Command Palette
Search for a command to run...
비디오 리얼리티 테스트: AI 생성 ASMR 영상은 VLM과 인간을 속일 수 있는가?
비디오 리얼리티 테스트: AI 생성 ASMR 영상은 VLM과 인간을 속일 수 있는가?
Jiaqi Wang Weijia Wu Yi Zhan Rui Zhao Ming Hu James Cheng Wei Liu Philip Torr Kevin Qinghong Lin
초록
최근 영상 생성 기술의 발전으로 인해 현실과 구분하기 어려울 정도로 생생한 콘텐츠가 등장하면서, 인공지능 생성 영상(AIGC) 탐지 문제가 새로운 사회적 과제로 부상하고 있다. 기존의 AIGC 탐지 기준 평가 데이터셋은 주로 오디오를 포함하지 않은 영상만을 평가하며, 넓은 서사 영역을 대상으로 하며 분류(classification)에만 초점을 맞추고 있다. 그러나 현재 최첨단 영상 생성 모델이 인간과 비전-언어 모델(VLM)을 신뢰할 만큼 속일 수 있는 몰입감 있는 오디오-비주얼 결합 영상을 생성할 수 있는지 여부는 여전히 명확하지 않다. 이를 해결하기 위해 우리는 강력한 오디오-비주얼 결합 조건 하에서 지각적 현실감을 평가할 수 있는 새로운 영상 기준 평가 세트인 Video Reality Test(VRT)를 제안한다. 본 연구의 주요 특징은 다음과 같다:(i) 몰입형 ASMR 영상-오디오 소스: 정교하게 수집된 실제 ASMR 영상 데이터를 기반으로 하며, 다양한 객체, 동작, 배경을 포함한 세밀한 행동-객체 상호작용을 타깃으로 한다.(ii) 동료 평가(peer-review evaluation): 공격적 생성자-검토자 프로토콜을 도입하여, 영상 생성 모델은 검토자를 속이기 위한 생성자 역할을 하며, VLM은 위조 여부를 탐지하는 검토자 역할을 수행한다. 실험 결과에 따르면, 최고 성능을 보인 생성자 모델인 Veo3.1-Fast는 대부분의 VLM을 속일 수 있었으며, 가장 강력한 검토자인 Gemini 2.5-Pro의 정확도는 56%에 그쳤다(임의 추측 기준 50% 수준). 이는 인간 전문가(81.25%)의 성능에 크게 미치지 못함을 보여준다. 오디오를 추가하면 진위 구분 능력이 향상되지만, 수면 아래에 숨겨진 표면적 신호(예: 워터마크)는 여전히 모델을 오도하는 데 큰 영향을 미친다. 이러한 결과는 현재 영상 생성 기술의 현실감 한계를 명확히 하며, VLM의 지각적 정확성과 오디오-비주얼 일관성에 대한 한계를 드러낸다. 본 연구의 코드는 다음 링크에서 공개된다: https://github.com/video-reality-test/video-reality-test.
One-sentence Summary
Researchers from CUHK, NUS, Video Rebirth, and University of Oxford propose Video Reality Test, an ASMR-based benchmark evaluating audio-visual realism in AI-generated videos through an adversarial creator-reviewer protocol; their tests reveal generators like Veo3.1-Fast fool VLMs (Gemini 2.5-Pro: 56% accuracy) despite human superiority (81.25%), highlighting audio's role and watermark vulnerabilities in AIGC detection.
Key Contributions
- Introduces Video Reality Test, the first benchmark specifically designed to evaluate AI-generated video detection under tight audio-visual coupling using immersive ASMR content, addressing the gap where prior work ignored audio and focused on non-deceptive classification tasks without testing if videos can fool humans or VLMs. This benchmark features 149 curated real ASMR videos with diversity across objects, actions, and backgrounds, paired with AI-generated counterparts for rigorous real-vs-fake assessment.
- Proposes a novel Peer-Review evaluation framework where video generation models act as adversarial "creators" attempting to deceive "reviewers" (VLMs or humans), establishing a competitive arena to jointly benchmark generation and detection capabilities through reciprocal performance metrics. This protocol reveals the dynamic interplay between creators and reviewers, highlighting which models excel at deception or detection.
- Demonstrates through experiments that state-of-the-art generators like Veo3.1-Fast significantly challenge current detection systems, with the strongest VLM reviewer (Gemini 2.5-Pro) achieving only 56% accuracy—far below human experts (81.25%)—while showing that incorporating audio improves discrimination by approximately 5 points, though superficial cues like watermarks still mislead models. These results quantify the realism boundary of modern video generation and expose critical VLM limitations in perceptual fidelity.
