Command Palette
Search for a command to run...
WorldPlay: 실시간 상호작용 세계 모델링을 위한 장기적 기하학적 일관성 도달
WorldPlay: 실시간 상호작용 세계 모델링을 위한 장기적 기하학적 일관성 도달
Wenqiang Sun Haiyu Zhang Haoyuan Wang Junta Wu Zehan Wang Zhenwei Wang Yunhong Wang Jun Zhang Tengfei Wang Chunchao Guo
HY-World 1.5: 상호작용형 세계 모델링 시스템을 위한 프레임워크
초록
이 논문은 현재 기술들이 직면하는 속도와 메모리 간의 트레이드오프를 해결하고, 장기적인 기하학적 일관성을 유지하면서 실시간으로 상호작용 가능한 세계 모델링을 가능하게 하는 스트리밍 비디오 확산 모델인 WorldPlay을 제안한다. WorldPlay의 성능은 세 가지 핵심 기술 혁신에 기반한다. 1) 사용자의 키보드 및 마우스 입력에 대해 강력한 액션 제어를 가능하게 하기 위해 이중 액션 표현(Dual Action Representation)을 도입하였다. 2) 장기 일관성을 확보하기 위해, 과거 프레임들로부터 동적으로 컨텍스트를 재구성하고, 시간적 재구성(temporal reframing) 기법을 활용하여 기하학적으로 중요한 과거 프레임들을 오랜 기간 동안 접근 가능하게 유지함으로써 메모리 감쇠 문제를 효과적으로 완화한다. 3) 또한, 메모리 인지 모델을 위한 새로운 디스틸레이션 방법인 컨텍스트 포싱(Context Forcing)을 제안한다. 이는 교사 모델과 학습자 모델 간의 메모리 컨텍스트를 일치시킴으로써, 학습자 모델이 장거리 정보를 효과적으로 활용할 수 있는 능력을 유지하게 하여 실시간 속도를 확보하면서 오차 누적이 발생하지 않도록 한다. 종합적으로 WorldPlay는 720p 해상도의 장기 시퀀스 스트리밍 비디오를 초당 24프레임(24 FPS)으로 생성하며, 기존 기법들과 비교해 우수한 일관성과 다양한 장면에 걸친 강력한 일반화 능력을 보여준다. 프로젝트 페이지 및 온라인 데모는 아래 링크에서 확인할 수 있다: https://3d-models.hunyuan.tencent.com/world/ 및 https://3d.hunyuan.tencent.com/sceneTo3D.
One-sentence Summary
Researchers from Tencent Hunyuan, HKUST, and Beihang University propose WorldPlay, a streaming video diffusion model enabling real-time interactive world modeling with long-term geometric consistency. It overcomes memory attenuation in prior work through dual action control, dynamic context memory reconstruction, and memory-aware distillation, achieving 720p/24 FPS navigation while maintaining scene coherence during revisits across real-world and stylized environments for practical deployment.
Key Contributions
- WorldPlay resolves the speed-memory trade-off in real-time interactive world modeling by introducing a Dual Action Representation that enables precise keyboard and mouse control, eliminating action ambiguity for reliable navigation and memory retrieval during streaming video generation.
- Its Reconstituted Context Memory dynamically rebuilds context from past frames and applies temporal reframing to retain geometrically critical long-past frames, effectively alleviating memory attenuation and ensuring long-term geometric consistency across diverse scenes.
- The novel Context Forcing distillation method aligns memory context between teacher and student models to preserve long-range information, enabling real-time 720p video generation at 24 FPS without error drift while outperforming existing techniques in consistency benchmarks.
Introduction
The authors address the need for real-time interactive world models that maintain geometric consistency during extended user navigation, which is critical for applications like virtual environments, agent training, and immersive simulation where scene coherence across revisits directly impacts usability. Prior approaches face a fundamental trade-off: explicit 3D reconstruction methods achieve spatial consistency but suffer from reconstruction errors that degrade long-term coherence and lack real-time performance, while implicit field-of-view conditioning techniques scale better but fail to preserve geometric accuracy over extended interactions. Distillation strategies for real-time generation often compromise interactivity or consistency due to exposure bias. WorldPlay resolves this by introducing context forcing distillation, which preserves historical scene geometry during accelerated generation, and a memory framework that enables real-time navigation with long-term consistency across diverse scenes including real-world and stylized environments.
