Command Palette
Search for a command to run...
3D Generation을 위한 Native 및 Compact Structured Latents
3D Generation을 위한 Native 및 Compact Structured Latents
TRELLIS.2 3D 생성 데모
초록
최근 3D generative modeling 분야의 눈부신 발전으로 생성물의 사실성이 크게 향상되었으나, 복잡한 topology와 세밀한 외형을 가진 asset을 구현하는 데 한계가 있는 기존의 representation 방식은 여전히 이 분야의 걸림돌이 되고 있습니다. 본 논문에서는 이러한 문제를 해결하기 위해 네이티브 3D 데이터로부터 구조화된 latent representation을 학습하는 접근 방식을 제안합니다.본 연구의 핵심은 기하학적 구조(geometry)와 외형(appearance)을 모두 인코딩하는 omni-voxel representation인 새로운 sparse voxel 구조, 'O-Voxel'입니다. O-Voxel은 개방형(open), 비매니폴드(non-manifold), 완전히 밀폐된 표면(fully-enclosed surfaces)을 포함한 임의의 topology를 견고하게 모델링할 수 있을 뿐만 아니라, 텍스처 색상을 넘어 물리 기반 렌더링(PBR, physically-based rendering) 파라미터와 같은 포괄적인 표면 속성을 포착할 수 있습니다.O-Voxel을 기반으로, 본 연구에서는 높은 공간 압축률과 컴팩트한 latent space를 제공하는 Sparse Compression VAE를 설계하였습니다. 또한, 다양한 공개 3D asset 데이터셋을 사용하여 3D 생성을 위한 4B 파라미터 규모의 대규모 flow-matching 모델을 학습시켰습니다. 이러한 대규모 모델임에도 불구하고 inference 효율성은 매우 높게 유지됩니다. 동시에, 생성된 asset의 geometry 및 material 품질은 기존 모델을 크게 상회합니다. 본 연구의 접근 방식이 3D generative modeling 분야에서 중요한 진보를 가져올 것이라 확신합니다.
One-sentence Summary
By introducing O-Voxel, a sparse omni-voxel representation that encodes both geometry and physically-based rendering parameters to handle complex topologies, the authors utilize a Sparse Compression VAE and a 4B parameter flow-matching model to achieve efficient 3D generation with superior material and structural detail compared to existing methods.
Key Contributions
- The paper introduces O-Voxel, a sparse omni-voxel representation that encodes both geometry and physically-based rendering parameters to support arbitrary topologies and translucent surfaces. This structure enables instant, optimization-free bidirectional conversion between raw 3D assets and voxels while preserving sharp geometric features.
- A Sparse Compression VAE is designed to learn a compact, structured latent space from the O-Voxel representation using a residual autoencoding design. This method achieves a 16x spatial downsampling rate, allowing a 1024^3 resolution asset to be represented by only 9.6K latent tokens with minimal perceptual loss.
- Large-scale flow-matching generative models totaling 4 billion parameters are developed for high-resolution image-to-3D generation. Experiments demonstrate that these models produce geometry and material quality that exceeds existing methods while maintaining highly efficient inference speeds on high-end GPUs.
Introduction
3D generative modeling is essential for advancing realistic content creation in industrial and digital applications. However, existing methods often rely on iso-surface fields like signed distance functions, which struggle to represent complex, non-manifold, or fully enclosed topologies. Furthermore, many current models focus on shape generation while failing to capture the intricate relationship between geometry and physically-based rendering (PBR) material attributes. The authors address these limitations by introducing O-Voxel, a field-free sparse voxel structure that encodes both geometry and appearance. They leverage this representation to design a Sparse Compression VAE that achieves high spatial downsampling and a compact latent space. By training large-scale flow-matching models on these native structured latents, the authors enable the efficient generation of high-resolution 3D assets with superior geometric detail and realistic material properties.
Dataset

The authors develop a data preparation pipeline inspired by the TRELLIS framework to train an image-conditioned model. The dataset details are as follows:
- Dataset Composition and Sources: The training data is built from a curated collection of 3D assets. The authors specifically excluded the 3D-FUTURE dataset because it lacks Physically-Based Rendering (PBR) materials.
- Data Generation and Processing: To create the necessary image prompts, the authors use Blender to render diverse views of each 3D asset. This rendering process incorporates several augmentations to improve model robustness:
- Field of View (FoV): The camera FoV is randomly sampled between 10 and 70 degrees to help the model handle unknown camera intrinsics.
- Lighting Conditions: Light source positions and intensities are randomized to help the model disentangle intrinsic PBR attributes from environmental illumination.
Method
The authors propose a novel framework for native 3D asset generation, centered around a specialized representation called O-Voxel. This approach moves away from traditional multi-view baking pipelines, instead focusing on a unified representation that captures both geometry and material properties in a single, compact latent space.
As shown in the framework diagram below, the process involves a bidirectional conversion between standard 3D assets and the O-Voxel representation, followed by compression via a Sparse Compression VAE (SC-VAE), and finally, large-scale generative modeling.

