Command Palette
Search for a command to run...
대규모 비디오 플래너를 통한 일반화 가능한 로봇 제어
대규모 비디오 플래너를 통한 일반화 가능한 로봇 제어
초록
일반 목적의 로봇은 다양한 작업과 환경에 걸쳐 일반화할 수 있는 결정 모델을 필요로 한다. 최근 연구들은 다중모달 대규모 언어 모델(Multimodal Large Language Models, MLLMs)에 행동 출력을 추가함으로써 로봇 기초 모델을 구축하는 방식을 탐구해 왔으며, 이를 시각-언어-행동(Vision-Language-Action, VLA) 시스템이라 한다. 이러한 접근은 MLLMs의 대규모 언어 및 이미지 사전 학습이 행동 출력 모달로 효과적으로 전이될 수 있다는 직관에 기반한다. 본 연구에서는 로봇 기초 모델을 구축하기 위한 주요 모달로 대규모 영상 사전 학습을 활용하는 대안적 패러다임을 탐구한다. 정적인 이미지와 언어와 달리, 영상은 물리 세계의 상태와 행동에 대한 시공간적 시퀀스를 자연스럽게 포착하며, 이는 로봇 행동과 본질적으로 일치한다. 우리는 인간의 활동과 작업 시연을 포함하는 인터넷 규모의 영상 데이터셋을 구축하고, 기초 모델 수준에서 처음으로 생성형 로봇 계획을 위한 오픈 영상 모델을 학습하였다. 이 모델은 새로운 장면과 작업에 대해 제로샷 영상 계획을 생성하며, 이를 후처리하여 실행 가능한 로봇 행동으로 추출한다. 우리는 실제 환경에서 제3자 선택 작업과 실제 로봇 실험을 통해 작업 수준의 일반화 능력을 평가하였으며, 성공적인 물리적 실행을 입증하였다. 이러한 결과들은 강력한 지시 수행 능력, 뛰어난 일반화 성능 및 실제 적용 가능성의 가능성을 보여준다. 본 연구에서는 모델과 데이터셋을 공개하여 영상 기반 로봇 학습의 개방성과 재현 가능성을 지원한다.
One-sentence Summary
The authors from MIT, UC Berkeley, and Harvard propose a large-scale video-based foundation model for robotic planning, leveraging internet-scale video pretraining to generate zero-shot video plans that enable robust instruction following and real-world task execution, marking a shift from vision-language-action models by using spatio-temporal video sequences as the primary modality for generative robotics planning.
Key Contributions
- This work introduces a novel paradigm for robot foundation models by leveraging large-scale video pretraining as the primary modality, directly capturing spatio-temporal sequences of states and actions that are inherently aligned with robotic behavior, in contrast to prior vision-language-action models relying on static images and language.
- The authors develop Large Video Planner (LVP), a video generation model enhanced with History Guidance and Diffusion Forcing to ensure physical consistency and causal coherence in generated motion plans, enabling zero-shot video-based planning from a single image and natural language instruction.
- They release an open, internet-scale video dataset of human and robot task demonstrations, and demonstrate strong task-level generalization through third-party evaluations and real-robot experiments across diverse, unstructured environments, achieving successful end-to-end physical execution.
Introduction
The authors leverage large-scale video pretraining as a foundation for robotic planning, addressing the limitations of existing Vision-Language-Action (VLA) models that rely on scarce robot data and asymmetric transfer from language and vision models. Unlike static image-text pairs, videos naturally encode spatio-temporal state-action sequences, offering a more direct and physically grounded representation of robotic behavior. The key challenge in prior work is the lack of sufficient, diverse, and temporally coherent action data for training robust, generalizable policies. To overcome this, the authors introduce the Large Video Planner (LVP), a video generation model trained on a newly curated, open internet-scale dataset of human and robot task demonstrations. The model generates zero-shot video plans from a single image and natural language instruction, which are then post-processed via 3D scene reconstruction and hand retargeting to extract executable robot actions. This approach enables strong task-level generalization across diverse, unseen environments and tasks, validated through independent evaluations and real-robot experiments with both parallel grippers and dexterous hands.