Dataset
The authors use the WorldPlay dataset, comprising approximately 320K high-quality video clips from real-world and synthetic sources, for training and evaluation. Key details are structured as follows:
-
Dataset composition and sources:
The dataset combines real-world footage (processed via 3D reconstruction) and synthetic environments (game recordings and UE engine renders), segmented into 30–40-second clips with text and pose annotations. -
Subset details:
- Real-World Dynamics (40K clips): Sourced from Sekai [36], filtered using YOLO [51] to remove clips with dense crowds, vehicles, watermarks, or erratic motion.
- Real-World 3D Scene (60K clips): Derived from DL3DV [40]; original videos undergo 3D Gaussian Splatting [25] for reconstruction, custom revisit trajectory rendering, and Difix3D+ [66] artifact repair.
- Synthetic 3D Scene (50K clips): Generated from UE engine scenes using complex, customized camera trajectories.
- Simulation Dynamics (170K clips): Collected via a custom game-recording platform where players generated 1st/3rd-person AAA game footage with designed trajectories.
Subset ratios in training: 12.5% (Real-World Dynamics), 18.8% (Real-World 3D Scene), 15.6% (Synthetic 3D Scene), 53.1% (Simulation Dynamics).
-
Data usage and processing:
- Training uses the full 320K clips with the above mixture ratios.
- Vision-language models [81] generate text annotations; VIPE [20] labels missing camera poses.
- Pose collapse is mitigated by filtering clips with erratic adjacent-frame rotations/translations.
- Discrete actions are derived from continuous poses via axis projection and thresholding.
- Revisit trajectories (emphasized in Fig. 10) enable long-term consistency learning.
-
Evaluation setup:
A 600-case test set (from DL3DV, games, and AI images) assesses short-term quality (vs. ground truth) and long-term consistency using cyclic trajectories. Metrics include LPIPS, PSNR, SSIM, and pose-distance scores.
Method
The authors leverage a chunk-wise autoregressive diffusion framework to enable real-time, interactive world modeling with long-term geometric consistency. The core architecture, as shown in the framework diagram, operates by predicting the next video chunk—comprising 16 frames—conditioned on user actions, prior observations, and an initial scene description (text or image). This process is repeated iteratively, with each chunk generation informed by a dynamically reconstituted memory context derived from past frames.
At the heart of the model is the Auto-Regressive Diffusion Transformer, which processes latent video tokens in causal fashion. The transformer integrates two key innovations: Dual Action Representation and Reconstituted Context Memory. The Dual Action Representation, detailed in the architecture diagram, encodes both discrete keyboard inputs and continuous camera poses. Discrete keys are embedded via positional encoding and fused into the timestep modulation pathway, while continuous camera poses are injected into the self-attention mechanism using PROPE (Projected Relative Positional Encoding). This dual encoding enables precise spatial control and stable training across scenes of varying scale, with the camera pose component modulating attention via a zero-initialized branch to preserve gradient stability.
To maintain long-term consistency, the model employs a Reconstituted Context Memory module that dynamically assembles a context set for each new chunk. This set comprises two components: a temporal memory, consisting of the L most recent chunks to ensure motion smoothness, and a spatial memory, which samples geometrically relevant past frames based on FOV overlap and camera distance. Crucially, to counteract the attenuation of long-range positional signals in Transformers, the authors introduce Temporal Reframing. As illustrated in the memory mechanism comparison, this technique reassigns relative positional indices to retrieved frames, effectively “pulling” distant but geometrically important memories closer in time. This ensures their continued influence on current predictions, mitigating drift during extended sequences.
For real-time inference, the authors deploy Context Forcing—a novel distillation strategy that aligns memory context between a bidirectional teacher model and an autoregressive student. The student performs self-rollouts conditioned on the reconstituted memory, while the teacher is augmented with the same context, excluding the target chunk. This alignment enables effective distribution matching via a score-based loss, preserving long-term consistency even under few-step denoising. The distillation pipeline, shown in the context forcing diagram, uses memory-augmented bidirectional diffusion to compute both real and fake scores, ensuring the student learns to replicate the teacher’s behavior under identical memory conditions.
Finally, the system is optimized for streaming deployment through mixed parallelism, progressive VAE decoding, and quantization. The inference pipeline leverages KV caching to avoid redundant computation across autoregressive steps, enabling 24 FPS generation at 720p resolution. The memory cache is continuously updated with new frames, and context reconstitution occurs per chunk, ensuring the model remains responsive to user input while preserving spatial coherence over extended horizons.
