Command Palette
Search for a command to run...
텍스트에서 3D 생성에 대한 RL 도입은 준비되었는가? 점진적 탐구
텍스트에서 3D 생성에 대한 RL 도입은 준비되었는가? 점진적 탐구
초록
강화학습(RL)은 이전에 대규모 언어 모델 및 다중모달 모델에서 효과적임이 입증된 바 있으며, 최근에는 2차원 이미지 생성에 성공적으로 확장되었다. 그러나 3차원 객체는 전반적인 기하학적 일관성과 세밀한 국부적 질감을 요구하기 때문에 공간적 복잡성이 높아, RL을 3차원 생성에 적용하는 것은 여전히 거의 탐색되지 않은 영역이다. 이로 인해 3차원 생성은 보상 설계 및 강화학습 알고리즘에 매우 민감하게 반응한다. 이러한 도전 과제를 해결하기 위해, 우리는 여러 차원에서 텍스트 기반 3차원 자동 회귀 생성을 위한 강화학습에 대한 최초의 체계적인 연구를 수행한다. (1) 보상 설계: 보상 차원과 모델 선택을 평가하여, 인간 선호와의 일치가 핵심임을 보이며, 일반적인 다중모달 모델이 3차원 특성에 대해 강력한 신호를 제공함을 입증한다. (2) 강화학습 알고리즘: GRPO 변형 버전을 연구하며, 토큰 수준 최적화의 효과성을 강조하고, 학습 데이터 및 반복 횟수의 확장성도 추가로 탐구한다. (3) 텍스트 기반 3차원 벤치마크: 기존 벤치마크는 3차원 생성 모델의 암묵적 추론 능력을 측정하지 못하므로, 우리는 MME-3DR을 도입한다. (4) 고급 강화학습 패러다임: 3차원 생성의 자연스러운 계층 구조에 착안하여, 전역에서 국부로의 계층적 3차원 생성을 전용 보상 집합을 통해 최적화하는 Hi-GRPO를 제안한다. 이러한 통찰을 바탕으로, 거친 형태부터 질감 개선에 이르기까지 전반적인 생성 과정을 전문적으로 다루는, 최초의 강화학습 기반 텍스트 기반 3차원 생성 모델인 AR3D-R1을 개발하였다. 본 연구가 3차원 생성을 위한 강화학습 기반 추론에 대한 통찰을 제공하기를 기대한다. 코드는 https://github.com/Ivan-Tang-3D/3DGen-R1 에 공개된다.
One-sentence Summary
Researchers from Northwestern Polytechnical University, Peking University, and The Hong Kong University of Science and Technology propose AR3D-R1, the first reinforcement learning-enhanced text-to-3D autoregressive model, introducing Hi-GRPO for hierarchical global-to-local optimization and MME-3DR as a new benchmark, advancing 3D generation through improved reward design and token-level RL strategies.
Key Contributions
- The paper identifies key challenges in applying reinforcement learning (RL) to text-to-3D generation, such as sensitivity to reward design and algorithm choice due to 3D objects' geometric and textural complexity, and conducts the first systematic study of RL in this domain, evaluating reward models and RL algorithms within an autoregressive framework.
- It introduces MME-3DR, a new benchmark with 249 reasoning-intensive 3D generation cases across five challenging categories, and proposes Hi-GRPO, a hierarchical RL method that leverages dedicated reward ensembles to optimize global-to-local 3D structure and texture generation.
- Based on these insights, the authors develop AR3D-R1, the first RL-enhanced text-to-3D model, which achieves significant improvements over baseline methods on MME-3DR, demonstrating the effectiveness of token-level optimization and general multi-modal reward models in 3D generation.
Introduction
Reinforcement learning (RL) has proven effective in enhancing reasoning and generation in large language and 2D image models, but its application to text-to-3D generation remains underexplored due to the increased spatial complexity and need for globally consistent geometry and fine-grained textures in 3D objects. Prior work in 3D generation has largely relied on pre-training and fine-tuning, with limited exploration of RL-based optimization, while existing benchmarks fail to assess models’ implicit reasoning capabilities—such as spatial, physical, and abstract reasoning—leading to an overestimation of model performance. The authors conduct the first systematic investigation of RL in autoregressive text-to-3D generation, evaluating reward models, RL algorithms, and training dynamics, and introduce MME-3DR, a new benchmark targeting reasoning-intensive 3D generation tasks. They further propose Hi-GRPO, a hierarchical RL framework that optimizes coarse-to-fine 3D generation using dedicated reward ensembles, and develop AR3D-R1, the first RL-enhanced text-to-3D model, which achieves state-of-the-art performance by improving both structural coherence and texture fidelity.
