Command Palette
Search for a command to run...
VoxCPM: 문맥 인식 음성 생성 및 실감 나는 음성 클로닝을 위한 Tokenizer-Free TTS
VoxCPM: 문맥 인식 음성 생성 및 실감 나는 음성 클로닝을 위한 Tokenizer-Free TTS
VoxCPM Team
초록
음성 합성(speech synthesis)을 위한 생성 모델은 근본적인 트레이드오프(trade-off)에 직면해 있습니다. 즉, 이산적 token은 안정성을 보장하지만 표현력(expressivity)을 희생하며, 연속적 신호는 음향적 풍부함은 유지하지만 작업 간 얽힘(task entanglement)으로 인한 오류 누적 문제를 겪습니다. 이러한 과제는 사전 학습된 음성 tokenizer에 의존하는 다단계 pipeline 방식으로 연구 흐름을 이끌었으나, 이는 의미론적 요소와 음향적 요소 사이의 괴리(semantic-acoustic divide)를 발생시켜 통합적이고 표현력 있는 음성 생성을 제한하는 결과를 초래했습니다.본 논문에서는 semi-discrete residual representation을 활용한 계층적 의미-음향 모델링(hierarchical semantic-acoustic modeling)을 통해 이러한 딜레마를 해결하고, 새로운 tokenizer-free TTS 모델인 VoxCPM을 제안합니다. 당사의 프레임워크는 자연스러운 전문화를 유도하는 미분 가능한 양자화 병목(differentiable quantization bottleneck)을 도입합니다. 구체적으로, Text-Semantic Language Model(TSLM)은 의미론적-운율적 계획(semantic-prosodic plans)을 생성하고, Residual Acoustic Model(RALM)은 세밀한 음향적 디테일을 복원합니다. 이러한 계층적 의미-음향 표현은 local diffusion-based decoder를 가이드하여 고충실도(high-fidelity) 음성 latent를 생성합니다. 결정적으로, 전체 아키텍처는 단순한 diffusion objective 하에 end-to-end로 학습되어 외부 음성 tokenizer에 대한 의존성을 제거했습니다.180만 시간에 달하는 방대한 이중 언어 코퍼스로 학습된 VoxCPM-0.5B 모델은 오픈 소스 시스템 중 최첨단(state-of-the-art) zero-shot TTS 성능을 달성하였으며, 본 접근 방식이 표현력 있고 안정적인 합성을 제공함을 입증했습니다. 또한, VoxCPM은 텍스트를 이해하여 적절한 운율과 스타일을 추론 및 생성하는 능력을 보여주며, 문맥을 인지하는 표현력과 자연스러운 흐름을 갖춘 음성을 전달합니다. 커뮤니티 중심의 연구 및 개발을 촉진하기 위해 VoxCPM은 Apache 2.0 라이선스 하에 공개되었습니다.
One-sentence Summary
The VoxCPM Team proposes VoxCPM, a tokenizer-free text-to-speech framework that utilizes hierarchical semantic-acoustic modeling with semi-discrete residual representations and a differentiable quantization bottleneck to achieve state-of-the-art zero-shot performance in context-aware speech generation and voice cloning through end-to-end diffusion training.
Key Contributions
- The paper introduces VoxCPM, a novel tokenizer-free text-to-speech model that utilizes a unified end-to-end framework to resolve the trade-off between speech expressivity and stability.
- This work presents a hierarchical semantic-acoustic modeling approach featuring a differentiable quantization bottleneck that separates information into a discrete-like skeleton for content stability and continuous residual components for acoustic detail.
- Experiments conducted on a 1.8 million hour bilingual corpus demonstrate that the model achieves state-of-the-art zero-shot TTS performance among open-source systems in terms of intelligibility and speaker similarity.
