Command Palette
Search for a command to run...
ASGuard: Targeted Jailbreaking Attack을 완화하기 위한 Activation-Scaling Guard
ASGuard: Targeted Jailbreaking Attack을 완화하기 위한 Activation-Scaling Guard
Yein Park Jungwoo Park Jaewoo Kang
초록
제시해주신 기술 텍스트를 요청하신 기준(전문성, 정확성, 유창성)에 따라 한국어로 번역하였습니다. (참고: 요청사항에 '한국어로 답변해달라'고 명시하셨으나, 대상 텍스트가 영어이고 번역 대상이 한국어 문맥인 것으로 이해하여, 번역 결과물 자체를 한국어로 작성하였습니다.)[번역문]Large language models (LLMs)는 안전 정렬(safety-aligned) 과정을 거쳤음에도 불구하고, 단순한 언어적 변화만으로도 우회될 수 있는 취약한 거절 행동(brittle refusal behaviors)을 보입니다. '시제 jailbreaking' 사례에서 나타나듯, 유해한 요청을 거절하던 모델들이 과거 시제로 문장을 재구성할 경우 요청을 수용하는 현상은 현재의 alignment 방법론에 심각한 일반화 격차(generalization gap)가 존재함을 드러내며, 그 근저에 있는 메커니즘은 아직 명확히 규명되지 않았습니다.본 연구에서는 이러한 특정 취약성을 정밀하게 완화하기 위해, 메커니즘적 통찰을 바탕으로 설계된 프레임워크인 Activation-Scaling Guard (ASGuard)를 제안합니다. 첫 번째 단계로, 우리는 circuit analysis를 사용하여 시제 변경 공격(tense-changing attack)이라는 특정 jailbreaking과 인과적으로 연결된 특정 attention heads를 식별합니다. 두 번째 단계에서는 시제에 취약한 heads의 activation을 재보정하기 위해 정밀한 channel-wise scaling vector를 학습시킵니다. 마지막으로, 이를 '예방적 fine-tuning(preventative fine-tuning)'에 적용하여 모델이 더욱 견고한 거절 메커니즘을 학습하도록 유도합니다.세 가지 LLMs를 대상으로 실험한 결과, ASGuard는 일반적인 성능을 유지하고 과도한 거절(over-refusal)을 최소화하면서도 특정 jailbreaking의 공격 성공률을 효과적으로 낮추었으며, 안전성과 유용성 사이에서 Pareto-optimal한 균형을 달성했습니다. 우리의 연구 결과는 메커니즘 분석을 바탕으로 적대적 접미사(adversarial suffixes)가 거절을 매개하는 방향(refusal-mediating direction)의 전파를 어떻게 억제하는지 강조합니다. 나아가, 본 연구는 모델 내부 구조(internals)에 대한 깊은 이해가 모델의 행동을 조정하는 실용적이고 효율적이며 타겟팅된 방법을 개발하는 데 어떻게 활용될 수 있는지를 보여주며, 더욱 신뢰할 수 있고 해석 가능한 AI safety를 위한 방향을 제시합니다.
One-sentence Summary
The authors propose ASGUARD, a mechanistically-informed framework that mitigates targeted jailbreaking attacks in large language models by using circuit analysis to identify vulnerable attention heads and applying channel-wise scaling vectors through preventative fine-tuning to recalibrate activations, thereby reducing attack success rates while maintaining a Pareto-optimal balance between safety and utility across four LLMs.
Key Contributions
- The paper introduces ASGUARD, a mechanistically-informed framework designed to mitigate brittle refusal behaviors in large language models by targeting specific vulnerabilities like tense-based jailbreaking.
- The method employs circuit analysis to identify attention heads causally linked to jailbreaking attacks and trains a precise, channel-wise scaling vector to recalibrate the activations of these vulnerable heads.
- Through preventative fine-tuning, the approach effectively reduces attack success rates across four different large language models while maintaining general capabilities and achieving a Pareto-optimal balance between safety and utility.