Introduction
The rapid proliferation of realistic AI-generated videos threatens information integrity by enabling sophisticated misinformation campaigns. Prior detection methods focused narrowly on facial forgeries or spatial artifacts using benchmarks like FaceForensics++, but struggle with diffusion models that exhibit unprecedented temporal coherence and reduced visual inconsistencies. Existing approaches also fail to holistically evaluate audio-visual realism or model the adversarial dynamic between generators and detectors. The authors introduce Video Reality Test as a unified benchmark that frames detection as a competitive peer-review process between video generators ("creators") and multimodal detectors ("reviewers"), specifically using high-fidelity ASMR content to evaluate both real and synthetic videos across audio-visual dimensions. This framework uniquely addresses the limitations of prior isolated evaluations by enabling scalable assessment of generation quality and detection robustness within a single adversarial ecosystem.
Dataset
- The authors use Video Reality Test, a benchmark built from 149 curated real ASMR videos sourced from YouTube (selected from 1,400 candidates with >900k views as a proxy for human immersion).
- Subset details:
- Easy set: 49 videos; short (3–5 seconds), single-step actions (e.g., cutting food), minimal backgrounds (e.g., dark indoor), low object diversity.
- Hard set: 100 videos; longer (up to 20+ seconds), multi-step actions (e.g., squeezing, peeling), diverse settings (indoor/outdoor), and varied objects (solids like soap, liquids like paint).
- Fake videos are dynamically generated per experiment by K video models, yielding a total dataset size of 149 × (1 + K).
- Usage in the paper:
- Real videos form the baseline; fake videos are generated on-demand using first frames or Gemini-2.5-Pro text descriptions as prompts.
- Data trains a "Peer-Review" game: VLMs ("reviewers") classify videos as real/fake, while generators ("creators") aim to minimize detection rates.
- Evaluation splits measure reviewer accuracy (target: 1 for real, 0 for fake) and creator fakeness rates.
- Processing details:
- Cropping: Raw videos are split at scene transitions (using frame color histograms/Bhattacharyya distance >0.5), then backgrounds/watermarks are removed via grayscale column analysis.
- Metadata: Gemini-2.5-Pro generates immersive text descriptions from 8 evenly sampled frames, avoiding structural markers.
- Curation: Human verification ensures single-theme segments; Qwen3-embedding-4B clusters descriptions into 8 classes, with 12–13 high-quality samples per class selected to balance representation (100 total).
Experiment
- Evaluated VLMs on Video Reality Test ASMR benchmark: top model Gemini-3-Pro achieved 76.27% accuracy across 7 VLMs, significantly below human performance (89.11%), validating current VLMs' limited real-vs-fake detection capability.
- Tested VGMs via fooling rate: Veo3.1-Fast generated videos detected as fake only 12.54% of the time, surpassing Sora2 and open-source models, demonstrating strongest deception ability against VLMs.
- Analyzed audio impact: incorporating audio improved VLM detection accuracy by ~5 points on average, as mismatched audio (e.g., Sora2's human voices in ASMR) provided discriminative cues.
- Assessed watermark influence: GPT-5 and Gemini-2.5-Pro detection accuracy dropped from 95.43% to 52.4% after Sora2 watermark removal, revealing reliance on superficial shortcuts over genuine perceptual analysis.
- Identified VLM bias: models classified 71% of videos as real (including 33% of fake videos), confirming systematic conservative bias toward authenticating content regardless of source.
