Command Palette
Search for a command to run...
OpenDataArena: 사후 훈련 데이터셋 가치 평가를 위한 공정하고 개방적인 아레나
OpenDataArena: 사후 훈련 데이터셋 가치 평가를 위한 공정하고 개방적인 아레나
초록
대규모 언어 모델(Large Language Models, LLMs)의 급속한 발전은 후기 훈련 데이터셋의 품질과 다양성에 크게 의존하고 있다. 그러나 여전히 중요한 이분법이 존재한다. 모델들은 철저하게 벤치마킹되지만, 그 모델을 구동하는 데이터는 여전히 투명하지 않은 '블랙 박스' 상태를 유지하고 있다. 이는 데이터 구성의 불투명성, 출처의 불확실성, 그리고 체계적인 평가 부족을 특징으로 하며, 재현 가능성의 저해와 데이터 특성과 모델 행동 간 인과관계의 왜곡을 초래한다. 이러한 격차를 해소하기 위해 우리는 후기 훈련 데이터의 내재적 가치를 벤치마킹하기 위해 설계된 통합적이고 개방적인 플랫폼인 OpenDataArena(ODA)를 제안한다. ODA는 네 가지 핵심 요소로 구성된 포괄적인 생태계를 구축한다. (i) 다양한 모델(예: Llama, Qwen)과 영역 간 공정하고 개방적인 비교를 보장하는 통합된 훈련-평가 파이프라인; (ii) 수십 가지의 서로 다른 축을 기반으로 데이터 품질을 다차원적으로 평가하는 점수 체계; (iii) 데이터셋의 유전적 연관성(데이터 라이니지)을 시각화하고 구성 요소의 출처를 분석할 수 있는 상호작용형 데이터 라이니지 탐색기; (iv) 훈련, 평가, 점수화를 위한 완전한 오픈소스 툴킷으로, 데이터 연구를 촉진한다. ODA를 활용한 광범위한 실험은 다수의 도메인에서 120개 이상의 훈련 데이터셋을 대상으로 22개의 벤치마크에서 수행되었으며, 600회 이상의 훈련 실행과 4,000만 개 이상의 처리된 데이터 포인트를 기반으로 검증되었다. 분석 결과는 데이터 복잡성과 작업 성능 사이의 본질적인 트레이드오프를 밝혀냈으며, 라이니지 추적을 통해 인기 벤치마크 내부의 중복성을 확인했고, 다양한 데이터셋 간 유전적 관계를 맵핑하였다. 본 연구는 모든 결과, 도구, 설정을 공개함으로써 고품질 데이터 평가 접근의 민주화를 추진한다. ODA는 단순히 리더보드를 확장하는 것을 넘어서, 시행착오 중심의 데이터 커리레이션에서 데이터 중심 인공지능(Data-Centric AI)의 체계적 과학으로의 전환을 목표로 한다. 이를 통해 데이터 혼합 법칙 및 기초 모델의 전략적 구성에 관한 엄밀한 연구의 길을 열어줄 것이다.
One-sentence Summary
Researchers from Shanghai Artificial Intelligence Laboratory and OpenDataLab et al. introduce OpenDataArena (ODA), a comprehensive platform that benchmarks post-training data value via a unified evaluation pipeline, multi-dimensional scoring framework, interactive lineage explorer, and open-source toolkit, enabling systematic data evaluation to shift from trial-and-error curation to a principled science of Data-Centric AI.
Key Contributions
- The post-training data for large language models remains a "black box" with opaque composition and uncertain provenance, hindering reproducibility and obscuring how data characteristics influence model behavior. This critical gap prevents systematic evaluation of data quality despite rigorous model benchmarking.
- OpenDataArena introduces a holistic platform featuring a unified training-evaluation pipeline, multi-dimensional scoring framework across tens of quality axes, and an interactive data lineage explorer to transparently benchmark data value and trace dataset genealogy. Its open-source toolkit enables fair comparisons across diverse models and domains while standardizing data-centric evaluation.
- Experiments across 120 datasets on 22 benchmarks, validated by 600+ training runs and 40 million data points, reveal inherent trade-offs between data complexity and task performance while identifying redundancy in popular benchmarks through lineage analysis. These results empirically demonstrate that carefully curated, information-dense datasets can outperform larger unstructured collections and highlight response quality as a stronger predictor of downstream performance than prompt complexity.