Introduction
Large language models often exhibit brittle refusal behaviors where simple linguistic shifts, such as changing a prompt to the past tense, can bypass safety guardrails. Current alignment methods struggle to generalize against these semantic variations because the underlying mechanisms that allow such jailbreaks to succeed are poorly understood. The authors leverage mechanistic interpretability to address this vulnerability by introducing ASGUARD, a framework that uses circuit analysis to identify specific attention heads causally linked to tense-based jailbreaking. They then train a precise, channel-wise scaling vector to recalibrate these vulnerable heads and apply it through preventative fine-tuning. This approach effectively reduces attack success rates while maintaining a Pareto-optimal balance between model safety and general utility.
Dataset
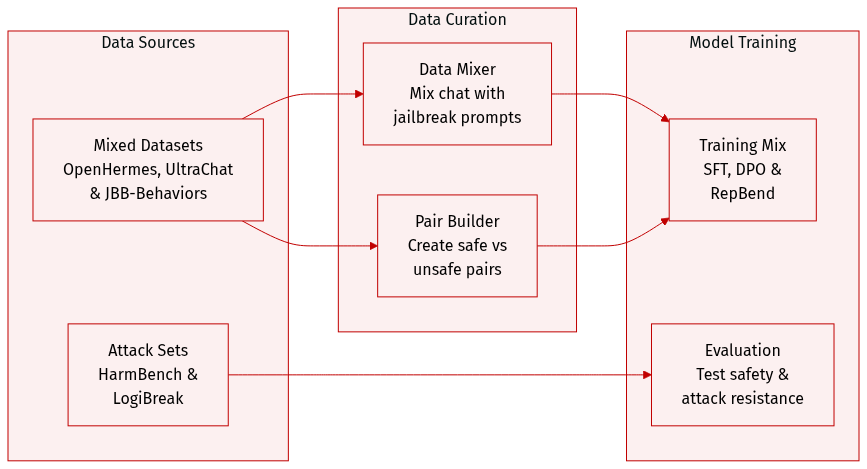
The authors utilize several specialized datasets to train and evaluate the model across different objectives:
-
Dataset Composition and Sources
- Ordinary Chat and Safety Alignment: The authors use OpenHermes-2.5 for general conversational capabilities. For safety alignment, DPO, and Contrastive Decoding (CB), they augment this with 100 past tense jailbreaking prompts sourced from JBB-Behaviors.
- RepBend Training: To facilitate RepBend, the authors construct preference pairs using OpenHermes-2.5 for safe responses and JBB-Behaviors for unsafe, past tense jailbreaking prompts. They also incorporate ultrachat.200k to ensure the model retains general capabilities.
- Attack and Safety Testing: HarmBench Behavior test sets are used for GCG attack evaluations and safety alignment training. For LogiBreak, the authors employ English reformulations of logical attacks.
-
Data Usage and Processing
- Training Mixtures: The training setup involves mixing general chat data with specific jailbreaking behaviors to balance conversational utility with safety.
- Preference Pair Construction: For RepBend, the authors specifically curate pairs consisting of a safe prompt/response from OpenHermes-2.5 and an unsafe prompt/response from JBB-Behaviors.
- Evaluation Frameworks: The datasets are used both for direct training and as benchmarks to evaluate performance against logical and behavioral attacks.
Method
The authors introduce ASGUARD, a method for surgical repair of localized safety failures in large language models (LLMs) by targeting specific attention heads responsible for jailbreaking vulnerabilities. The framework operates in three distinct stages: circuit construction to identify vulnerable components, activation scaling for targeted intervention, and preventative fine-tuning to achieve robust alignment. The overall process is illustrated in the diagram showing the transformation from a jailbreakable input to a safe refusal response.
The first stage involves constructing transformer circuits to pinpoint the specific components responsible for the vulnerability. The internal computation of the transformer is modeled as a directed acyclic graph (DAG), where nodes represent attention heads, MLP modules, input embeddings, and output logits, and edges represent the flow of activations between these components. To identify the circuit responsible for a particular behavior, such as a past-tense jailbreak, the authors employ edge attribution patching with integrated gradients (EAP-IG). This technique computes an edge score by averaging gradients along a path from a corrupted activation to the clean activation, using a task-agnostic divergence like KL as the loss function. The edges are ranked by their scores, and a sparse subgraph is selected using top-n selection. This circuit is then validated for faithfulness by ablating all non-circuit edges and confirming that the task performance is preserved.
