Command Palette
Search for a command to run...
롱비에 2: 다중모달 제어 가능한 초장거리 비디오 월드 모델
롱비에 2: 다중모달 제어 가능한 초장거리 비디오 월드 모델
Jianxiong Gao Zhaoxi Chen Xian Liu Junhao Zhuang Chengming Xu Jianfeng Feng Yu Qiao Yanwei Fu Chenyang Si Ziwei Liu
초록
사전에 학습된 동영상 생성 시스템 위에 동영상 월드 모델을 구축하는 것은 일반적인 시공간 지능에 도달하기 위한 중요한 그러나 도전적인 단계이다. 월드 모델은 세 가지 핵심 특성을 가져야 한다: 조절 가능성(controllability), 장기적인 시각적 품질, 시간적 일관성(temporal consistency). 이를 위해 우리는 점진적인 접근 방식을 취한다. 먼저 조절 가능성을 향상시키고, 이후 장기적이고 고품질의 생성으로 확장한다. 우리는 세 단계에 걸쳐 훈련되는 엔드투엔드 자기회귀 프레임워크인 LongVie 2를 제안한다. (1) 다중모달 가이던스: 밀도 높은 및 희소한 제어 신호를 통합하여 암묵적인 월드 수준의 감독을 제공하고 조절 가능성을 향상시킨다. (2) 입력 프레임에 대한 품질 저하 인지 훈련(degradation-aware training): 훈련과 장기 추론 사이의 격차를 해소하여 높은 시각적 품질을 유지한다. (3) 역사적 컨텍스트 가이던스: 인접한 클립 간의 컨텍스트 정보를 일치시켜 시간적 일관성을 보장한다. 또한, 다양한 실제 세계 및 합성 환경을 포함하는 100개의 고해상도 1분짜리 동영상으로 구성된 종합적인 벤치마크인 LongVGenBench를 제안한다. 광범위한 실험을 통해 LongVie 2가 장거리 조절 가능성, 시간적 일관성, 시각적 정확성 측면에서 최신 기술(SOTA) 수준의 성능을 달성하며, 최대 5분에 이르는 지속적인 동영상 생성을 지원함으로써 통합된 동영상 월드 모델링을 향한 중대한 발걸음을 내디뎠음을 입증한다.
One-sentence Summary
Fudan University, Nanyang Technological University, and Shanghai AI Laboratory researchers propose LongVie 2, an autoregressive video world model generating controllable 3–5 minute videos. It introduces multi-modal guidance for dense/sparse control, a degradation-aware training strategy to bridge training-inference gaps, and history-context modeling for temporal consistency, significantly advancing long-range video generation fidelity and controllability over prior approaches.
Key Contributions
- LongVie 2 addresses the critical limitations in current video world models, which suffer from restricted semantic-level controllability and temporal degradation when generating videos beyond one minute. It introduces a progressive framework to unify fine-grained control with long-horizon stability for scalable world modeling.
- The method employs a three-stage training approach: integrating dense and sparse control signals for enhanced controllability, applying degradation-aware training to maintain visual quality during long inference, and using history-context guidance to ensure temporal consistency across extended sequences. This end-to-end autoregressive framework systematically bridges short-clip generation to minute-long coherent outputs.
- Evaluated on LongVGenBench—a rigorous benchmark of 100 diverse one-minute high-resolution videos—LongVie 2 achieves state-of-the-art results in controllability, temporal coherence, and visual fidelity while supporting continuous generation up to five minutes, demonstrating significant advancement toward unified video world models.
Introduction
Recent video diffusion models like Sora and Kling have enabled photorealistic text-to-video generation, but research now prioritizes video world models that simulate controllable physical environments for applications like virtual training and interactive media. However, existing world models suffer from limited semantic-level controllability—they cannot manipulate entire scenes coherently—and fail to maintain visual quality or temporal consistency beyond one-minute durations due to drift and degradation. The authors address this by extending pretrained diffusion backbones into LongVie 2, a framework trained through three progressive stages: multi-modal guidance for structural control, degradation-aware training to bridge short-clip and long-horizon inference gaps, and history context guidance for long-range coherence. This approach achieves minute-long controllable video generation while introducing LongVGenBench, a benchmark of 100 one-minute videos for rigorous evaluation of long-horizon fidelity.
