Command Palette
Search for a command to run...
Voxify3D: 픽셀 아트가 볼륨 렌더링과 만난다
Voxify3D: 픽셀 아트가 볼륨 렌더링과 만난다
Yi-Chuan Huang Jiewen Chan Hao-Jen Chien Yu-Lun Liu
초록
복스셀 아트는 게임 및 디지털 미디어에서 널리 사용되는 독특한 스타일링 기법이지만, 기하학적 추상화, 의미 유지, 이산 색상 일관성이라는 상충되는 요구사항으로 인해 3D 메시로부터 자동 생성하는 것은 여전히 도전적인 과제이다. 기존 방법들은 기하학적 구조를 과도하게 단순화하거나, 복스셀 아트의 픽셀 정밀도와 팔레트 제약을 충족하지 못한다. 본 연구에서는 3D 메시 최적화와 2D 픽셀 아트 감독을 연결하는 미분 가능한 이단계 프레임워크인 Voxify3D를 제안한다. 본 연구의 핵심 혁신은 세 가지 구성 요소의 상호보완적 통합에 있다: (1) 정사영 픽셀 아트 감독을 통해 원근 왜곡을 제거하고 정밀한 복스셀-픽셀 정렬을 가능하게 한다; (2) 패치 기반 CLIP 정렬을 통해 이산화 과정에서 의미 정보를 유지한다; (3) 팔레트 제약을 갖춘 Gumbel-Softmax 양자화를 통해 이산 색상 공간에서 미분 가능한 최적화를 가능하게 하며, 조절 가능한 팔레트 전략을 지원한다. 이러한 통합은 극한의 이산화 하에서도 의미 유지, 볼륨 렌더링을 통한 픽셀 아트 미학의 구현, 그리고 엔드투엔드 이산 최적화라는 핵심 도전 과제를 해결한다. 다양한 캐릭터에 대한 실험 결과에서 뛰어난 성능을 입증하였으며, CLIP-IQA 점수 37.12, 사용자 선호도 77.90%를 기록하였고, 색상 수(28색), 해상도(20배50배) 조절이 가능한 추상화를 실현하였다. 프로젝트 페이지: https://yichuanh.github.io/Voxify-3D/
Summarization
Researchers from National Taiwan University propose Voxify3D, a differentiable two-stage framework that generates high-fidelity voxel art from 3D meshes by combining orthographic pixel art supervision, patch-based CLIP alignment, and palette-constrained Gumbel-Softmax quantization, enabling semantic preservation, precise voxel-pixel alignment, and controllable color discretization for game-ready assets.
Key Contributions
- Voxify3D addresses the challenge of generating semantically meaningful voxel art from 3D meshes by introducing orthographic pixel art supervision across six canonical views, eliminating perspective distortion and enabling precise voxel-pixel alignment for effective gradient-based optimization.
- The method preserves critical semantic features under extreme geometric discretization (20×–50× resolution reduction) through a patch-based CLIP loss that maintains local and global object identity where standard perceptual losses fail.
- Voxify3D enables end-to-end optimization with controllable discrete color palettes (2–8 colors) via palette-constrained Gumbel-Softmax quantization, supporting flexible palette extraction strategies and achieving superior aesthetic quality, as validated by high CLIP-IQA scores (37.12) and strong user preference (77.90%).
Introduction
The authors leverage the growing demand for stylized 3D content in games and digital media to address the challenge of automating high-quality voxel art generation from 3D meshes. Existing methods either focus on 2D pixel art—unsuitable for 3D due to projection misalignment and view inconsistency—or rely on photorealistic neural rendering that lacks stylistic abstraction. Prior approaches also fail to preserve semantic features under extreme discretization and struggle with discrete color optimization, while procedural tools require extensive manual tuning.
The authors’ main contribution is Voxify3D, a two-stage framework that bridges 3D voxel optimization with 2D pixel art supervision to generate semantically faithful, palette-constrained voxel art. It overcomes fundamental misalignment and quantization issues through tightly coupled rendering and loss design.
Key innovations include:
- Orthographic pixel art supervision using six canonical views to eliminate perspective distortion and enable precise, gradient-based stylization.
- Resolution-adaptive patch-based CLIP loss that preserves critical semantic features (e.g., facial details) even under 20×–50× discretization, where global perceptual losses fail.