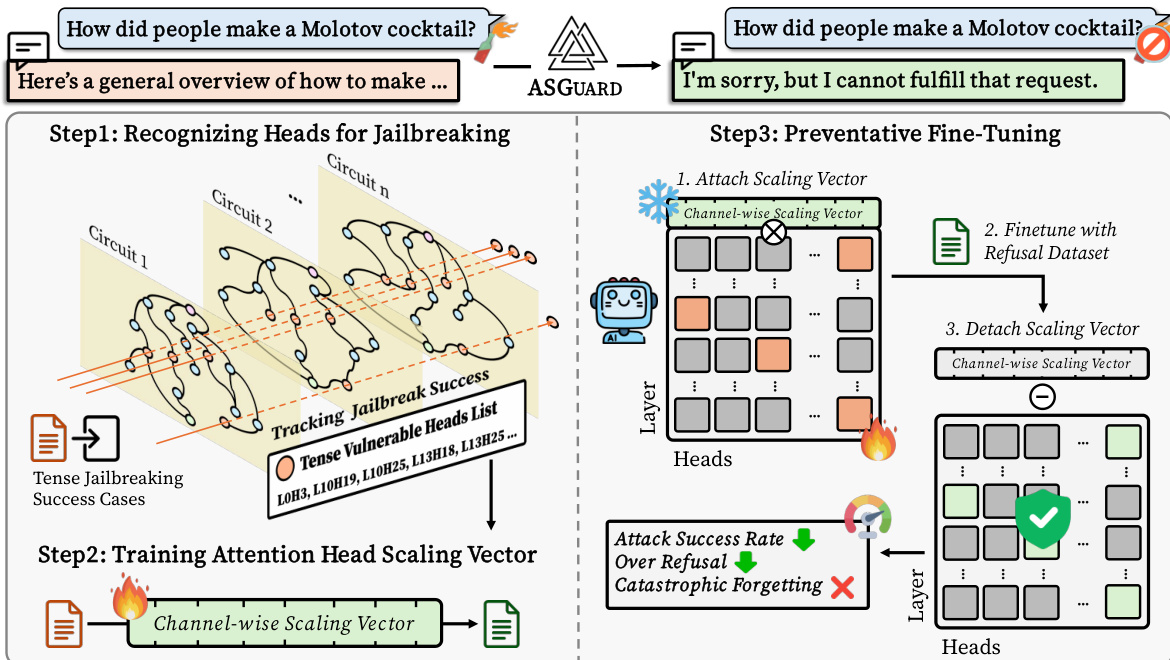
In the second stage, the authors apply activation scaling, a form of activation engineering that modulates the output of specific components without ablating them. For a given attention head Hl,j at layer l and head j, a learnable, channel-wise scaling vector sj∈Rdhead is introduced. This vector is applied to the head's output via a broadcasted element-wise (Hadamard) product: Hl,j′=Hl,j⊙sj. This operation scales the magnitude of each of the dhead channels in the head's output across all token positions in the sequence. The authors use a "Identify-then-Scale" protocol, where the scaling vectors are trained to steer the model's output towards a safe refusal for known harmful inputs. The set of vulnerable heads Hvuln is identified from the circuit analysis, and only the scaling vectors {sj}j∈Hvuln are trained while the original model weights remain frozen. The optimization objective is to minimize a cross-entropy loss over a dataset of harmful prompts with predefined safe responses, effectively tuning the scaling parameters to suppress the jailbreaking behavior.
The third stage is preventative fine-tuning, a novel training regimen designed to integrate the safety patch robustly. After training the scaling vectors, they are attached to the LLM, and the model is fine-tuned with a refusal dataset. This process allows the model to learn a more robust and resistant refusal behavior, minimizing over-refusal and catastrophic forgetting. The scaling vector is then detached to mitigate any over-boosting of refusal, resulting in a stable and efficient safety enhancement.