Dataset
-
The authors use a combination of three primary 3D object datasets for training: Objaverse-XL, HSSD, and ABO, with evaluation performed on Toys4K.
-
Objaverse-XL serves as a large-scale source with over 10 million 3D objects collected from platforms like GitHub, Thingiverse, Sketchfab, and Polycam. It undergoes strict deduplication and rendering validation to ensure quality and diversity across categories and fine-grained attributes.
-
HSSD contributes approximately 18,656 real-world object models embedded in 211 high-quality synthetic indoor scenes. The dataset emphasizes realistic indoor layouts, semantic structure, and object relationships.
-
ABO provides around 8,000 high-quality 3D models of household items, drawn from nearly 147,000 product listings and 400,000 catalog images. These models include detailed material, geometric, and attribute annotations.
-
For evaluation, the authors use Toys4K, which contains about 4,000 3D object instances across 105 categories, offering diverse shapes and significant variation in form.
-
During training, prompts are sampled from Objaverse-XL, HSSD, and ABO, and the model is trained on a mixture of these sources without specified ratios. The base model is ShapeLLM-Omni, trained for 1,200 steps using 8 GPUs, a per-device batch size of 1, and gradient accumulation over 2 steps, resulting in an effective batch size of 16.
-
The training setup uses a learning rate of 1 × 10⁻⁶, a β value of 0.01, and a group size of 8. A configurable loss weight λ = 1.0 is applied to supervise global planning using final quality scores.
-
Reward models are served via the vLLM API framework, but no explicit cropping strategies, metadata construction methods, or additional preprocessing details are described in the provided text.
Method
The authors leverage a hierarchical reinforcement learning paradigm, Hi-GRPO, to decompose text-to-3D generation into two distinct, sequential stages: global geometric planning followed by local appearance refinement. This architecture explicitly models the coarse-to-fine nature of human 3D perception and enables targeted optimization at each level of detail.
In Step 1, the model receives the 3D textual prompt and a high-level semantic instruction to generate a concise semantic reasoning plan. This plan, represented as a sequence of semantic tokens {si,1,…,si,∣si∣}, serves to clarify object subcategories, establish spatial layouts of key components, and resolve ambiguous terms. As shown in the framework diagram, this semantic reasoning is then combined with the original prompt and a mesh start token to condition the 3D autoregressive model. The model generates a sequence of coarse 3D tokens {ti,1,…,ti,M}, which are decoded via a VQVAE decoder into a triangular mesh Mi(1). This initial output captures the global structure and basic color distribution, such as ensuring balanced proportions and a gradient of pink from center to outer petals for a flower.