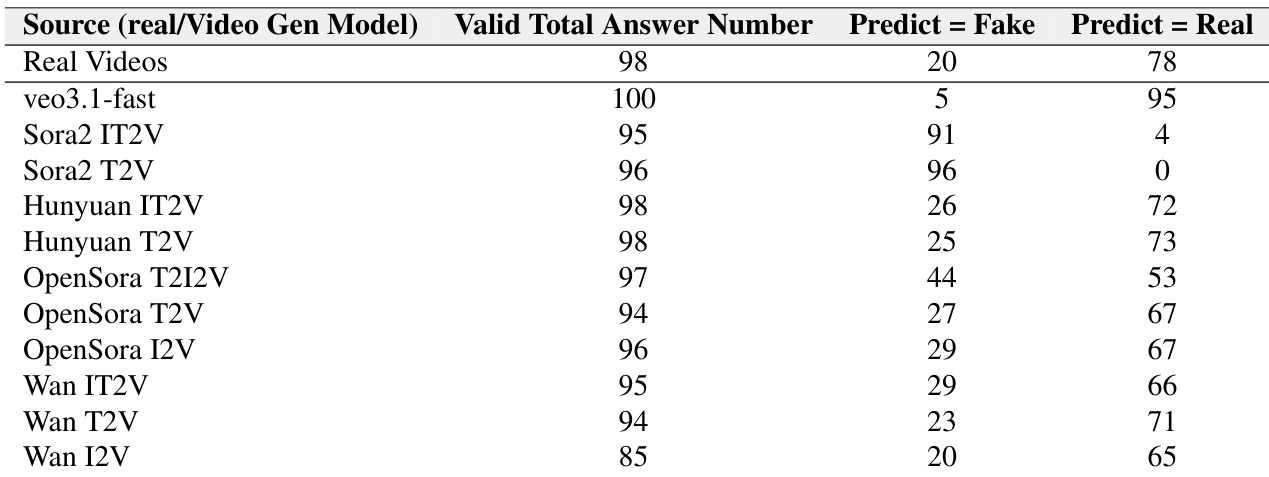
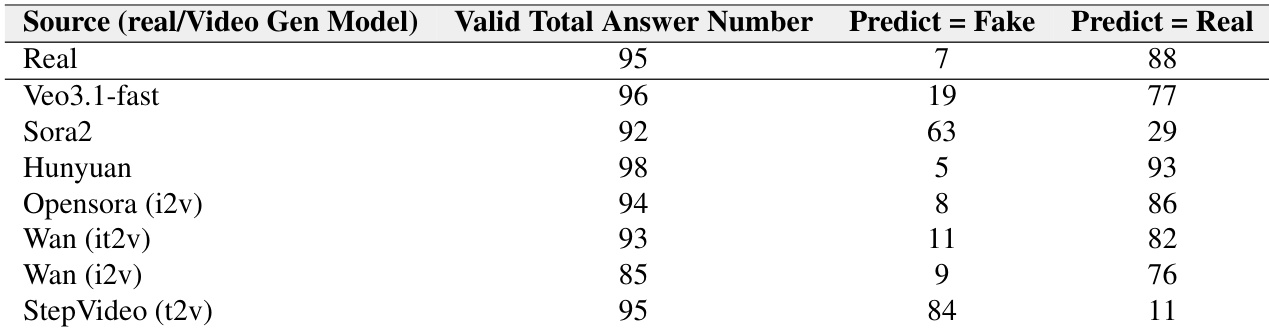
The authors use a peer-review evaluation to assess how well video generation models fool video understanding models, with results showing Veo3.1-fast generates the most deceptive videos, as only 19 out of 96 were correctly identified as fake. Sora2 and StepVideo-t2v videos are more easily detected, with 63 and 84 false predictions respectively, indicating weaker realism. Across all models, VLMs exhibit a strong bias toward classifying videos as real, with real videos being correctly identified 88 times out of 95, while generated videos are often misclassified as real.
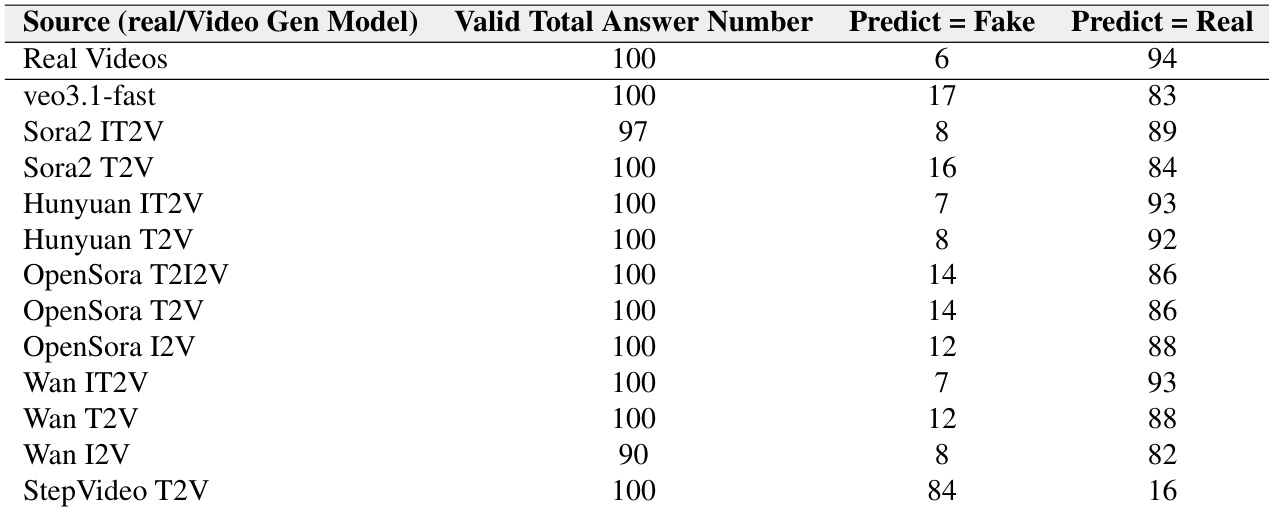
The authors use this table to report how often a video understanding model misclassifies real and generated ASMR videos as real, revealing a strong bias toward labeling videos as authentic. Veo3.1-fast generated videos are most frequently mistaken for real (83 out of 100), while StepVideo T2V videos are most often correctly identified as fake (84 out of 100). Across all models, real videos are overwhelmingly predicted as real (94 out of 100), confirming the model’s conservative tendency to default to “real” even when evaluating synthetic content.