Dataset
The authors use a multi-stage training approach with distinct datasets and processing pipelines:
-
Composition and sources:
Stages 1–2 train on ~60,000 videos from three sources: ACID/ACID-Large (drone footage of coastlines/landscapes), Vchitect_T2V_DataVerse (14M+ internet videos with text annotations), and MovieNet (1,100 full-length movies). Stage 3 uses long-form videos from OmniWorld and SpatialVID for temporal modeling. The evaluation benchmark LongVGenBench contains diverse 1+ minute, 1080p+ videos. -
Subset details:
- Stages 1–2 data: Unified into 81-frame clips at 16 fps. ACID ensures RealEstate10K-compatible metadata; MovieNet provides complex scenes.
- Stage 3 data: Processes long videos into 81-frame target segments starting at frame 20, using all preceding frames as history context. The training split comprises 40,000 randomly selected segments.
- LongVGenBench: Split into 81-frame clips with one-frame overlap for evaluation, each paired with captions and control signals.
-
Data usage:
Stages 1–2 train on the full 60,000-video corpus. Stage 3 exclusively uses the 40,000-segment split with history context. For LongVGenBench evaluation, short-clip captions and control signals guide inference. -
Processing details:
All training videos undergo strict pre-processing: scene transitions are removed via PySceneDetect, yielding transition-free clips. Each clip is sampled at 16 fps, truncated to 81 frames, and augmented with depth maps (Video Depth Anything), point trajectories (SpatialTracker), and captions (Qwen-2.5-VL-7B). This creates a final curated set of ~100,000 video-control pairs for training.
Method
The authors leverage a three-stage training framework to build LongVie 2, an autoregressive video world model capable of generating controllable, temporally consistent videos up to 3–5 minutes in duration. The architecture integrates multi-modal control signals, degradation-aware training, and history-context modeling to bridge the gap between short-clip training and long-horizon inference.
The overall framework, as shown in the figure below, begins with an input image and corresponding dense (depth) and sparse (point trajectory) control signals that provide world-level guidance. These modalities are processed through a modified DiT backbone that injects control features additively into the generation stream via zero-initialized linear layers, preserving the stability of the pre-trained base model while enabling fine-grained conditioning.
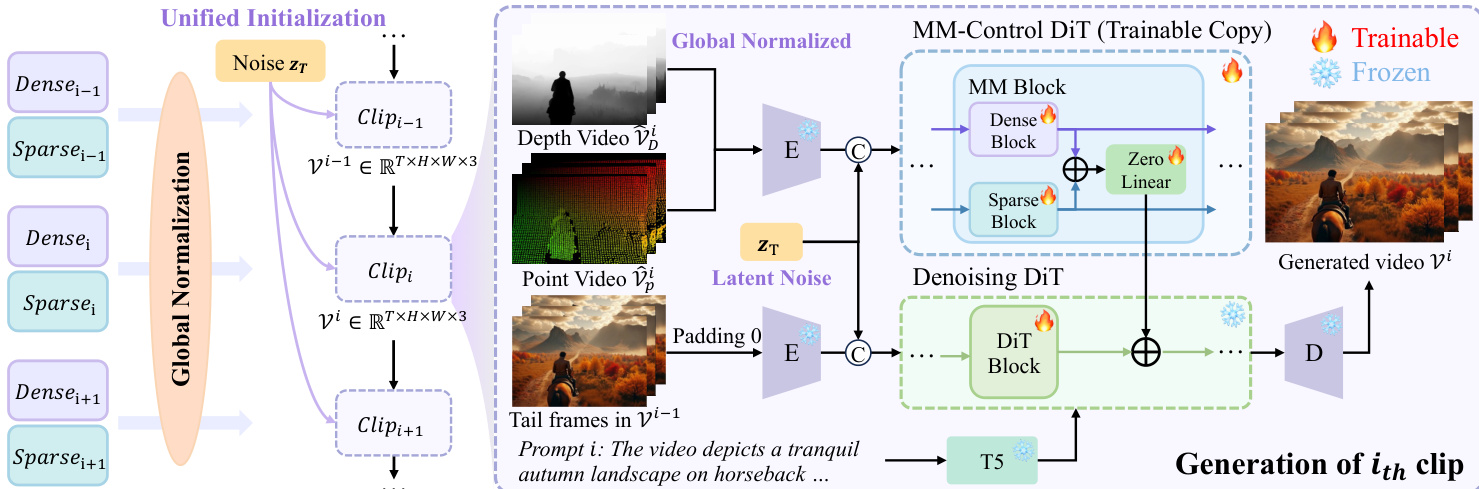