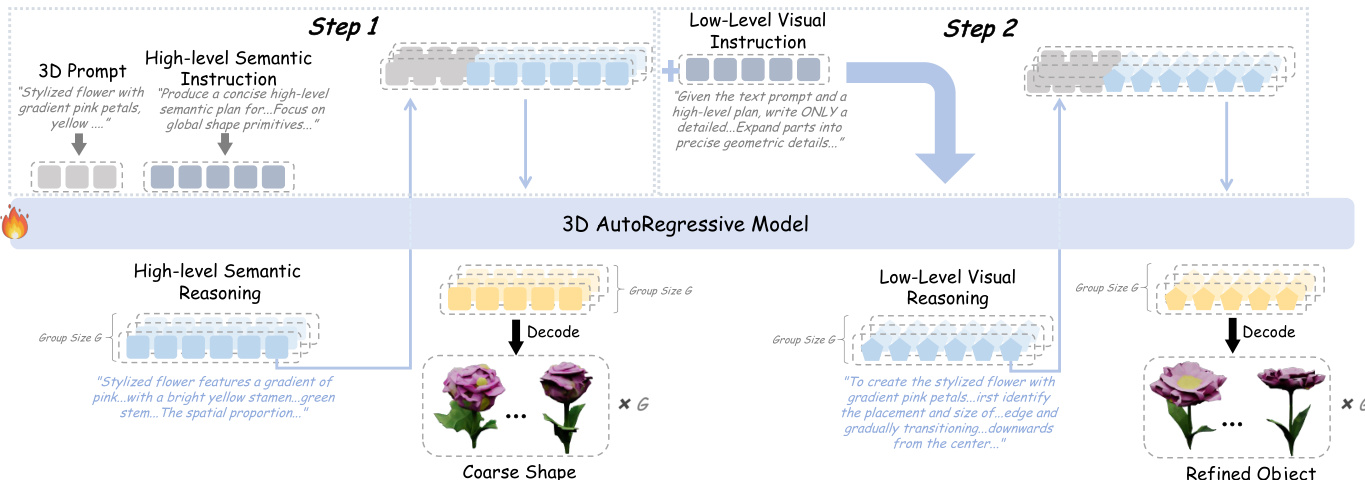
In Step 2, the model is conditioned on the original prompt, the previously generated high-level semantic reasoning, and a low-level visual instruction. It then generates a sequence of visual reasoning tokens {vi,1,…,vi,∣vi∣}, which focus on refining local appearance details. This includes specifying textures, interactions between components, and local attributes like element counts and symmetry. The model subsequently generates a second sequence of 3D tokens {oi,1,…,oi,M}, which are decoded into the final, refined mesh Mi(2). This step adds fine-grained details such as petal textures, stamen-petal spatial relations, and leaf counts, transforming the coarse shape into a high-fidelity 3D asset.
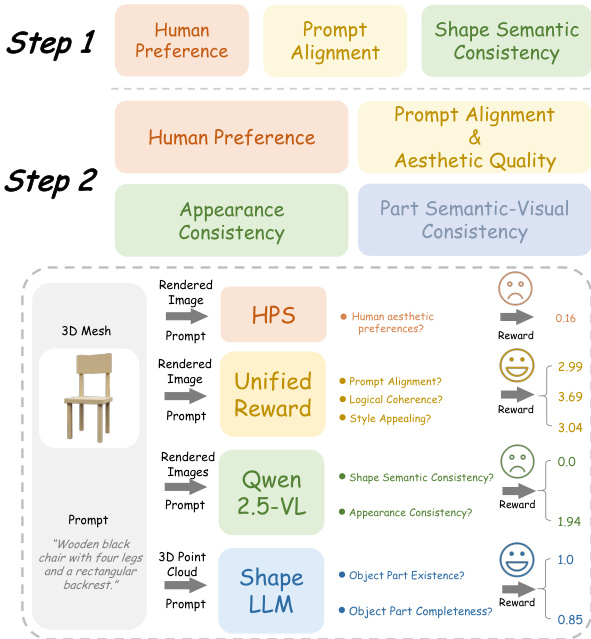
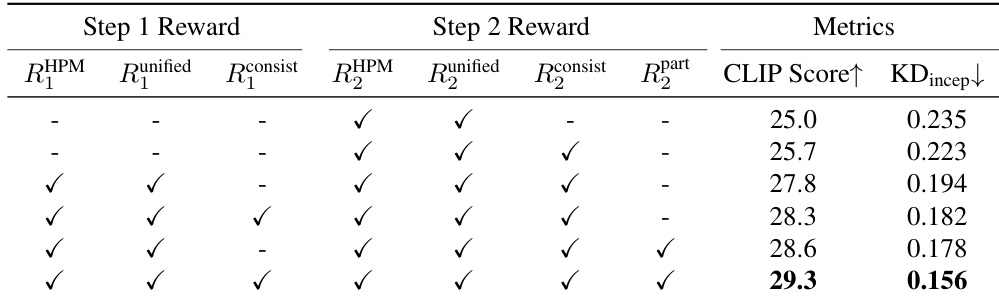
The training process employs a tailored reward ensemble for each step to guide the policy gradient optimization. As illustrated in the reward design figure, Step 1 rewards focus on global alignment, including human preference (HPS), prompt alignment (UnifiedReward), and geometric consistency (Qwen2.5-VL). Step 2 rewards emphasize local refinement, incorporating human preference, appearance quality (UnifiedReward-2.0), cross-view consistency (Qwen2.5-VL), and component completeness (ShapeLLM). Each reward is dimension-normalized to ensure balanced contribution. Critically, the reward from Step 2 is backpropagated to Step 1 via a configurable weight λ, allowing the final output quality to supervise the initial global planning. The total loss is the sum of independent policy losses computed for each step, using a clipped surrogate objective with asymmetric clipping thresholds to promote exploration and prevent entropy collapse.