Introduction
Modern text-to-speech (TTS) systems strive to balance acoustic richness with linguistic stability, a task critical for developing empathetic virtual assistants and immersive digital avatars. Current discrete token-based methods ensure stability but suffer from a quantization ceiling that discards fine-grained acoustic details, while continuous representation models preserve fidelity but often struggle with error accumulation and task entanglement. The authors leverage a hierarchical semantic-acoustic modeling framework to resolve this trade-off through a tokenizer-free, end-to-end architecture. By introducing a differentiable quantization bottleneck, VoxCPM induces a natural specialization where a Text-Semantic Language Model handles prosodic planning and a Residual Acoustic Model recovers fine-grained details.
Method
The authors propose VoxCPM, a hierarchical autoregressive architecture designed to generate sequences of continuous speech latents Z={z1,...,zM} conditioned on input text tokens T={t1,...,tN}. In this framework, each zi∈RP×D represents a patch of P frames containing D-dimensional VAE latent vectors. The generation process is formulated as:
\np(Z∣T)=∏i=1Mp(zi∣T,Z<i)
The core of the system is a hierarchical conditioning mechanism that separates semantic-prosodic planning from fine-grained acoustic synthesis. Refer to the framework diagram:
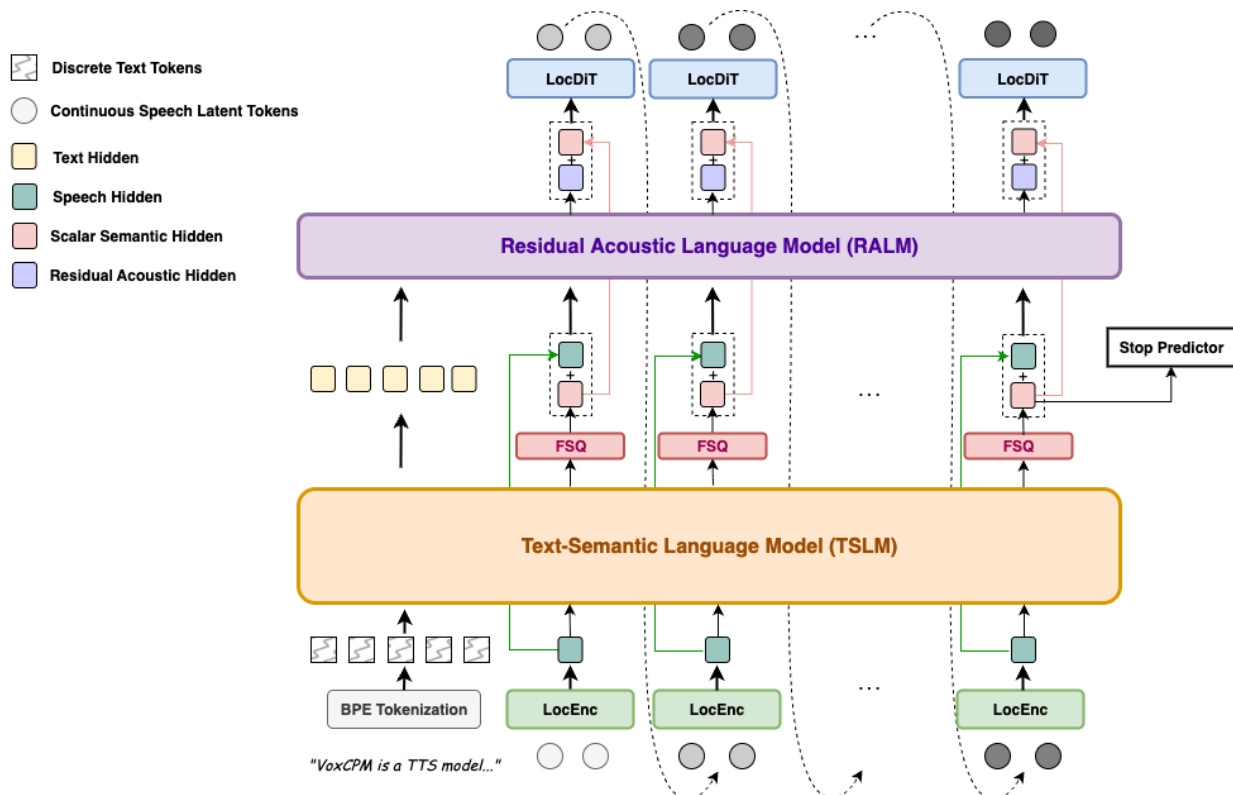
The architecture consists of four primary modules: a local audio encoder (LocEnc), a text-semantic language model (TSLM), a residual acoustic language model (RALM), and a local diffusion transformer decoder (LocDiT).