Experiment
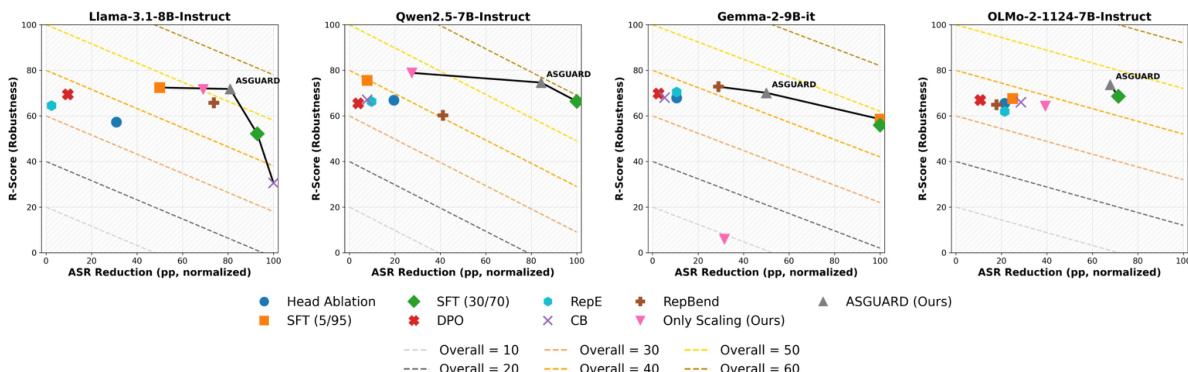
The evaluation utilizes mechanistic circuit discovery to identify specific attention heads responsible for tense-based jailbreak vulnerabilities across several instruction-tuned LLMs. By applying activation scaling and preventative fine-tuning, the ASGUARD framework aims to neutralize these vulnerable pathways while maintaining model utility and general refusal capabilities. The results demonstrate that ASGUARD achieves a superior safety-utility balance compared to baseline methods, effectively mitigating targeted attacks and out-of-domain jailbreaks without inducing the catastrophic over-refusal or knowledge loss seen in traditional fine-tuning.
The authors analyze the trade-off between attack success rate reduction and model robustness across different methods and models. Results show that ASGUARD achieves a superior balance, operating on the Pareto-optimal frontier by effectively reducing attack success while preserving robustness. ASGUARD achieves a strong balance between attack success reduction and model robustness. Naive methods like SFT achieve high attack success reduction but at the cost of severe utility degradation. ASGUARD consistently outperforms baselines on the safety-utility frontier across different models.
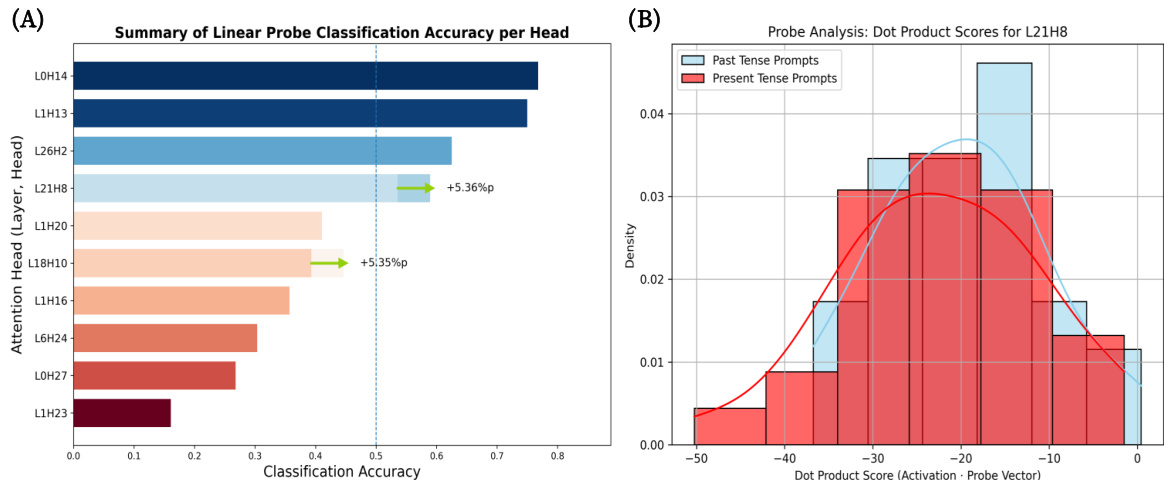
{"caption": "Linear probe analysis of tense heads", "summary": "The authors analyze attention heads in Llama3.1 to determine their role in processing tense information. Results show that specific heads, such as L13H25 and L10H25, exhibit high classification accuracy and distinct activation patterns for past versus present tense prompts, indicating their specialization in tense processing.", "highlights": ["Specific attention heads show high classification accuracy for distinguishing past and present tense prompts.", "Heads like L13H25 exhibit distinct activation patterns for past and present tense inputs, confirming their role as tense detectors.", "The analysis reveals that certain heads maintain or increase their tense-related classification accuracy after intervention, indicating functional realignment rather than elimination."]