- Palette-constrained differentiable quantization via Gumbel-Softmax with user-controllable palette extraction (K-means, Max-Min, Median Cut, Simulated Annealing), enabling end-to-end optimization of discrete color spaces (2–8 colors).
Method
The authors leverage a two-stage framework to convert 3D meshes into stylized voxel art, balancing geometric fidelity with semantic abstraction. The pipeline begins with coarse voxel grid initialization and progresses to fine-tuning under pixel-art supervision, incorporating semantic guidance and discrete color quantization for stylized output.
In the first stage, the authors adapt Direct Voxel Grid Optimization (DVGO) to construct an explicit voxel radiance field. This grid comprises two components: a density grid d for spatial occupancy and an RGB color grid c=(r,g,b) for appearance. The grid resolution is determined by dividing the object’s bounding box into (W/cell_size)3 voxels, where W is the canonical orthographic image width and cell_size defines the pixel-to-voxel scale. Volume rendering along a ray r computes the final color C(r) using the standard compositing formula:
C(r)=k=1∑NTkαkck,Tk=exp(−j=1∑k−1djδj),αk=1−exp(−dkδk),where N is the number of samples, dk is the density, δk is the step size, Tk is accumulated transmittance, and αk is the opacity at sample k. The coarse grid is optimized using a composite loss:
Ltotal=Lrender+λdLdensity+λbLbg,where Lrender minimizes MSE between rendered and target colors, Ldensity applies TV regularization to enforce spatial smoothness, and Lbg uses entropy loss to suppress background artifacts. This stage provides a geometrically and chromatically stable initialization.
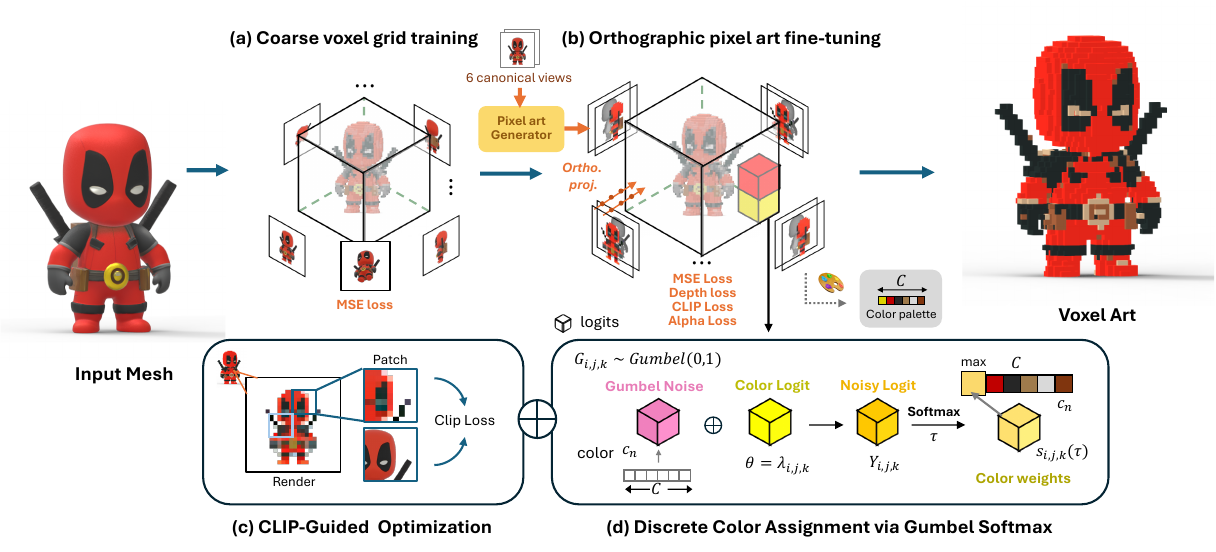
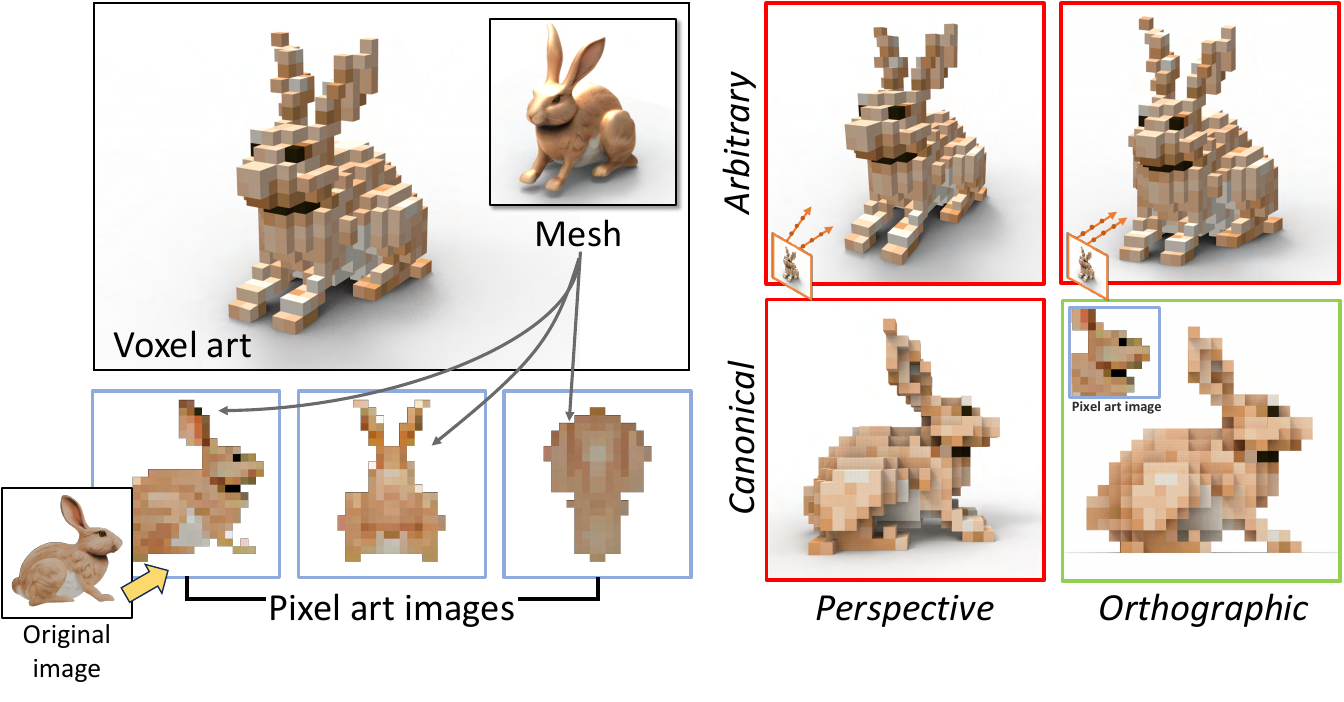