Introduction
The authors address the critical gap in Large Language Model development where post-training data quality directly impacts model performance yet remains unmeasured and opaque. Current practices rigorously benchmark models but treat training datasets as black boxes with unclear composition and provenance, hindering reproducibility and obscuring how specific data characteristics influence model behavior. To solve this, they introduce OpenDataArena a holistic open platform featuring a unified training-evaluation pipeline multi-dimensional scoring across dozens of quality axes interactive data lineage tracing and fully open-source tools. Validated across 120 datasets and 22 benchmarks the system enables fair data comparisons revealing non-trivial insights like data complexity trade-offs and benchmark redundancies to transform data curation from trial-and-error into a principled science for Data-Centric AI.
Dataset
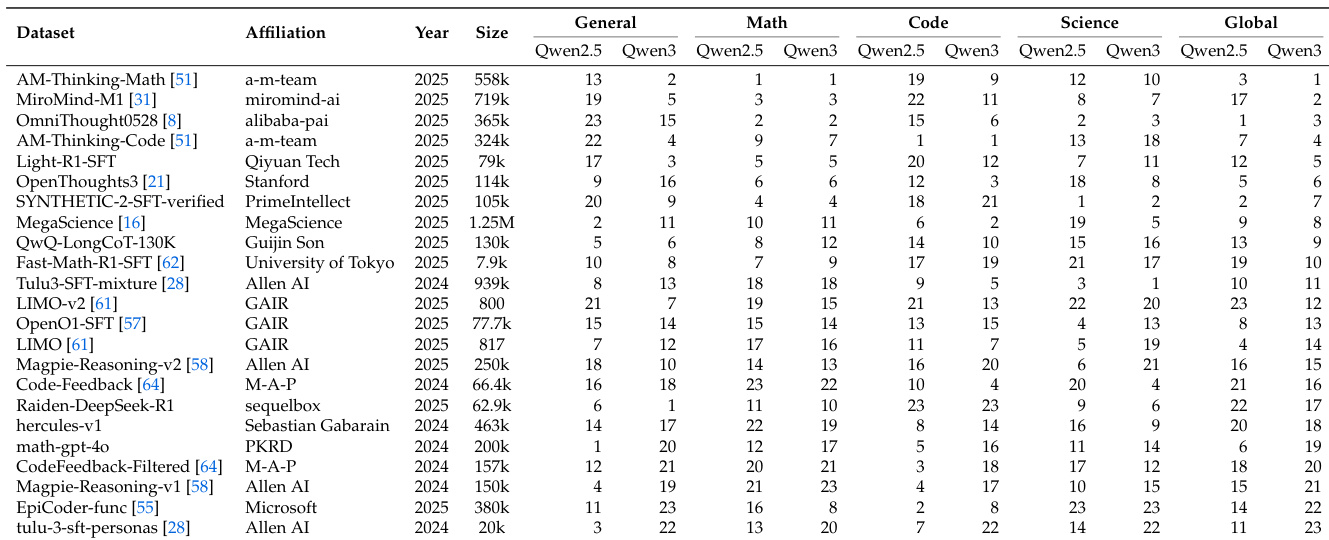
The authors compile OpenDataArena (ODA), a repository of 120 publicly available supervised fine-tuning (SFT) datasets totaling over 40 million samples. These originate from community sources like Hugging Face, prioritized by demonstrated impact (minimum downloads/likes), recency (post-2023), domain relevance, and size constraints for computational feasibility. All undergo safety review and format standardization.
Key subsets include:
- Training data: Spans general dialog (20.8%), math (34.3%), code (30.6%), and science (14.4%). Sizes range from thousands to 100k+ samples per dataset (e.g., 0penThoughts3, LIM0, Tulu3-SFT).
- Benchmarks: 22+ evaluation suites covering:
- General: DROP, MMLU-PRO
- Math: GSM8K, OlympiadBenchMath
- Code: HumanEval+, LiveCodeBench
- Reasoning: ARC_c, GPQA diamond
The paper uses these datasets exclusively for evaluation—not training—to holistically assess model capabilities across domains. No mixture ratios or training splits apply. Processing involves:
- Standardizing instruction-response formats
- Conducting "Data Lineage" analysis to map dataset derivations and redundancies
- Applying multi-dimensional quality scoring (e.g., safety, coherence) to instructions (Q) and full pairs (QA)
- Visualizing relationships via interactive lineage graphs and comparative scoring interfaces.