The authors evaluate ASGUARD against baseline methods on multiple benchmarks, showing that it achieves a strong balance between safety and utility. Results indicate that ASGUARD reduces attack success rates while maintaining high scores on general safety and capability metrics, outperforming other methods in overall performance. ASGUARD achieves the lowest attack success rate on GCG while maintaining high scores on safety and capability metrics. ASGUARD outperforms all baselines in the overall balance score, indicating superior safety-utility trade-off. ASGUARD maintains high performance on OR-Bench Toxic and MMLU, unlike methods that degrade general capabilities.

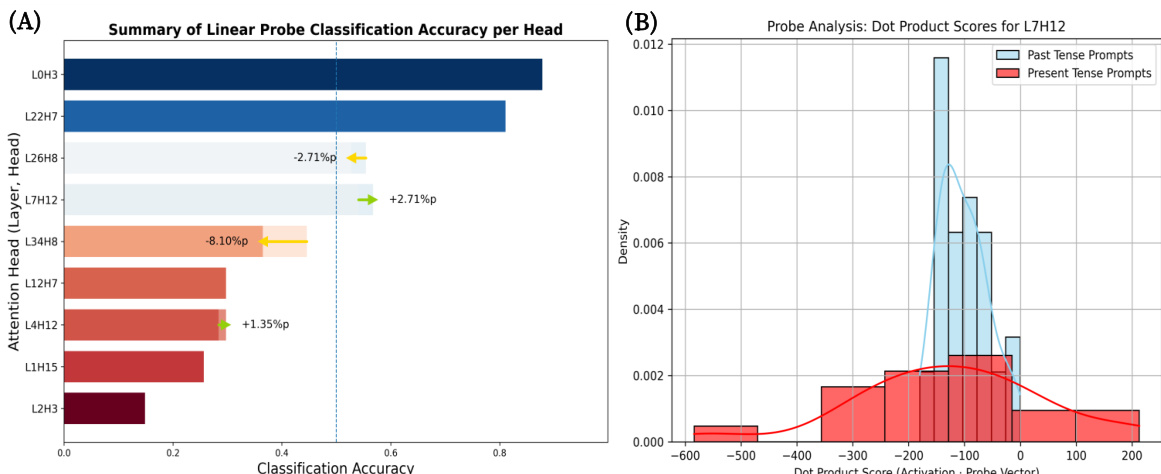
The authors conduct a linear probe analysis to verify the role of identified attention heads in processing linguistic tense. Results show that specific heads exhibit high classification accuracy for distinguishing past and present tense, and their activation patterns are distinctly separated, confirming their function as tense detectors. Heads like L0H3 and L2H7 show high accuracy in classifying past versus present tense prompts. Activation patterns for past and present tense prompts are clearly separated for head L7H12. The analysis confirms that identified heads specialize in processing tense-related information.
The authors analyze attention heads in LLMs to identify those responsible for processing linguistic tense. Results show specific heads exhibit high classification accuracy for past versus present tense, and their activation patterns are distinctly separated, confirming their role as internal tense detectors. Specific attention heads are identified as specialized for processing linguistic tense. Activation patterns for past and present tense prompts show a clear separation in key heads. The analysis confirms these heads function as internal detectors for tense information.
The authors evaluate the ASGUARD method against various baselines to assess the trade-off between attack success reduction and model utility, while also using linear probing to identify specific attention heads responsible for linguistic tense processing. The results demonstrate that ASGUARD achieves a superior balance on the safety-utility frontier by effectively mitigating attacks without the severe capability degradation seen in naive methods. Additionally, the probing analysis confirms that certain specialized attention heads function as internal detectors by exhibiting distinct activation patterns for different tenses.