The O-Voxel representation defines a 3D asset as a collection of feature tuples associated with sparse voxels on a regular grid of resolution N×N×N: f={(fishape,fimat,pi)}i=1L where fishape encodes local geometry, fimat encodes material properties, and pi denotes the coordinate of the i-th active voxel.
To handle complex geometries, the authors introduce a Flexible Dual Grid formulation for the shape component. This method constructs a dual grid from a primal voxel grid, where dual vertices and quadrilateral faces are used to represent surfaces. The positions of dual vertices are determined by solving a Quadratic Error Function (QEF) that incorporates intersection points, normals, boundary edge distances, and a regularization term to ensure stability. The shape feature fishape thus consists of the dual vertex position vi, edge intersection flags δi, and splitting weights γi for adaptive triangulation.
For material representation, the O-Voxel employs volumetric attributes that align with the surface geometry. The material feature fimat is parameterized using Physically-Based Rendering (PBR) conventions: fimat=(ci,mi,ri,αi) where ci is the base color, mi is the metallic ratio, ri is the roughness, and αi is the opacity.
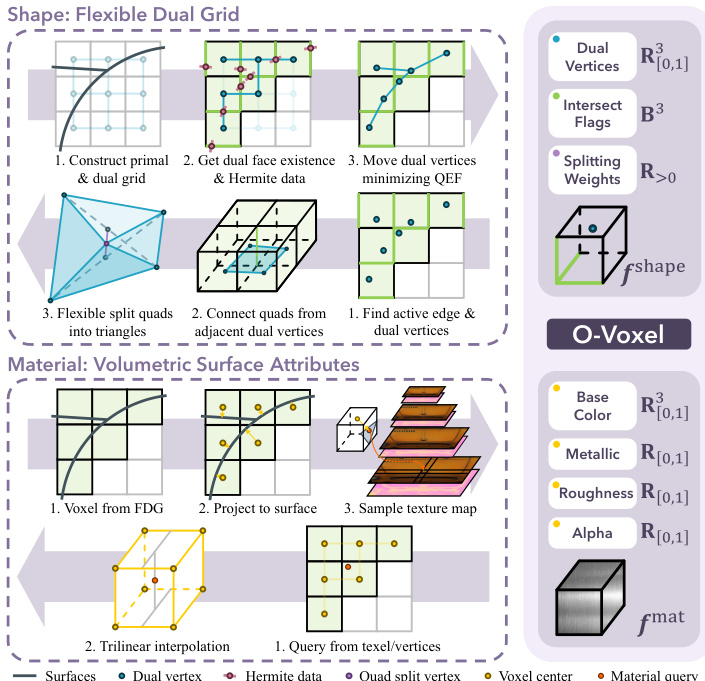
To enable efficient generation, the authors design a Sparse Compression VAE (SC-VAE). Unlike previous transformer-based designs, the SC-VAE utilizes a fully sparse-convolutional U-shaped architecture. It incorporates Sparse Residual Autoencoding layers that use non-parametric shortcuts to rearrange information between space and channel dimensions during downsampling and upsampling. Specifically, the downsampling process aggregates eight children voxels into the channel dimension, while the upsampling process uses a channel-to-space shortcut. To optimize efficiency, an early-pruning mechanism predicts a binary mask to skip inactive nodes during upsampling. The residual blocks are further optimized using a ConvNeXt-style design, replacing standard convolutions with a single convolution layer followed by a wide point-wise MLP.

The final stage of the framework is the generative modeling process, which is built upon the learned latent space. The authors employ a Diffusion Transformer (DiT) architecture trained with the flow matching paradigm. The generation is decomposed into three sequential stages: sparse structure generation to predict the occupancy layout, geometry generation to produce geometry latents, and material generation to synthesize material latents. The material generation stage is uniquely designed to be conditioned on both the input image and the previously generated geometry latents, ensuring that the synthesized PBR materials are spatially aligned with the underlying 3D structure.
Experiment
The evaluation encompasses 3D asset reconstruction, image-to-3D generation, and shape-conditioned texture synthesis using diverse datasets including Toys4K and curated Sketchfab assets. Reconstruction experiments validate the model's ability to recover complex geometries and faithful PBR materials, while generation tasks assess visual alignment and geometric consistency against state-of-the-art baselines. Qualitative results and user studies demonstrate that the framework excels at producing high-fidelity, topologically complex assets with physically plausible textures and sharp surface details.
The authors evaluate their image-to-3D generation framework against several state-of-the-art baselines using both automated alignment metrics and human preference studies. Results show that the proposed method achieves superior performance in semantic, geometric, and perceptual alignment compared to existing models. The proposed method achieves the highest scores across all quantitative alignment metrics, including CLIP, ULIP-2, and Uni3D. In user studies, the method is significantly preferred by participants for both overall quality and shape quality. The framework demonstrates stronger visual and geometric consistency with input prompts than competing generative systems.
