Command Palette
Search for a command to run...
MIMIC-Video: 비디오-행동 모델을 활용한 VLAs를 넘어서는 일반화 가능한 로봇 제어
MIMIC-Video: 비디오-행동 모델을 활용한 VLAs를 넘어서는 일반화 가능한 로봇 제어
Jonas Pai Liam Achenbach Victoriano Montesinos Benedek Forrai Oier Mees Elvis Nava
초록
로봇 조작을 위한 주류의 시각-언어-행동 모델(VLAs)은 대규모이지만 고립된 정적 웹 데이터를 기반으로 사전 훈련된 시각-언어 백본에 기반하고 있다. 이로 인해 의미론적 일반화는 향상되었지만, 정책은 로봇의 경로에서 복잡한 물리적 역학과 시간적 의존성을 암묵적으로 추론해야 하는 부담을 안고 있다. 이러한 의존성은 지속적인 대규모 전문가 데이터 수집을 필요로 하며, 내재된 물리적 이해 부족을 보완해야 하는 비지속적인 데이터 부담을 초래한다. 우리는 시각-언어 사전 훈련이 의미론적 사전 지식을 효과적으로 포착할 수는 있지만, 물리적 인과관계에는 여전히 무지하다고 주장한다. 더 효과적인 접근 방식은 사전 훈련 과정에서 영상 데이터를 활용하여 의미론과 시각적 동역학을 함께 포착하는 것이다. 이를 통해 저수준 제어의 잔여 과제를 분리할 수 있다. 이를 달성하기 위해 우리는 사전 훈련된 인터넷 규모의 영상 모델과, 그 잠재 표현을 조건으로 하는 흐름 매칭 기반의 액션 디코더를 결합한 새로운 영상-행동 모델(VAM)인 mimic-video를 제안한다. 이 디코더는 역역학 모델(IDM)의 역할을 하며, 영상 공간 내 액션 계획의 잠재 표현에서 저수준 로봇 동작을 생성한다. 광범위한 평가 결과, 제안하는 방법은 시뮬레이션 및 실제 세계의 로봇 조작 과제에서 최신 기술 수준의 성능을 달성하였으며, 기존의 VLA 아키텍처에 비해 샘플 효율성을 10배 향상시키고 수렴 속도를 2배 빠르게 하는 결과를 보였다.
One-sentence Summary
The authors, affiliated with mimic robotics, Microsoft Zurich, ETH Zurich, ETH AI Center, and UC Berkeley, introduce mimic-video, a novel Video-Action Model that grounds robotic policies in a pretrained video diffusion backbone, enabling state-of-the-art performance in dexterous manipulation with 10x greater sample efficiency and 2x faster convergence than Vision-Language-Action models by using a flow-matching-based inverse dynamics decoder conditioned on partially denoised video latents—bypassing the need for full video generation and leveraging innate physical priors from internet-scale video pretraining.
Key Contributions
- Existing Vision-Language-Action (VLA) models rely on static image-text pretraining, which lacks inherent physical dynamics, forcing the policy to learn complex temporal and causal relationships from scarce robot demonstrations, resulting in poor sample efficiency and high data demands.
- The paper introduces mimic-video, a new Video-Action Model (VAM) that leverages a pretrained video diffusion backbone to generate latent visual plans, using a flow-matching-based action decoder as an inverse dynamics model to directly recover low-level robot actions from these representations, thereby decoupling high-level planning from control.
- Evaluated across simulated and real-world manipulation tasks, mimic-video achieves state-of-the-art performance with 10x higher sample efficiency and 2x faster convergence compared to traditional VLA architectures, demonstrating the benefits of grounding policies in video-based dynamic priors.
Introduction
The authors leverage pretrained video models to address a key limitation in current Vision-Language-Action (VLA) models for robotics: the lack of inherent physical dynamics understanding due to reliance on static image-text pretraining. While VLAs excel at semantic generalization, they must learn complex temporal and physical interactions from scarce robot demonstrations, leading to poor sample efficiency and high data demands. To overcome this, the authors introduce mimic-video, a new class of Video-Action Model (VAM) that grounds robot policies in the latent representations of a frozen, internet-scale video diffusion model. The model generates a visual action plan in latent space and uses a flow-matching-based action decoder—functioning as an Inverse Dynamics Model—to directly map these representations to low-level robot actions. This decouples high-level planning from control, allowing the action decoder to focus on a simpler, non-causal inverse dynamics task. The approach achieves state-of-the-art performance on dexterous manipulation tasks while improving sample efficiency by 10x and convergence speed by 2x compared to traditional VLAs, demonstrating that rich video priors can drastically reduce the need for expert robot data.