Dataset

-
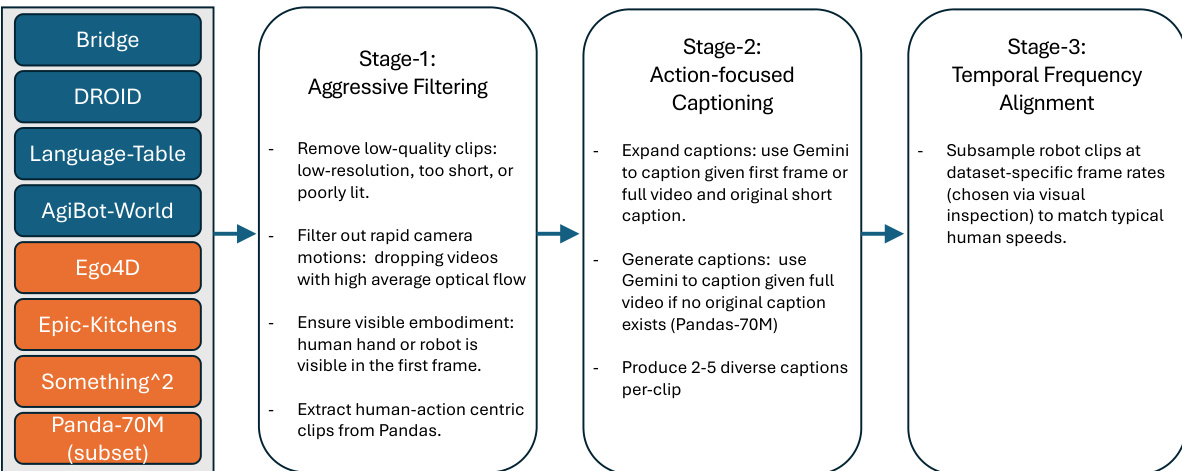
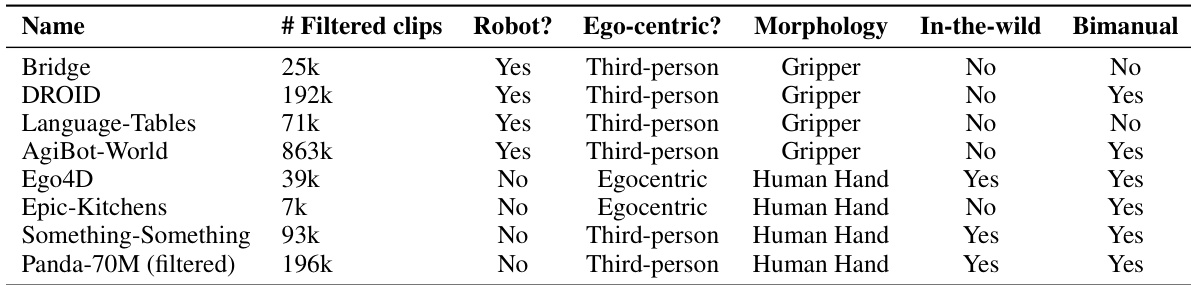
The LVP-1M dataset comprises 1.4 million short video clips of human and robot interactions with objects, each paired with multiple action-centric text captions. It is built from three main sources: web-crawled videos (Pandas-70M), egocentric human activity datasets (Ego4D, Epic Kitchens, Something-Something), and robotics teleoperation datasets (Bridge, Droid, Language Table, AgiBot-World), ensuring diversity in embodiment, viewpoint, scene type, and task complexity.
-
The Pandas-70M subset contributes 196K clips after three-stage filtering: keyword-based selection using a whitelist (e.g., "grasping", "pull") and blacklist (e.g., "cartoon", "video game"), human pose detection to retain clips with 1–3 visible humans, and Gemini-2.0 Flash evaluation on four criteria: rich hand motion, meaningful action, normal playback speed, and no scene changes.
-
Egocentric datasets (Ego4D, Epic Kitchens, Something-Something) contribute medium-scale clips with moderate diversity but high background motion. These are filtered using optical flow to remove clips with rapid camera movements (top 30% highest spatio-temporal average flow), and action boundaries are refined to match atomic actions.
-
Robotics datasets (Bridge, Droid, Language Table, AgiBot-World) provide robot-specific interactions but suffer from low visual quality, inconsistent frame rates, and vague or missing captions. These are heavily re-captioned using Gemini Flash, with prompts based on the initial frame or full clip to generate detailed, action-focused descriptions.