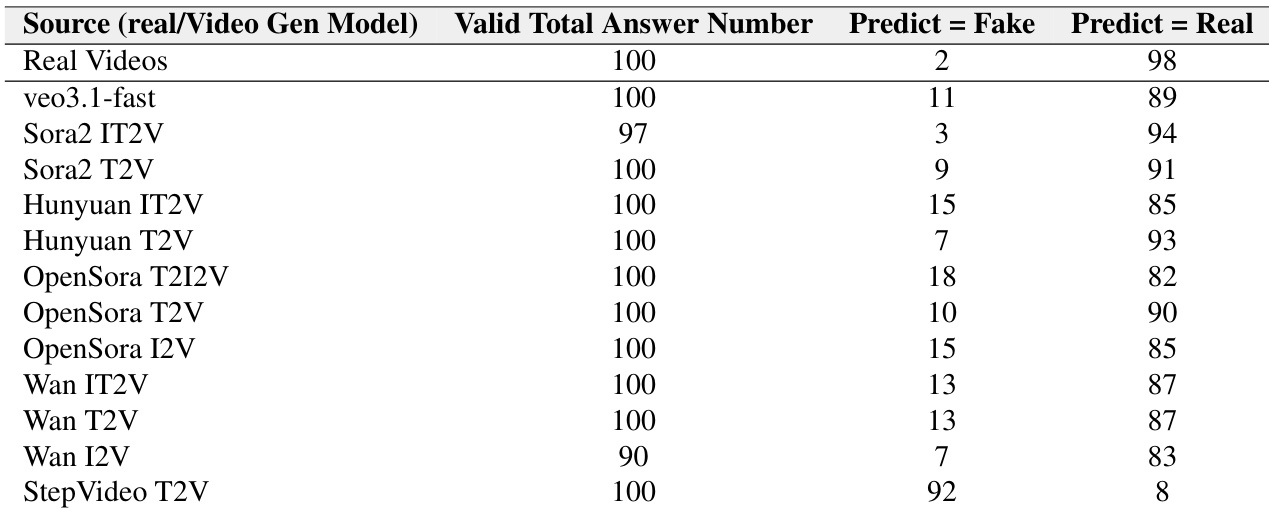
The authors use a peer-review evaluation to test how well video generation models can fool video understanding models, with results showing Veo3.1-fast generates the most deceptive videos, as 89% are misclassified as real. Sora2 and Hunyuan models also produce highly realistic outputs, with detection rates below 15%, while StepVideo T2V is the least convincing, with 92% of its videos correctly identified as fake. Across all models, video understanding systems exhibit a strong bias toward labeling videos as real, even when they are AI-generated.
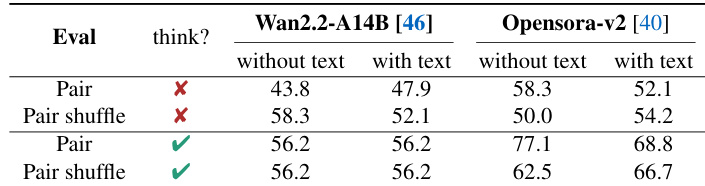
The authors evaluate video understanding models under different prompt and reasoning settings, finding that requiring models to think before answering improves performance for stronger models but offers little benefit for weaker ones. Results also show that preference-based evaluation (comparing real and fake pairs) is easier than single-video judgment, with models achieving higher accuracy in paired settings regardless of whether the fake video is generated from the same or a different real source.
The authors use this table to show how often different video generation models fool a video understanding model, with Veo3.1-fast generating the most deceptive videos as only 5% were correctly identified as fake. Sora2 models show extreme bias, with Sora2 T2V being misclassified as real 100% of the time, while Sora2 IT2V was detected as fake in 91% of cases, suggesting model configuration significantly affects detectability. Across all models, the VLM consistently predicts videos as real rather than fake, confirming a strong classification bias toward authenticity.