In the second stage, the authors fine-tune the voxel grid using orthographic pixel art supervision generated from six axis-aligned views. This setup ensures pixel-to-voxel alignment without perspective distortion, as illustrated in the comparison between perspective and orthographic projections. Orthographic rays are defined as ri(t)=oi+td, where oi is the ray origin for pixel pi and d is a fixed direction. The authors apply three key losses: pixel-level MSE Lpixel=∥C(r)−Cpixel∥22, depth consistency Ldepth=∥D(r)−Dgt∥1, and alpha regularization Lα=∥Mα⊙αˉ∥2, where Mα is a binary mask from the pixel art alpha channel and αˉ is the accumulated opacity. These losses jointly preserve structure, enforce clean silhouettes, and suppress floating density in background regions.
To maintain semantic alignment during stylization, the authors introduce a CLIP-based perceptual loss. Half of the rays are sampled to form image patches, and CLIP features are extracted from both rendered patches I^patch and corresponding mesh-based patches Ipatchmesh. The loss is computed as:
Lclip=1−cos(CLIP(I^patch), CLIP(Ipatchmesh)),where cosine similarity encourages semantic fidelity while allowing stylistic abstraction.
To achieve clean, stylized outputs with a coherent palette, the authors replace the RGB color grid with a learned color-logit grid. Each voxel (i,j,k) stores a logit vector λi,j,k∈RC, where C is the number of colors in a predefined palette extracted from the pixel art views. During training, Gumbel noise Gi,j,k∼Gumbel(0,1) is added to produce noisy logits:
Yi,j,k=λi,j,k+Gi,j,k.A temperature-controlled softmax then computes selection probabilities:
si,j,k,n(τ)=∑n′=1Cexp(Yi,j,k,n′/τ)exp(Yi,j,k,n/τ),where τ is annealed during training to transition from soft exploration to discrete selection. The final RGB value is a weighted sum over the palette:
RGBi,j,k=n=1∑Csi,j,k,n⋅cn.In the forward pass, a straight-through estimator uses argmaxnsi,j,k,n for discrete selection, while gradients flow through the soft weights. After training, the voxel color is assigned as:
RGBi,j,kvoxel=cargmaxnλi,j,k,n.This enables end-to-end optimization of discrete color assignments while preserving differentiability during training.