Dataset
- The dataset combines three sources: BridgeDataV2, LIBERO, and mimic, each contributing diverse robotic manipulation data.
- BridgeDataV2 consists of 3,046 non-informative language labels and the first state and null-action of each episode removed, resulting in a cleaned subset focused on meaningful task demonstrations.
- LIBERO data is preprocessed following Kim et al. [27], excluding episodes that fail when replaying actions, ensuring only successful rollouts are retained.
- mimic includes observations of end-effector poses, hand joint states, relative end-effector positions, and prior actions, with actions defined as relative end-effector movements and absolute hand joint commands.
- All images are rendered at 480 x 640 pixels, and orientations are represented as 6D vectors derived from the top two rows of rotation matrices.
- The authors use a mixture of these datasets for training, combining them with specific ratios to balance task diversity and performance.
- During training, the data is processed to align observation and action spaces, with relative action representations used consistently across all subsets to improve generalization.
Method
The authors leverage a two-stage architecture for their Video-Action Model (VAM), which couples a pretrained video generation backbone with a lightweight action decoder. This framework is built upon the principles of Conditional Flow Matching (CFM), enabling the model to learn the joint distribution of video and robot actions. The overall architecture is designed to efficiently ground robotic policies in a pretrained video model, thereby leveraging rich physical dynamics priors learned from large-scale video data.
The core of the model consists of two distinct components: a video model and an action decoder. The video model, instantiated as a pretrained 2B-parameter latent Diffusion Transformer (DiT) named Cosmos-Predict2, operates on sequences of video frames encoded by a 3D-tokenizer. It processes a concatenation of clean latent patch embeddings from a context prefix (typically five frames) and noisy latent patches representing future frames. Each transformer layer within this model alternates between self-attention over the full video sequence, cross-attention to language instructions encoded by a T5 model, and a two-layer MLP. This architecture allows the video model to generate plausible future video frames conditioned on the current observation and a language instruction.
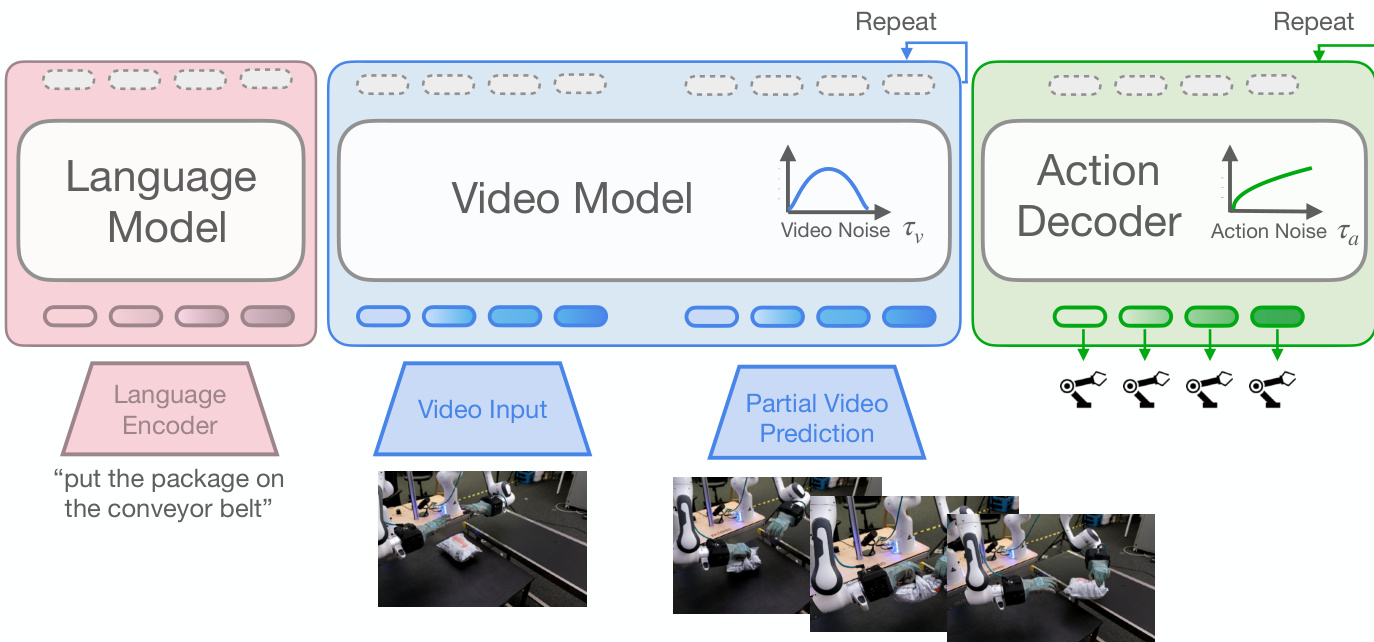
The action decoder is a smaller DiT that predicts a sequence of robot actions. It encodes the robot's proprioceptive state and a sequence of future actions through separate MLP networks, which are then concatenated. The decoder incorporates learned absolute positional encodings to capture temporal information. During training, a learned mask token is used to replace the proprioceptive state encoding, preventing overfitting. The action decoder's layers consist of cross-attention to intermediate video model representations, self-attention over the action sequence, and a two-layer MLP. Each component is bypassed by a residual path, and the outputs are modulated via AdaLN, where the modulation parameters are derived from a low-rank bilinear-affine encoding of the video and action flow times, τv and τa.