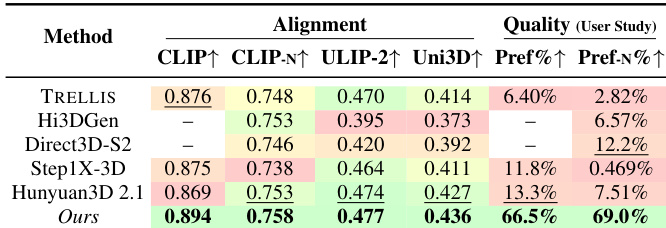
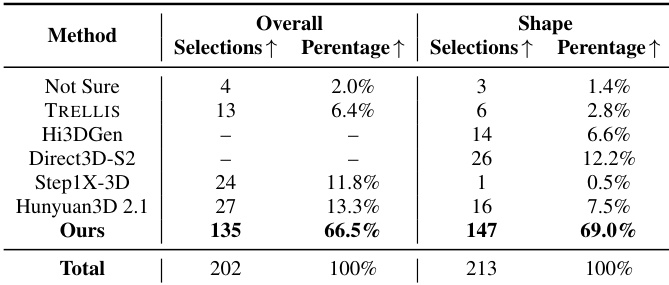
The authors conduct a user study to evaluate the perceptual quality of 3D assets generated from images, comparing their method against several state-of-the-art systems. Participants assessed both overall quality and specific shape quality through preference votes. The proposed method is preferred by a large majority of participants for both overall quality and shape quality. Results show the method achieves a significantly higher selection percentage compared to all other evaluated baselines. The framework demonstrates clear superiority in visual realism and geometric detail according to human preference.
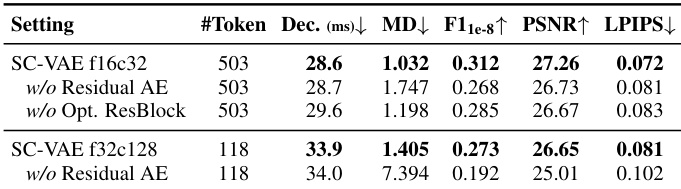
The authors conduct an ablation study to evaluate the impact of specific architectural components within the SC-VAE framework. Results show that the full SC-VAE configuration achieves superior reconstruction fidelity and efficiency compared to versions lacking sparse residual autoencoding or optimized residual blocks. The full SC-VAE model outperforms baseline configurations in geometric accuracy and surface quality metrics. Removing the sparse residual autoencoding layer leads to a significant degradation in reconstruction fidelity. The optimized residual block design contributes to better preservation of fine-scale details compared to standard residual blocks.
The authors evaluate 3D asset reconstruction performance using the Toys4K and Sketchfab Featured datasets across various geometric and surface quality metrics. Results show that the proposed method achieves superior fidelity in both mesh distance and surface smoothness compared to existing baselines. The proposed approach outperforms all baseline methods across all evaluated metrics for both datasets The method demonstrates higher geometric accuracy and finer surface detail preservation than sparse voxel and shape-based models The proposed model achieves better reconstruction quality while utilizing a significantly lower number of tokens
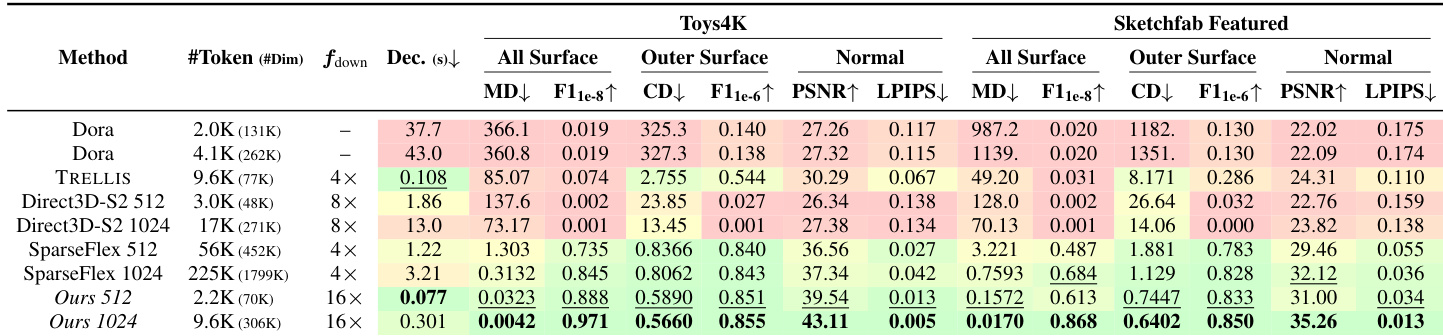
The authors evaluate their image-to-3D generation framework through comparative baseline studies, human preference assessments, and ablation experiments to validate semantic alignment and reconstruction fidelity. The results demonstrate that the proposed method achieves superior visual realism, geometric consistency, and shape quality compared to state-of-the-art systems. Furthermore, ablation studies confirm that the specific architectural components of the SC-VAE framework are essential for maintaining high reconstruction accuracy and preserving fine-scale details.