Experiment
- Main experiments validate WorldPlay against baselines on short-term and long-term interactive world modeling, achieving superior visual fidelity and geometric consistency on long-term scenarios, surpassing explicit 3D methods (Gen3C, VMem) constrained by depth inaccuracies
- Action representation ablation confirms dual-action (discrete keys + continuous poses) improves control accuracy on Rdist and Tdist metrics, overcoming limitations of single-representation approaches
- RoPE design comparison shows reframed positional encoding reduces error accumulation and enhances long-term consistency, outperforming standard RoPE in visual metrics (PSNR/SSIM)
- Context forcing evaluation demonstrates aligned memory distillation prevents output collapse and artifacts, enabling the student model to match teacher-level consistency while maintaining real-time interactivity
- Memory size ablation reveals larger temporal memory improves overall performance, whereas excessive spatial memory increases training complexity without proportional gains
- VBench and human evaluation across 600 cases confirm WorldPlay excels in consistency, motion smoothness, and scene generalizability, with 30 assessors consistently preferring its visual quality and control accuracy
- Long video generation maintains geometric consistency across extended sequences (e.g., frame 1 to 252) with constant per-chunk generation time, enabling real-time interaction
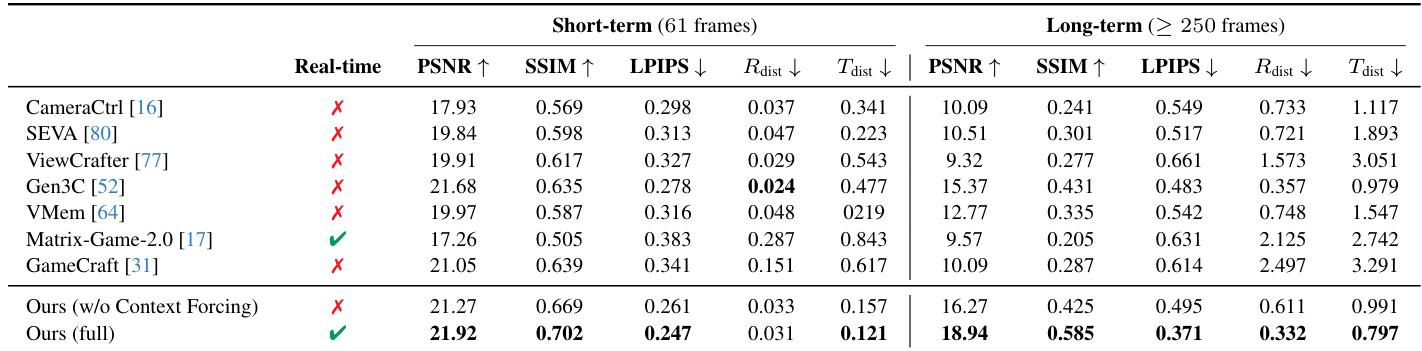
The authors use a dual-action representation and context forcing to achieve superior short-term visual fidelity and long-term geometric consistency, outperforming baselines in PSNR, SSIM, and LPIPS metrics while maintaining real-time interactivity. Results show that their full method reduces distance errors (R_dist and T_dist) significantly in long-term sequences compared to ablated versions and prior work, particularly excelling in stability and visual quality over extended durations.
The authors compare three models under context forcing, showing that the distilled student model achieves the best balance of visual quality and control accuracy while reducing inference steps to 4 NFE. Results indicate the teacher model excels in PSNR and SSIM but lacks real-time capability, whereas the final distilled model improves over the student in all metrics except NFE. Context forcing enables the distilled model to maintain long-term consistency with significantly fewer function evaluations.

The authors compare standard RoPE with their reframed RoPE design in memory mechanisms, showing that reframed RoPE improves visual quality and geometric consistency. Results indicate higher PSNR and SSIM scores and lower LPIPS, R_dist, and T_dist values, confirming reduced error accumulation and better long-term performance.

The authors evaluate three action representations—discrete, continuous, and dual (Full)—and find that the dual-action approach achieves the best overall control performance, with the highest PSNR and SSIM, lowest LPIPS, and smallest rotation and translation distances. While continuous actions improve over discrete ones, the dual representation further refines control precision and visual quality. Results confirm that combining discrete and continuous signals enables more accurate and stable agent control in dynamic scenes.

The authors evaluate memory size ablations, showing that a larger temporal memory (Tem. = 3) yields higher PSNR and SSIM while reducing LPIPS, R_dist, and T_dist compared to a larger spatial memory (Spa. = 3). Results indicate temporal memory better preserves pretrained model continuity and overall performance, despite spatial memory offering slight PSNR gains.