-
All clips are temporally aligned to a 3-second duration at 16 frames per second to standardize action duration and ensure human-speed consistency, regardless of original recording speed. Long-horizon tasks are split into atomic actions, and frame rates are resampled via upsampling or speeding up to match human motion timing.
-
Quality filtering removes low-resolution, poorly lit, or overly short/long clips. Additional filters ensure visible embodiment (hand or gripper) in the first frame via object detection, exclude failure trajectories in robot data, and remove videos with rapid camera motion.
-
Each video is paired with 2–5 distinct captions—ranging from concise to highly descriptive—generated using Gemini Flash, with prompts including task descriptions (e.g., "pick up a cup") to improve action accuracy. This enhances linguistic diversity and instruction-following robustness.
-
The dataset is used in training with a mixture ratio based on weighted sampling: AgiBot-World (0.05), Droid (0.5), Ego4D (0.75), Pandas (filtered) (1.5), SomethingSomething (0.5), Bridge (1.0), Epic-Kitchens (2.0), Language Table (0.375), ensuring balanced contribution despite size disparities.
-
During training, each sample is a 49-frame video at 832×480 resolution, encoded into VAE latents of shape 104×60×13. The model is pre-trained for 60,000 iterations with a warmup and constant learning rate of 1×10⁻⁵, then fine-tuned for 10,000 iterations at 2.5×10⁻⁶.
-
For evaluation, 100 high-quality, out-of-distribution tasks are crowd-sourced from third-party participants, requiring a photo of the scene, a 3–5 second task description, and creative, non-routine manipulation tasks. Low-quality submissions are filtered out, and final instructions are refined using Gemini.
Method
The authors leverage a two-stage framework for robot foundation modeling, where a large video planner generates motion plans conditioned on observations and goals, followed by an action extraction pipeline that translates these plans into executable robot actions. The core of the system is the Large Video Planner (LVP), a 14-billion parameter video foundation model built upon a latent diffusion framework. The overall architecture begins with a temporally causal 3D variational autoencoder (VAE) that compresses input video clips into a compact, lower-dimensional latent representation. This VAE encodes spatiotemporal patches, transforming an input video of shape [1+T,3,H,W] into a latent of shape [1+⌈T/4⌉,16,⌈H/4⌉,⌈W/4⌉], where the first frame