In Stage I, the model is initialized with clean pretraining using standard ControlNet-style conditioning. The authors construct a Multi-Modal Control DiT by duplicating the first 12 layers of the pre-trained Wan DiT and splitting each into two trainable branches—one for dense control (FD) and one for sparse control (FP). These branches process their respective encoded control signals cD and cP, and their outputs are fused into the frozen base DiT stream via zero-initialized linear layers ϕl, ensuring no initial interference with the pretrained weights. The computation at layer l is defined as:
z^{l} = \mathcal{F}^{l}(z^{l-1}) + \phi^{l}( \mathcal{F}_{\mathrm{D}}^{l}(c_{\mathrm{D}}^{l-1}) + \mathcal{F}_{\mathrm{P}}^{l}(c_{\mathrm{P}}^{l-1}) ) $$, where $\mathcal{F}^{l}$ denotes the frozen base block. To prevent dense signals from dominating, the authors introduce feature-level and data-level degradation during training. Feature-level degradation scales the dense latent representation by a random factor $\lambda \in [0.05, 1]$ with probability $\alpha$, reformulating the above equation as:z^{l} = \mathcal{F}^{l}(z^{l-1}) + \phi^{l}( \lambda \cdot \mathcal{F}{\mathrm{D}}^{l}(c{\mathrm{D}}^{l-1}) + \mathcal{F}{\mathrm{P}}^{l}(c{\mathrm{P}}^{l-1}) )
Data-level degradation applies Random Scale Fusion and Adaptive Blur Augmentation to the dense input tensor, enhancing robustness to spatial variation and reducing overfitting to local depth details. In Stage II, the authors address the domain gap between clean training inputs and degraded inference inputs by introducing a first-frame degradation strategy. As shown in the figure below, two degradation mechanisms are applied: encoding degradation, which simulates VAE-induced corruption via $K$ repeated encode-decode cycles, and generation degradation, which adds Gaussian noise to the latent representation at a random timestep $t < 15$ and then denoises it. The degradation operator $\mathcal{T}(I)$ is defined as:\mathcal{T}(I) = \left{ \begin{array}{ll} (\mathcal{D} \circ \mathcal{E})^K (I) & \text{w.p.}~0.2 \ \mathcal{D} \big( \Phi_0 ( \sqrt{\alpha_t} \mathcal{E}(I) + \sqrt{1-\alpha_t} \epsilon ) \big) & \text{w.p.}~0.8 \end{array} \right.
where $\epsilon \sim \mathcal{N}(0, \mathbf{I})$. This degradation is applied with probability $\alpha$ during training, with milder degradations occurring more frequently to simulate the gradual quality decay observed in long-horizon generation. 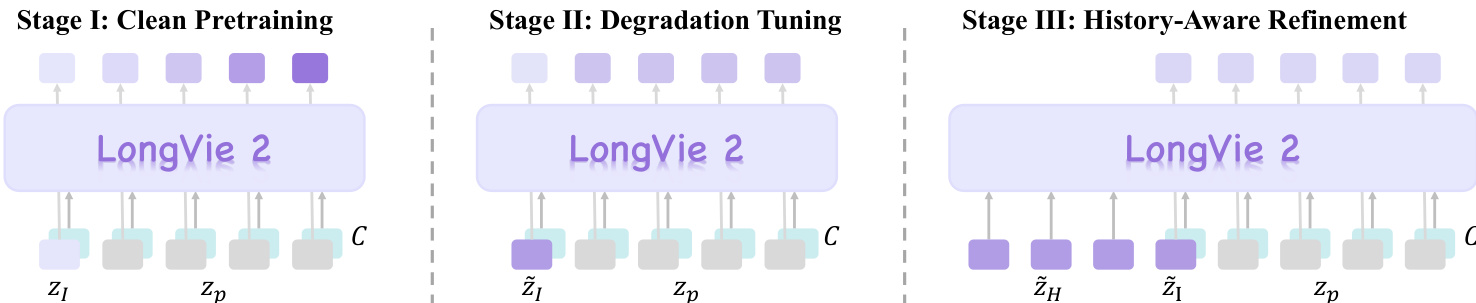 In Stage III, the model is refined with history-context guidance to enforce temporal consistency across clips. The authors encode the last $N_H$ frames of the preceding clip into latent space using the VAE encoder $\mathcal{E}(\cdot)$, apply the same degradation operator $\mathcal{T}(\cdot)$ to these frames, and then encode the degraded versions to obtain $\tilde{z}_H$. The model is trained to generate the next clip conditioned on the initial frame latent $z_I$, the history latent $\tilde{z}_H$, and the control signals $c_D$ and $c_P$, as formulated by:z_t = \mathcal{F}(z_{t+1} \mid z_I, z_H, c_D, c_P)
