Command Palette
Search for a command to run...
KlingAvatar 2.0 기술 보고서
KlingAvatar 2.0 기술 보고서
초록
최근 몇 년간 아바타 영상 생성 모델은 놀라운 발전을 이뤄냈다. 그러나 기존 연구는 긴 지속 시간의 고해상도 영상을 생성하는 데 있어 효율성이 제한적이며, 영상 길이가 길어질수록 시간적 편차(temporal drifting), 품질 저하, 그리고 프롬프트에 대한 약한 반응성이라는 문제를 겪고 있다. 이러한 과제를 해결하기 위해 우리는 공간-시간 복합 프레임워크인 KlingAvatar 2.0을 제안한다. 이 프레임워크는 공간 해상도와 시간 차원 양쪽에서의 확대(upscaling)를 수행한다. 먼저, 전반적인 의미 정보와 움직임을 포착하는 저해상도 블루프린트 영상 키프레임을 생성한 후, 첫 프레임과 마지막 프레임을 기반으로 한 전략을 사용해 고해상도로, 시간적으로 일관성 있는 하위 클립(sub-clips)으로 정제한다. 이 과정에서 긴 영상에서도 부드러운 시간적 전이를 유지한다. 또한, 긴 영상에서 다중 모달 지시(instruction) 간의 융합과 정렬을 강화하기 위해, 세 가지 모달리티 전용 대규모 언어 모델(LLM) 전문가로 구성된 '공동 추론 감독자(Co-Reasoning Director)'를 도입한다. 이 전문가들은 각 모달리티의 우선순위를 분석하고 사용자의 본질적 의도를 추론하여, 다단계 대화를 통해 입력을 구체적인 스토리라인으로 변환한다. 또한, 부정적 프롬프트를 더욱 정교하게 다듬어 지시사항과의 일치도를 향상시키는 '부정적 감독자(Negative Director)'를 추가로 도입한다. 이러한 구성 요소들을 기반으로, 우리는 프레임워크를 개선하여 ID 기반의 다중 캐릭터 제어 기능을 지원하게 했다. 광범위한 실험을 통해 제안한 모델이 효율적이고 다중 모달리티에 맞춰진 긴 지속 시간의 고해상도 영상 생성 문제를 효과적으로 해결함을 입증하였으며, 시각적 명료도 향상, 정확한 입술 동기화를 갖춘 현실적인 입술-치아 렌더링, 강력한 정체성 유지, 그리고 일관된 다중 모달 지시사항 준수 능력을 제공함을 확인하였다.
One-sentence Summary
Kuaishou Technology's Kling Team proposes KlingAvatar 2.0, a spatio-temporal cascade framework generating long-duration high-resolution avatar videos by refining low-resolution blueprint keyframes via first-last frame conditioning to eliminate temporal drifting. Its Co-Reasoning Director employs multimodal LLM experts for precise cross-modal instruction alignment, enabling identity-preserving multi-character synthesis with accurate lip synchronization for applications in education, entertainment, and personalized services.
Key Contributions
- Current speech-driven avatar generation systems struggle with long-duration high-resolution videos, exhibiting temporal drifting, quality degradation, and weak prompt adherence as video length increases despite advances in general video diffusion models.
- KlingAvatar 2.0 introduces a spatio-temporal cascade framework that first generates low-resolution blueprint keyframes capturing global motion and semantics, then refines them into high-resolution sub-clips using a first-last frame strategy to ensure temporal coherence and detail preservation in extended videos.
- The Co-Reasoning Director employs three modality-specific LLM experts that collaboratively infer user intent through multi-turn dialogue, converting inputs into hierarchical storylines while refining negative prompts to enhance multimodal instruction alignment and long-form video fidelity.
Introduction
Video generation has advanced through diffusion models and DiT architectures using 3D VAEs for spatio-temporal compression, enabling high-fidelity synthesis but remaining limited to text or image prompts without audio conditioning. Prior avatar systems either rely on intermediate motion representations like landmarks or lack long-term coherence and expressive control for speech-driven digital humans. The authors address this gap by introducing KlingAvatar 2.0, which leverages multimodal large language model reasoning for hierarchical storyline planning and a spatio-temporal cascade pipeline to generate coherent, long-form audio-driven avatar videos with fine-grained expression and environmental interaction.
