gated mechanism. The gate αt is computed as σ(Wgate[ht;gt]+bgate), and the mixed representation is given by h~tmix=αt⊙ht+(1−αt)⊙gt. This fusion step allows the model to adaptively combine the original representation with the geometric features.
Following the gated fusion, the representation undergoes layer normalization and dropout. A position-wise feed-forward network, consisting of two linear layers with a GELU nonlinearity and residual connections, further processes the hidden states. The output of this block is normalized and serves as the updated hidden state for the next layer. This entire process is repeated across N layers to form the full Causal Grassmann Transformer.
The key distinction from standard self-attention lies in the absence of an L×L attention matrix and the associated quadratic complexity. Instead of computing pairwise compatibility scores across all token positions, the model operates on a finite-dimensional manifold with controlled degrees of freedom. The complexity of the Grassmann mixing layer scales linearly in sequence length for fixed rank r and window size m, in contrast to the quadratic scaling of full self-attention. This linear scaling arises because the dominant cost is the O(Ld2) term from the feed-forward network and linear operations, while the Plücker computation and projection contribute O(Lmr2), which is subdominant for fixed r and m. The authors argue that this shift from tensor lifting to geometric flow provides a more interpretable and analytically tractable foundation for sequence modeling, as the evolution of the model's behavior can be studied as a trajectory on a well-defined manifold rather than a composition of high-dimensional, unstructured tensors.
Experiment
- On Wikitext-2 language modeling, GrassmannLM achieves validation perplexity of 275.7 (6-layer) and 261.1 (12-layer), remaining within 10–15% of size-matched TransformerLMs despite using no attention, with the gap narrowing at greater depth.
- On SNLI natural language inference with a DistilBERT backbone, the Grassmann-Plücker head achieves 85.50 validation and 85.38 test accuracy, slightly outperforming the Transformer head (85.45 validation, 85.11 test).
- The Grassmann architecture demonstrates viability as an attention-free sequence model, with comparable parameter counts and consistent performance across settings, validating that geometrically structured local mixing can support semantic reasoning.
- Empirical runtime remains slower than Transformer baseline due to unoptimized implementation, though theoretical complexity is linear in sequence length, indicating potential for future scaling gains with specialized optimization.
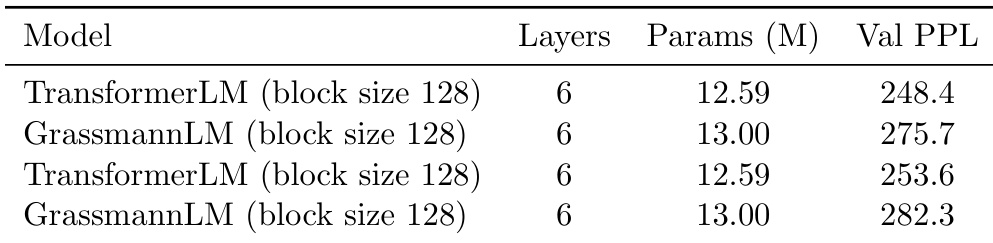
The authors use the table to compare the performance of TransformerLM and GrassmannLM on the Wikitext-2 language modeling task under identical conditions. Results show that the GrassmannLM achieves higher validation perplexity than the TransformerLM, with values of 275.7 and 282.3 compared to 248.4 and 253.6, respectively, indicating that the Grassmann model performs worse despite having slightly more parameters.
The authors use a 12-layer model with block size 256 to compare TransformerLM and GrassmannLM on language modeling. Results show that GrassmannLM achieves a validation perplexity of 261.1, which is higher than the TransformerLM's 235.2, indicating a performance gap under these conditions.

The authors use a DistilBERT backbone with two different classification heads—Transformer and Grassmann-Plücker—to evaluate performance on the SNLI natural language inference task. Results show that the Grassmann-Plücker head achieves slightly higher validation and test accuracy compared to the Transformer head, indicating that explicit geometric structure in the classification head can improve performance on downstream reasoning tasks.