To stabilize the boundary between clips, the authors assign exponentially increasing weights to the first three generated frames and introduce three regularization losses: history context consistency $\mathcal{L}_{\mathrm{cons}} = \| z_{H}^{-1} - \hat{z}^{0} \|^{2}$, degradation consistency $\mathcal{L}_{\mathrm{deg}} = \| \mathcal{F}_{\mathrm{lp}}(\tilde{z}_{I}^{0}) - \mathcal{F}_{\mathrm{lp}}(\hat{z}^{0}) \|^{2}$, and ground-truth high-frequency alignment $\mathcal{L}_{\mathrm{gt}} = \| \mathcal{F}_{\mathrm{hp}}(z_{\mathrm{gt}}^{0}) - \mathcal{F}_{\mathrm{hp}}(\hat{z}^{0}) \|^{2}$. The final temporal regularization objective is:\mathcal{L}{\mathrm{temp}} = \lambda{\mathrm{deg}} \mathcal{L}{\mathrm{deg}} + \lambda{\mathrm{gt}} \mathcal{L}{\mathrm{gt}} + \lambda{\mathrm{cons}} \mathcal{L}_{\mathrm{cons}}
with $\lambda_{\mathrm{deg}}=0.2$, $\lambda_{\mathrm{gt}}=0.15$, and $\lambda_{\mathrm{cons}}=0.5$. Additionally, the self-attention layers of the base model are updated to capture causal dependencies, and $N_H$ is sampled uniformly from [0, 16] to support flexible inference. The training pipeline, as illustrated in the figure below, progresses from clean pretraining to degradation tuning and finally to history-aware refinement, each stage building upon the previous to enhance controllability, visual fidelity, and temporal coherence. 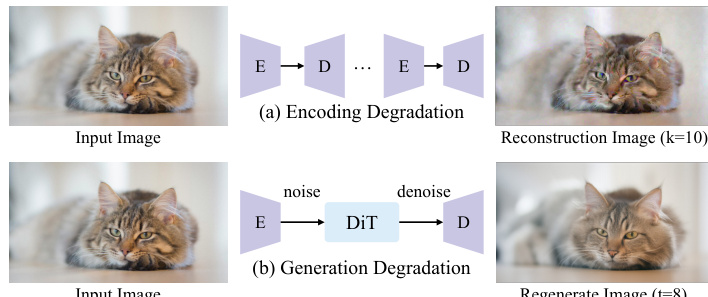 During inference, the authors employ two training-free strategies to further improve inter-clip consistency: unified noise initialization, which maintains a single shared noise latent across all clips, and global normalization of depth maps, which computes global 5th and 95th percentiles across the entire video to ensure consistent depth scaling. Point tracks are recomputed per clip using globally normalized depth to preserve motion guidance stability. Captions are refined using Qwen-2.5-VL-7B to align with the visual content of the generated frames, ensuring semantic consistency throughout the sequence. # Experiment - LongVie 2 validated on LongVGenBench (100 high-resolution videos) achieved state-of-the-art performance in controllability (superior SSIM/LPIPS scores), temporal coherence, and visual fidelity across all VBench metrics, surpassing pretrained models (Wan2.1), controllable models (VideoComposer, Go-with-the-Flow), and world models (Hunyuan-GameCraft). - Human evaluation with 60 participants confirmed LongVie 2 consistently outperformed baselines across all dimensions (Visual Quality, Prompt Consistency, Condition Consistency, Color Consistency, Temporal Consistency). - Extended generation tests demonstrated coherent 5-minute video synthesis while maintaining structural stability, motion consistency, and style