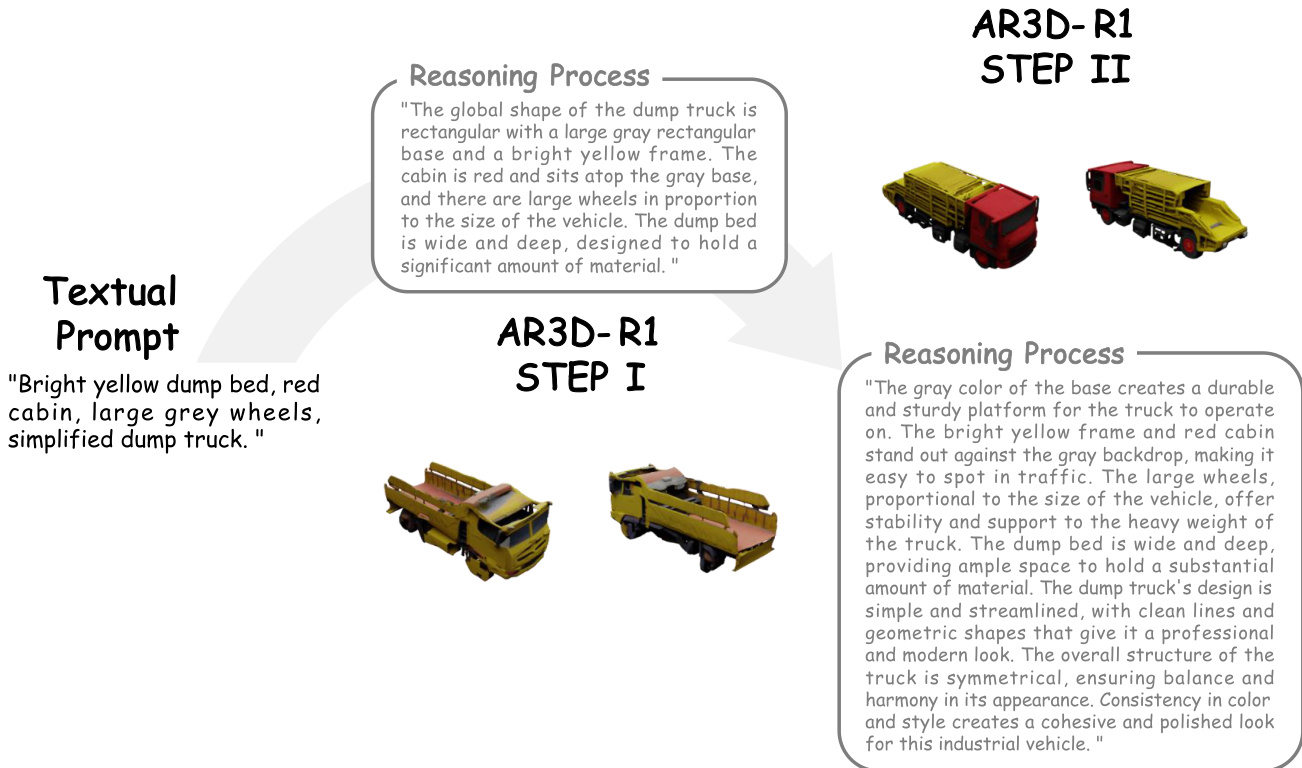
The model’s output during inference follows this same two-step progression. As shown in the qualitative results, the first step produces a basic, geometrically consistent shape, while the second step refines it with detailed textures, colors, and part structures, resulting in a final mesh that closely aligns with the prompt’s specifications.