Method
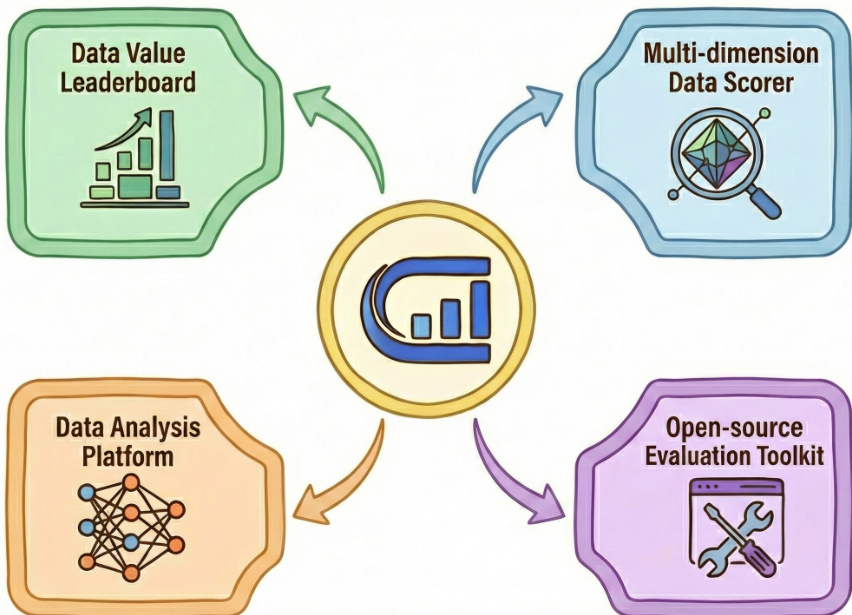
The authors leverage OpenDataArena (ODA) as a unified, data-centric evaluation infrastructure to systematically benchmark the intrinsic value of post-training datasets for large language models. The platform’s architecture is designed around four core components that collectively enable fair, reproducible, and multidimensional assessment. Refer to the framework diagram, which illustrates how these components—Data Value Leaderboard, Multi-dimension Data Scorer, Data Analysis Platform, and Open-source Evaluation Toolkit—interact around a central evaluation engine to form a cohesive system for dataset evaluation.
At the operational level, ODA implements a four-stage evaluation pipeline that begins with the Data Input Layer. Here, datasets are collected from diverse sources, normalized into a consistent format, and classified by domain to ensure uniformity before processing. The pipeline then advances to the Data Evaluation Layer, which serves as the computational core. In this stage, each dataset is used to fine-tune a fixed base model—such as Qwen or Llama—under standardized hyperparameters and training protocols. The resulting model is evaluated across a diverse suite of downstream benchmarks, including general chat, scientific reasoning, and code generation. This standardized train-evaluate loop isolates dataset quality as the sole variable, enabling direct, apples-to-apples comparisons.
As shown in the figure below, the Data Evaluation Layer also integrates the multi-dimensional scoring system, which assesses datasets along tens of axes—separately evaluating instructions (Q) and instruction-response pairs (Q&A). This scoring framework employs three methodological categories: model-based evaluation (e.g., predicting instruction difficulty), LLM-as-Judge (e.g., GPT-4 for qualitative coherence assessment), and heuristic rules (e.g., token length or response clarity). These metrics collectively generate a diagnostic “fingerprint” for each dataset, capturing dimensions such as complexity, correctness, and linguistic quality.