The two components are coupled through a partial denoising strategy. The video model is integrated from a Gaussian noise state at τ=1 to an intermediate flow time τv to extract latent visual plans. These representations, denoted as htauv, are then used to condition the action decoder. The video and action components operate on independent flow schedules, τv and τa, allowing for separate design and training of the learning problem for each modality. This decoupling is central to the model's efficiency, as it enables the action decoder to be trained and executed independently of the computationally intensive video generation process.
The training process proceeds in two distinct phases. The first phase involves finetuning the video backbone using Low-Rank Adapters (LoRA) on robotics video datasets. This step aligns the generalist backbone with the specific visual domain and dynamics of robotic tasks while preserving its pretrained temporal reasoning capabilities. The second phase focuses on training the action decoder from scratch, with the video backbone frozen. During this phase, the decoder learns to regress the action flow field conditioned on the video representations htauv. To ensure robustness to varying noise levels during inference, the training samples independent flow times τv and τa for each iteration, using a logit-normal distribution for the video flow time and a taua−0.001 distribution for the action flow time. This decoupled training scheme significantly enhances sample efficiency and convergence speed compared to standard VLA baselines.
Experiment
- Evaluated on SIMPLER-Bridge, LIBERO, and real-world bimanual manipulation tasks, mimic-video demonstrates strong cross-embodiment generalization and high sample efficiency.
- On SIMPLER-Bridge, mimic-video achieves the highest average success rate, outperforming state-of-the-art baselines including the π0.5-style VLA, validating the superiority of video backbone conditioning.
- On LIBERO, mimic-video surpasses multiple state-of-the-art methods trained with larger datasets, achieving higher success rates despite being trained from scratch on minimal task-specific data.
- In real-world bimanual dexterous manipulation, mimic-video significantly outperforms single-task DiT-Block Policies, even when conditioned only on a single workspace camera, demonstrating robustness to occlusion and data scarcity.
- Mimic-video exhibits a 10x improvement in sample efficiency: it reaches peak performance with 10% of the action data required by the π0.5-style VLA baseline, and maintains 77% success rate with just one episode per task.
- The action decoder converges faster and to a higher asymptotic success rate than the VLA baseline, even when the latter benefits from task-specific pretraining.