Method
The authors leverage a spatio-temporal cascade framework to generate long-duration, high-resolution avatar videos with precise lip synchronization and multimodal instruction alignment. The pipeline begins with a Co-Reasoning Director that processes input modalities—reference image, audio, and text—through a multi-turn dialogue among three modality-specific LLM experts. These experts jointly infer user intent, resolve semantic conflicts, and output structured global and local storylines, including positive and negative prompts that guide downstream generation. As shown in the framework diagram, the Director’s output feeds into a hierarchical diffusion cascade: first, a low-resolution Video DiT generates blueprint keyframes capturing global motion and layout; these are then upscaled by a high-resolution Video DiT to enrich spatial detail while preserving identity and composition. Subsequently, a low-resolution diffusion model expands the high-resolution keyframes into audio-synchronized sub-clips using a first-last frame conditioning strategy, augmented with blueprint context to refine motion and expression. An audio-aware interpolation module synthesizes intermediate frames to ensure temporal smoothness and lip-audio alignment. Finally, a high-resolution Video DiT performs super-resolution on the sub-clips, yielding temporally coherent, high-fidelity video segments.
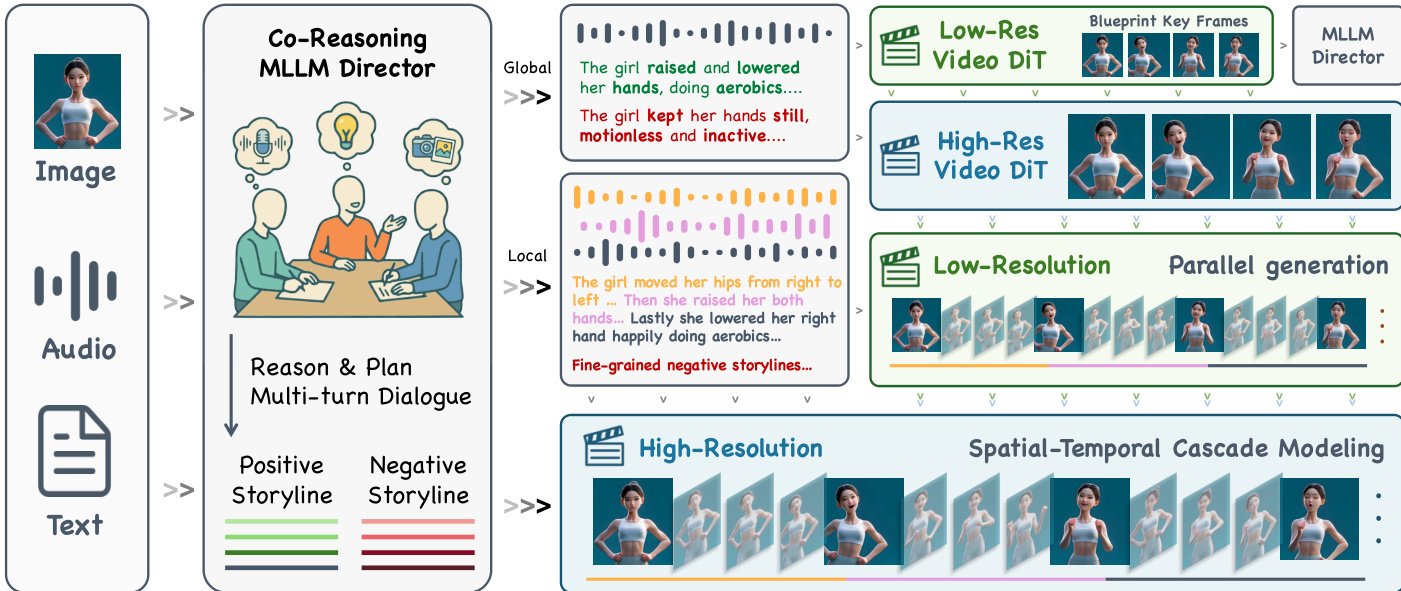
To support multi-character scenes with identity-specific audio control, the authors introduce a mask-prediction head attached to deep layers of the Human Video DiT. These deep features exhibit spatially coherent regions corresponding to individual characters, enabling precise audio injection. During inference, reference identity crops are encoded and cross-attended with video latent tokens to regress per-frame character masks, which gate the injection of character-specific audio streams into corresponding spatial regions. For training, the DiT backbone remains frozen while only the mask-prediction modules are optimized. To scale data curation, an automated annotation pipeline is deployed: YOLO detects characters in the first frame, DWPose estimates keypoints, and SAM2 segments and tracks each person across frames using bounding boxes and keypoints as prompts. The resulting masks are validated against per-frame detection and pose estimates to ensure annotation quality. As shown in the figure, this architecture enables fine-grained control over multiple characters while maintaining spatial and temporal consistency.