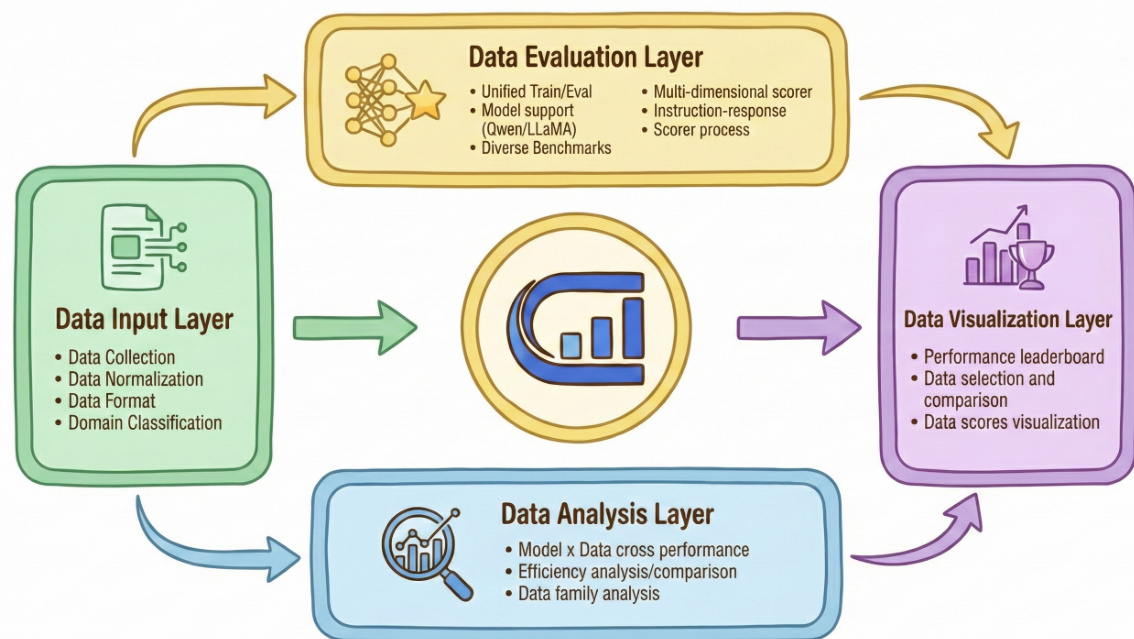
The Data Analysis Layer synthesizes the outputs from the evaluation stage to perform cross-model and cross-domain performance comparisons, efficiency analyses, and data family relationship mapping. This layer enables researchers to identify high-yield datasets and understand domain-specific or model-specific preferences. Finally, the Data Visualization Layer renders these insights into interactive leaderboards and comparative charts, allowing users to intuitively explore dataset rankings and quality profiles. The entire pipeline is supported by an open-source toolkit that provides all configurations, scripts, and raw results, ensuring full reproducibility and community extensibility.
To further enhance transparency, ODA incorporates an automated data lineage framework that models dataset dependencies as a directed graph G=(V,E), where nodes represent datasets and edges encode derivation relationships. This framework employs a multi-agent collaborative pipeline to recursively trace upstream sources from documentation across Hugging Face, GitHub, and academic papers. Through semantic inference, confidence scoring, and human-in-the-loop verification, the system constructs a factually grounded lineage graph that reveals redundancy, provenance, and compositional evolution across the dataset ecosystem.
Experiment
- Standardized pipeline validation across 600+ training runs confirmed data as the sole performance variable, using consistent Llama3.1-8B/Qwen models and OpenCompass evaluation.
- Lineage analysis of 70 seed datasets revealed a 941-edge global graph; AM-Thinking-v1-Distilled achieved +58.5 Math gain on Llama3.1-8B, while benchmark contamination propagated via datasets like SynthLabsAI/Big-Math-RL-Verified.
- Temporal analysis showed Math dataset quality surged from 35 to 56 (Qwen2.5, 2023-2025Q3), whereas Code domain performance remained volatile and General domain saturated.
- Math dataset rankings exhibited high consistency across Qwen models (Spearman 0.902), while General domain rankings reversed (-0.323 correlation).
- Response length strongly correlated with Math performance (0.81), but Code domain showed inverse trends (e.g., -0.29 for response length).
The authors use Spearman rank correlation to measure consistency in dataset rankings between Qwen2.5 and Qwen3 models across domains. Results show Math datasets exhibit strong consistency (0.902), while General datasets show negative correlation (-0.323), indicating saturation effects in general instruction following as models advance. Science and Code domains show weak positive correlations, suggesting their specialized knowledge remains valuable but less stable across model generations.
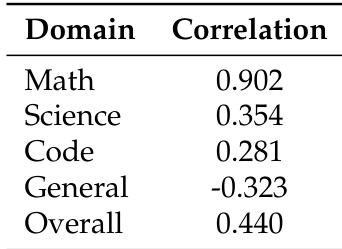
The authors use standardized fine-tuning and evaluation protocols across Qwen2.5 and Qwen3 models to compare dataset performance rankings. Results show high consistency in Math domain rankings between models (Spearman correlation 0.902), while General domain rankings exhibit negative correlation (-0.323), suggesting saturation in instruction-following tasks for stronger models. Code and Science domains show weak positive correlations, indicating evolving dataset value as base model capabilities advance.