is repeated four times to enable co-training with single-frame image data. The VAE is frozen, and a diffusion transformer is trained in this latent space to generate videos. The model is trained using a flow matching objective, where Gaussian noise is added to a clean video latent z0 to create a noisy latent zk=(1−k)z0+kϵ, and the model learns to predict the flow ϵ−z0 conditioned on the noisy latent, text instruction, and noise level.
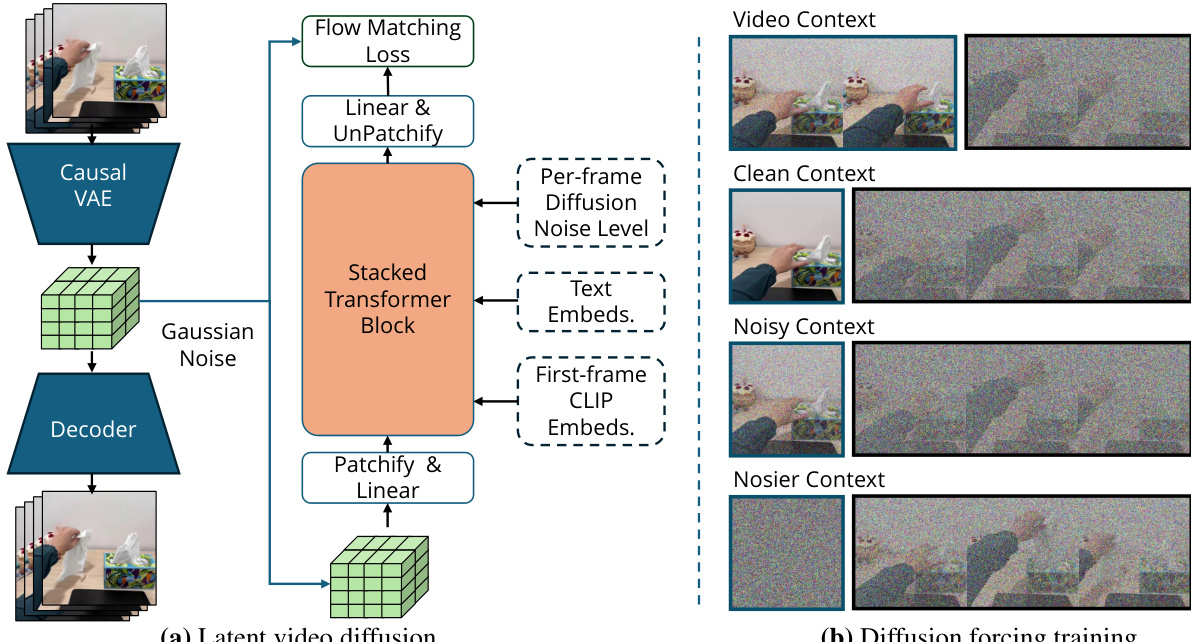
Refer to the framework diagram, which illustrates the complete pipeline. The diffusion transformer, a DiT variant, is trained with a modified Diffusion Forcing strategy to enable flexible conditioning on both image and video contexts. This approach allows the model to be conditioned on a clean first frame (image-to-video) or multiple history frames (video-to-video) by applying different noise levels to the context and future segments. During training, a random context length between 0 and 6 frames is selected, and independent noise levels are applied to the history and future segments. The history segment is set to zero noise with a 50% probability, enabling the model to learn to condition on clean or noisy context frames. This method eliminates the need for extra cross-attention mechanisms and is compatible with pre-trained model weights. The model is further enhanced with history guidance, a variant of classifier-free guidance, which combines the scores from conditional and unconditional sampling to improve adherence to both the text instruction and the context frames, resulting in more coherent and physically viable video plans.
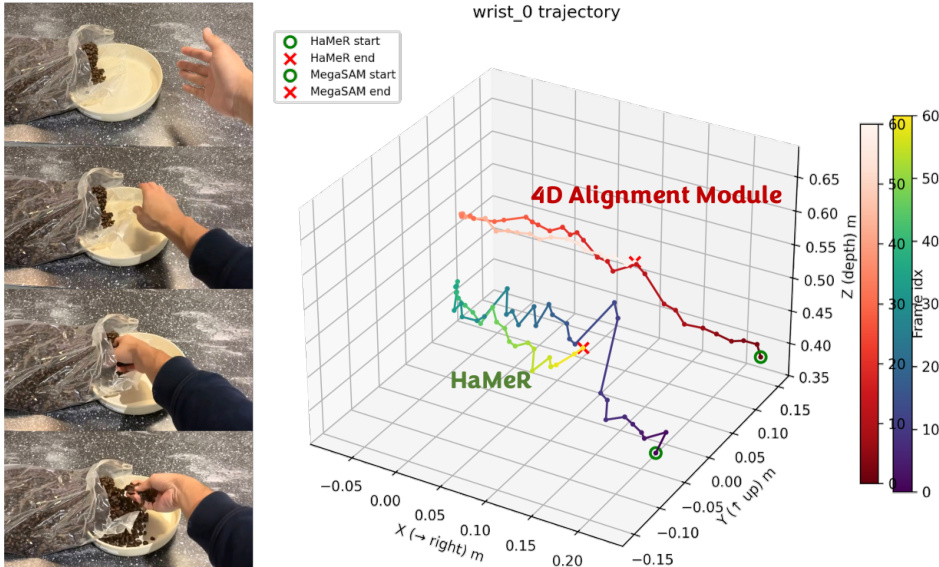
The action extraction pipeline converts the generated human hand video plans into executable robot actions. The process begins with human hand motion estimation, where a per-frame hand pose is predicted using the HaMeR model, which regresses MANO hand vertices and wrist orientation. However, due to monocular scale ambiguity and lack of temporal consistency, the predicted translations drift over time. To resolve this, a 4D reconstruction model, MegaSAM, is used to estimate per-frame depth maps and camera poses. The wrist position is then backprojected from the image plane into 3D using the depth and camera intrinsics, and the resulting pointclouds are used to estimate a temporally smooth translation, while the orientation from HaMeR is retained. This 4D alignment module significantly improves wrist localization robustness and temporal consistency.