adaptation in diverse real-world and synthetic scenarios. - Ablation studies proved the necessity of all three training stages: Control Learning enhanced controllability, Degradation-aware training improved visual quality, and History-context guidance ensured long-term temporal consistency. The authors evaluate ablations of LongVie 2 by removing key components such as global normalization, unified initial noise, and degradation strategies, showing that each contributes to visual quality and temporal consistency. Results indicate that omitting any component leads to measurable drops in aesthetic quality, imaging quality, subject consistency, and background consistency. The full model achieves the highest scores across all metrics, confirming the necessity of the integrated design. 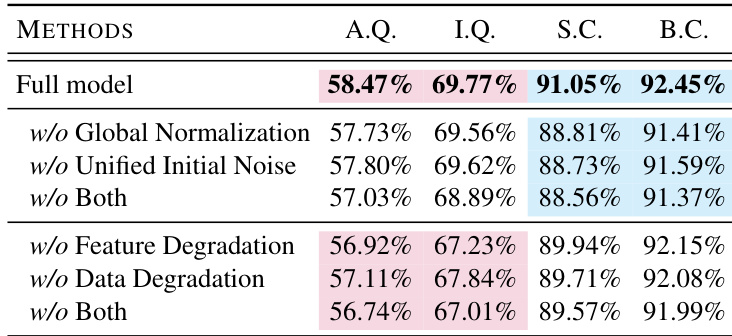 The authors evaluate LongVie 2 against several baselines in human evaluations across five perceptual dimensions, including visual quality and temporal consistency. Results show LongVie 2 achieves the highest scores in all categories, outperforming Matrix-Game-2.0, Go-With-The-Flow, DiffusionAsShader, and HunyuanGameCraft. This demonstrates its superior perceptual quality and controllability in long video generation. 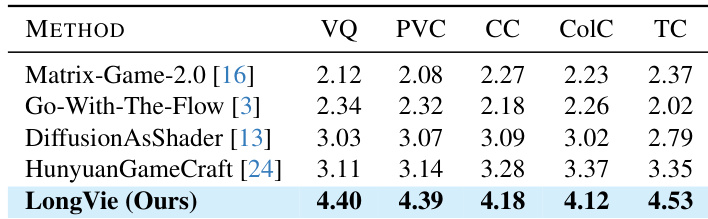 The authors evaluate LongVie 2 against multiple baselines on LongVGenBench, measuring visual quality, controllability, and temporal consistency. Results show LongVie 2 achieves the highest scores in aesthetic quality, imaging quality, SSIM, and subject consistency, while also leading in background consistency and dynamic degree. These metrics confirm LongVie 2’s superior performance in generating long, controllable, and temporally coherent videos. 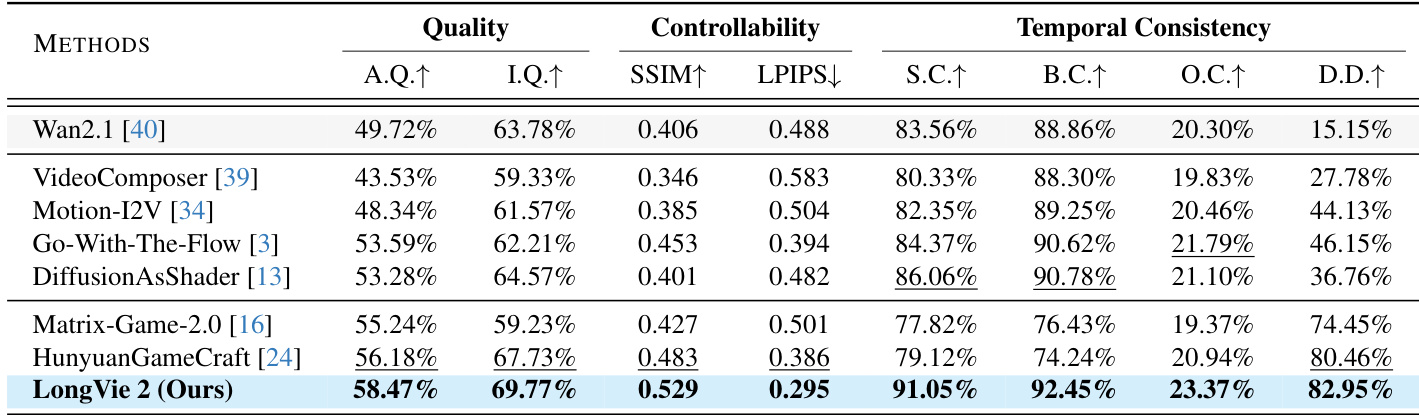 The authors use a staged training strategy to progressively enhance LongVie 2, with each stage improving visual quality, controllability, and temporal consistency. Results show that adding History Context yields the highest gains across all metrics, particularly in aesthetic quality, imaging quality, and temporal coherence. The final model achieves state-of-the-art performance by integrating multi-modal guidance, degradation-aware training, and history-context alignment.  The authors evaluate the impact of degradation strategies on LongVie 2’s performance, showing that adding both encoding and generation degradation improves all metrics: visual quality, controllability, and temporal consistency. Results indicate that combining both degradation types yields the highest scores across aesthetic and imaging quality, SSIM, LPIPS, and all temporal consistency measures. This confirms that degradation-aware training enhances the model’s ability to maintain fidelity and coherence during long video generation. 