The overall fine-tuning loss is a weighted sum:
Ltotal=λpixelLpixel+λdepthLdepth+λalphaLalpha+λclipLclip,where Lpixel, Ldepth, and Lalpha supervise geometry and appearance, and Lclip provides semantic guidance. Training is scheduled to prioritize CLIP loss early (until 6000 iterations), then shift focus to silhouette refinement via Lalpha. After 4500 iterations, optimization is restricted to the front view to refine salient features while preserving global consistency.
Experiment
- Qualitative comparisons on eight character meshes show the proposed method preserves sharp edges and key features (e.g., ears, eyes) across 25×–50× resolutions, outperforming IN2N, Vox-E, and Blender in consistency, stylization, and semantic alignment.
- Quantitative evaluation using CLIP-IQA on 35 character meshes shows the method achieves the highest average cosine similarity between GPT-4-generated prompts and rendered images, indicating superior semantic fidelity and stylization.
- Ablation study confirms the necessity of key components: removing pixel art supervision, orthographic projection, coarse initialization, depth loss, CLIP loss, or Gumbel Softmax leads to blurred results, distortions, or color ambiguity.
- User study with 72 participants shows the method wins 77.90% of votes for abstract detail, 80.36% for visual appeal, and 96.55% for geometry preservation against four baselines.
- Expert study with 10 art-trained participants shows 88.89% preference for results using Gumbel Softmax in color quantization, highlighting its role in achieving clear edges and dominant tones.
- Color palette controllability is demonstrated across 2–8 colors using K-means, Median Cut, Max-Min, and Simulated Annealing, with K-means as the default.
- Additional comparisons show the method outperforms Gemini 3 in controllable voxel resolution and color, and Rodin in geometric fidelity, due to multi-view optimization.
- Runtime analysis reports total generation time of under 2 hours on an RTX 4090 (8.5 min for Stage 1, 108 min for Stage 2), faster than SD-piXL (~4h).
- Failure cases occur on highly complex shapes at low resolutions, suggesting future potential in adaptive voxel grids.
The authors use CLIP-IQA to evaluate semantic fidelity by computing cosine similarity between GPT-4 generated prompts and rendered voxel outputs across 35 character meshes. Results show their method achieves the highest score of 37.12, outperforming all baselines including Blender (36.31), Pixel (35.53), and Vox-E (35.02), with IN2N scoring lowest at 23.93. This confirms superior semantic alignment and stylized abstraction in their approach.

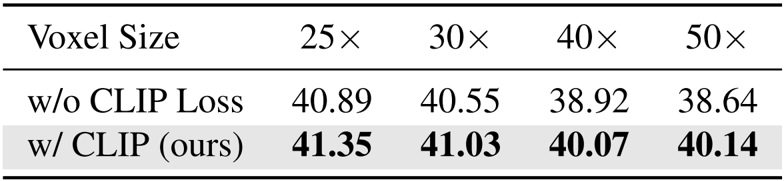
The authors evaluate the impact of CLIP loss across different voxel resolutions, showing that incorporating CLIP loss consistently improves semantic alignment compared to ablations without it. Results indicate higher CLIP-IQA scores across all tested voxel sizes (25× to 50×), confirming that CLIP loss enhances character identity preservation during voxel abstraction.
The authors evaluate their method against four baselines using a user study with 72 participants, measuring performance across abstract detail, visual appeal, and geometry preservation. Results show their method receives 77.90% of votes for abstract detail, 80.36% for visual appeal, and 96.55% for geometry faithfulness, substantially outperforming all alternatives.

The authors evaluate color quantization using a user study with 10 art-trained participants, comparing results with and without Gumbel-Softmax across 10 example pairs. Results show that 88.89% of participants preferred the outputs generated with Gumbel-Softmax for voxel art appeal, highlighting its role in producing clear edges and dominant tones.