The estimated hand pose is then used for robot finger motion retargeting. For dexterous hands, the authors use Dex-Retargeting, which maps human hand keypoints to robot joint configurations by solving an optimization objective, producing robot finger joint angles. The resulting wrist trajectories and finger joint sequences are expressed in the camera coordinate frame of the first video frame. To execute the motion on a physical robot, the wrist poses are aligned to the robot control frame via a fixed rotation that unifies the axes of the camera and robot frames. The wrist trajectory is then used to solve inverse kinematics for the robot arm, while the finger joint sequence directly drives the robot hand controller. The final step involves real-robot execution, where the synchronized arm and hand trajectories are sent to the robot control API to complete the task. The pipeline also supports retargeting to parallel-jaw grippers by using GraspNet to predict grasp poses and heuristics to detect grasping intent from the human motion.
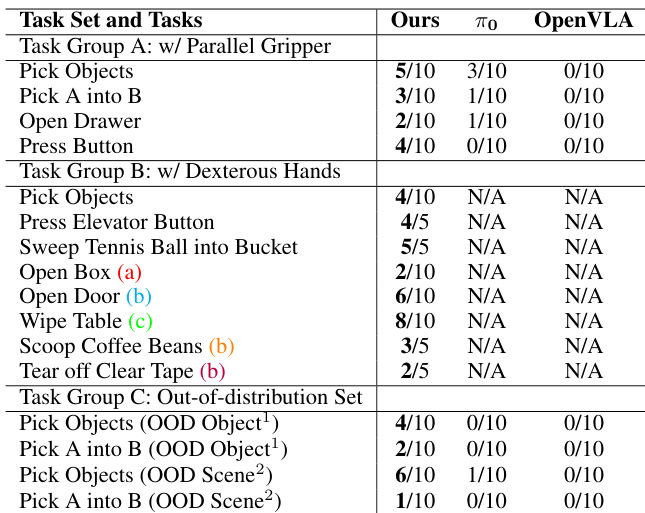
Experiment
- Evaluated video motion planning on a 100-sample in-the-wild test set using a four-level metric: correct contact (Level 1), correct end state (Level 2), task complete (Level 3), and perfect task complete (Level 4). Our method achieved a 59.3% success rate at Level 3, significantly outperforming baselines Wan 2.1 I2V 14B, Cosmos-Predict 2 14B, and Hunyuan I2V 13B, especially in generating coherent, physically consistent long-horizon motion plans via iterative video extension.
- Demonstrated zero-shot real-world robot manipulation on two platforms: Franka Arm with parallel-jaw gripper and Unitree G1 with Inspire dexterous hand. Our method achieved strong generalization on challenging tasks such as scooping coffee beans and tearing tape, outperforming baselines π0 and OpenVLA, which struggled with out-of-distribution and complex dexterous manipulation tasks.
- Achieved successful action retargeting and execution across diverse tasks, with qualitative results showing accurate video plan generation and real-world robot performance, including in-hand rotation, tool use, and precise placement, validating the end-to-end pipeline’s robustness.
The authors use a table to compare different datasets based on their characteristics, including the number of filtered clips, whether they involve robots, perspective, morphology, in-the-wild conditions, and bimanual tasks. The table shows that datasets like Bridge, DROID, and Language-Tables are robot-based, third-person, and use grippers, while others such as Ego4D and Epic-Kitchens are non-robotic, egocentric, and involve human hands.
Results show that the proposed method achieves significantly higher success rates than the baselines across all evaluation levels, with the largest improvements at Level 3 (Task Complete) and Level 4 (Perfect), indicating superior generation of coherent, task-complete, and physically realistic video plans. The authors use a four-level evaluation metric to assess instruction following, motion feasibility, and physical realism, and their model attains a 59.3% success rate at Level 3, demonstrating strong zero-shot generalization in in-the-wild settings.

The authors evaluate their video planner on real-world robot manipulation tasks using two platforms: a Franka Arm with a parallel-jaw gripper and a G1 humanoid with a dexterous hand. Results show that their method achieves higher success rates than baselines across both platforms, particularly excelling in complex dexterous manipulation tasks and out-of-distribution scenarios.