Experiment
- Accelerated video generation via trajectory-preserving distillation with custom time schedulers validated improved inference efficiency and generative performance, surpassing distribution matching approaches in stability and flexibility.
- Human preference evaluation on 300 diverse test cases (Chinese/English speech, singing) demonstrated superior (G+S)/(B+S) scores against HeyGen, Kling-Avatar, and OmniHuman-1.5, particularly excelling in motion expressiveness and text relevance.
- Generated videos achieved more natural hair dynamics, precise camera motion alignment (e.g., correctly folding hands per prompt), and emotionally coherent expressions, while per-shot negative prompts enhanced temporal stability versus baselines' generic artifact control.
Results show KlingAvatar 2.0 outperforms all three baselines across overall preference and most subcategories, with particularly strong gains in motion expressiveness and text relevance. The model achieves the highest scores against Kling-Avatar in motion expressiveness (2.47) and text relevance (3.73), indicating superior alignment with multimodal instructions and richer dynamic expression. Visual quality and motion quality also consistently favor KlingAvatar 2.0, though face-lip synchronization scores are closer to baselines.
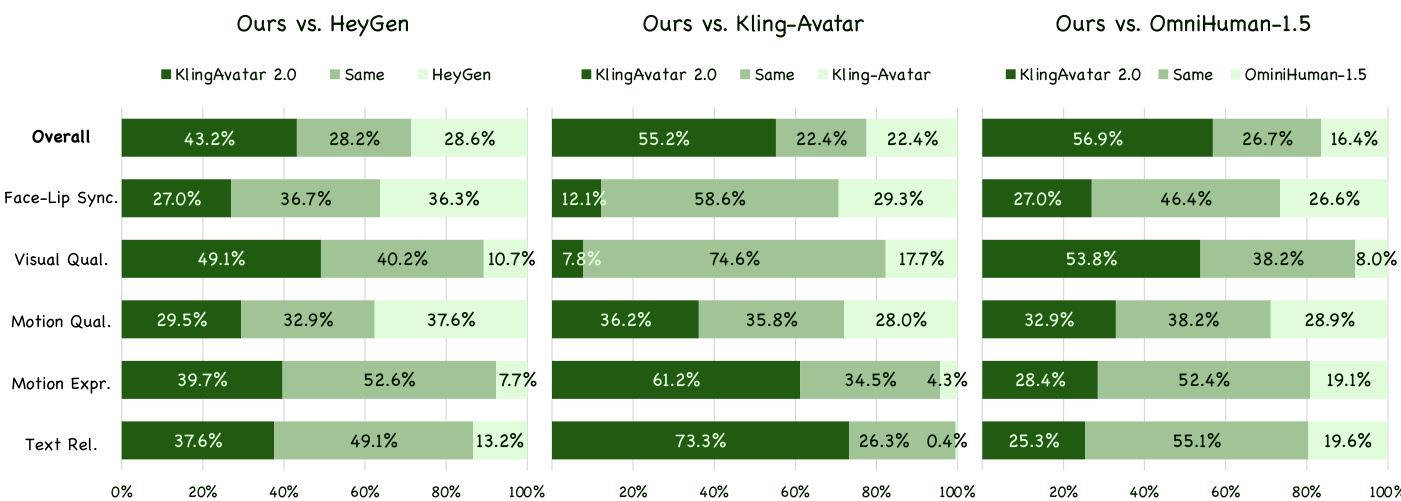
Results show KlingAvatar 2.0 outperforms all three baselines across overall preference and most subcategories, with particularly strong gains in motion expressiveness and text relevance. The model achieves the highest scores against Kling-Avatar in motion expressiveness (2.47) and text relevance (3.73), indicating superior alignment with multimodal instructions and richer dynamic expression. Visual quality and motion quality also consistently favor KlingAvatar 2.0, though face-lip synchronization scores are closer to baselines.