Experiment
Respond strictly in English.
The authors use a hierarchical reward system across two generation steps, combining human preference, unified aesthetic, 3D consistency, and part-level rewards. Results show that including step-specific rewards—especially part-level guidance in Step 2—yields the highest CLIP Score and lowest KD_incep, indicating improved semantic alignment and structural fidelity. Omitting any component, particularly step-specific or part-level rewards, leads to measurable performance degradation.
The authors use textual reasoning as a prior step before 3D token generation, finding that this approach improves CLIP Score from 22.7 in the base model to 24.0 when reasoning is included, outperforming direct generation without reasoning (23.4). Results show that incorporating reasoning enhances the model’s ability to plan semantically coherent 3D outputs.

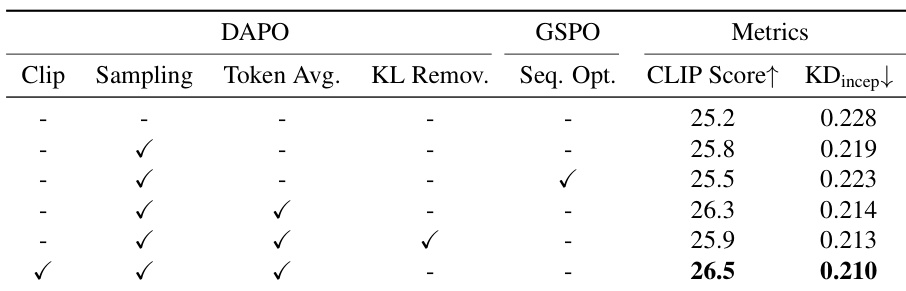
Results show that combining Dynamic Sampling, Token-level Loss Aggregation, and Decoupled Clip in DAPO yields the highest CLIP Score of 26.5 and lowest KD_incep of 0.210, outperforming both vanilla GRPO and GSPO variants. Token-level strategies consistently improve performance over sequence-level optimization, while retaining the KL penalty stabilizes training and prevents degradation.
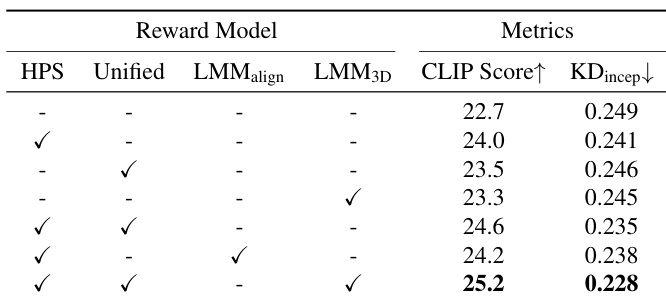
The authors use a combination of human preference (HPS), UnifiedReward, and LMM-based 3D consistency rewards to optimize 3D autoregressive generation via GRPO. Results show that combining all three reward signals yields the highest CLIP Score (25.2) and lowest KD_incep (0.228), outperforming any single or partial combination. HPS alone provides the strongest baseline improvement, while LMM_3D adds unique value in enhancing cross-view structural coherence.
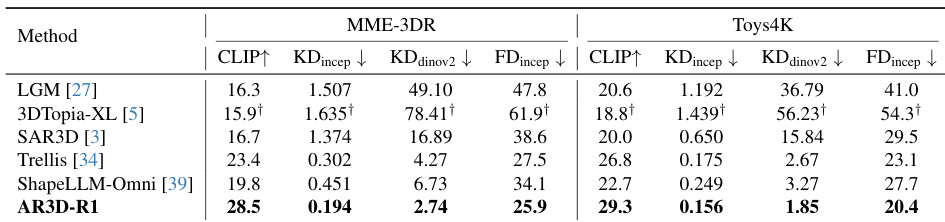
Results show that AR3D-R1 outperforms prior methods across both MME-3DR and Toys4K benchmarks, achieving the highest CLIP scores and lowest KD and FD metrics. The model demonstrates superior text-to-3D alignment and structural coherence, particularly in complex object categories. These gains stem from its hierarchical RL framework combining step-specific rewards and textual reasoning guidance.