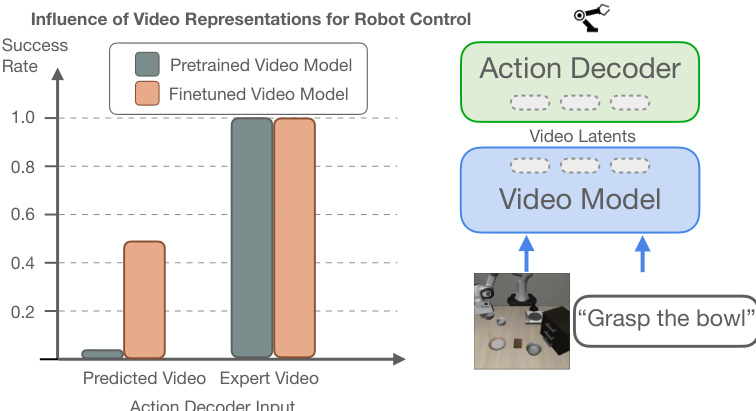
- Counterintuitively, optimal policy performance is achieved at τv=1 (maximum noise), not full denoising, due to distribution mismatch and richer intermediate representations in the video model.
- Conditioning on noisy video latents acts as effective augmentation, improving robustness, while full denoising leads to higher action reconstruction error and degraded performance.
- Intermediate video model layers (e.g., layer 19) and a 5-frame observation horizon yield the best policy performance.
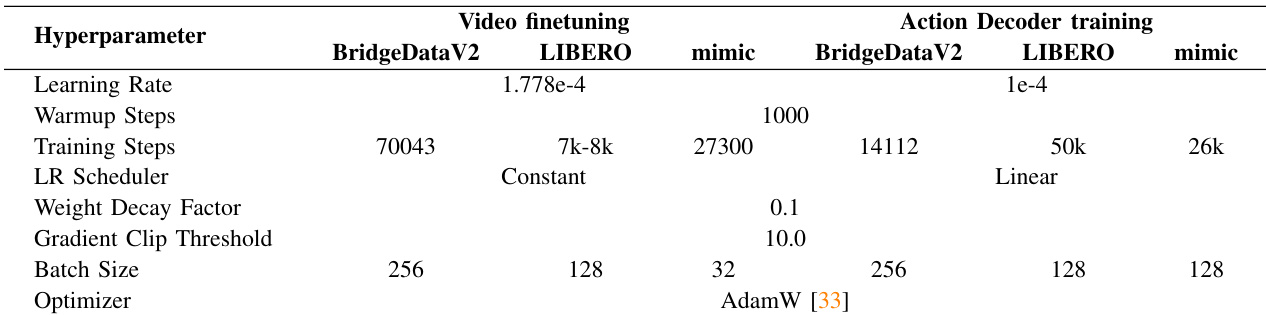
The authors use the provided table to detail the training hyperparameters for mimic-video across different datasets and components, showing that the model employs distinct settings for video finetuning and action decoder training. Results show that the hyperparameters are carefully tuned for each task, with variations in learning rates, batch sizes, and training steps reflecting the specific requirements of BridgeDataV2, LIBERO, and the mimics system.
The authors evaluate mimic-video on a real-world bimanual manipulation task, comparing it to DiT-Block Policy baselines. Results show that mimic-video achieves significantly higher success rates than both DiT-Block Policy variants, despite being conditioned only on a single workspace camera view, demonstrating its ability to handle visual uncertainty and occlusion in contact-rich environments.

Results show that mimic-video achieves the highest average success rate across all tasks on the SIMPLER-Bridge benchmark, outperforming state-of-the-art baselines including Octo, DiT Policy, and OpenVLA-OFT, even when trained from scratch. The model's strong performance demonstrates that conditioning on a generative video backbone enables more robust policy learning compared to vision-language pretrained models, particularly in cross-task generalization scenarios.
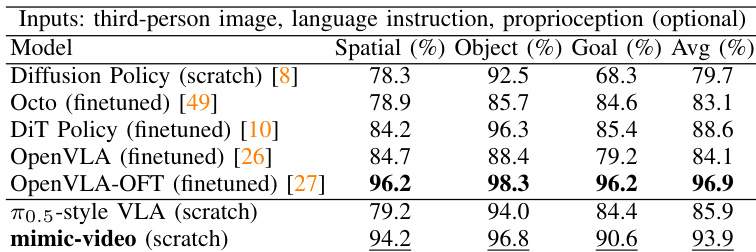
Results show that mimic-video achieves the highest average success rate of 46.9% on the SIMPLER-Bridge benchmark when trained from scratch, outperforming all state-of-the-art baselines including OpenVLA, Octo, ThinkAct, and FLOWER. The model further improves to 56.3% average success rate with task-specific τ_v-tuning, demonstrating that conditioning on a generative video backbone enables superior performance even with minimal task-specific data.