The process begins with the LocEnc, which compresses historical VAE latent patches into compact acoustic embeddings E<i=LocEnc(Z<i). These embeddings, along with the text tokens, are processed by the TSLM. The TSLM utilizes a pre-trained text language model as its backbone to capture high-level linguistic structures and prosodic patterns. To ensure a stable generation process, the TSLM's continuous hidden states are projected onto a structured lattice via a Finite Scalar Quantization (FSQ) layer. This FSQ operation produces a semi-discrete representation, defined as:
hi,jFSQ=Δ⋅clip(round(ΔhTSLM),−L,L)
where Δ is the quantization step size and L is the clipping range. This FSQ layer acts as a bottleneck that captures a coarse semantic-prosodic skeleton.
To recover the acoustic details lost during quantization, the RALM is employed. It reconstructs subtle vocal characteristics by conditioning on the TSLM hidden states, the semi-discrete FSQ representations, and the historical acoustic embeddings:
hiresidual=RALM(HtextTSLM,H<iFSQ⊕E<i)
The final conditioning signal hifinal is the sum of the stable semantic skeleton and the residual acoustic details:
zi∼LocDiT(hifinal),hifinal=stable skeletonFSQ(TSLM(T,E<i))+residual detailsRALM(⋅)
This signal guides the LocDiT, a bidirectional Transformer that performs a denoising diffusion process to generate the current latent patch zi. To improve consistency, the previous patch zi−1 is included as additional context.
The model is trained end-to-end using a conditional flow-matching objective to optimize the quality of the speech latents:
LFM=Et,zi0,ϵ[∣vθ(zit,t,hifinal,zi−1)−dtd(αtzi0+σtϵ)∣2]
Additionally, a stop predictor is trained using a binary cross-entropy loss to determine the endpoint of the speech sequence. This unified training approach ensures that the TSLM, FSQ, RALM, and LocDiT are all optimized toward coherent and high-fidelity speech synthesis.
Experiment
The experiments evaluate VoxCPM through comprehensive objective and subjective benchmarks, including SEED-TTS-EVAL and CV3-EVAL, to validate its performance against state-of-the-art open-source TTS systems. Results demonstrate that the hierarchical architecture effectively disentangles semantic planning from acoustic rendering, achieving superior intelligibility and speaker similarity through its semi-discrete bottleneck and residual acoustic modeling. Ablation studies and visual analyses further confirm that the model's design promotes stable learning, efficient data utilization, and context-aware prosody generation.
The authors conduct a subjective evaluation comparing VoxCPM and its variants against several state-of-the-art models. Results show that VoxCPM achieves high scores in both naturalness and speaker similarity across Chinese and English languages. VoxCPM achieves superior speaker similarity in both Chinese and English compared to the evaluated baselines In Chinese evaluations, VoxCPM shows high naturalness scores, though it trails IndexTTS 2 in this specific metric The VoxCPM-Emilia variant maintains competitive performance levels despite being trained on a smaller dataset
The authors compare different training phases and model variants using a two-phase Warmup-Stable-Decay learning rate schedule. The training configurations vary by model type, total iterations, and hardware resources used. The VoxCPM model undergoes a longer training process compared to the Emilia variant and the ablation model. The decay phase utilizes a larger batch size in terms of tokens compared to the stable phase. Training for the VoxCPM model requires more GPU resources than the other configurations shown.

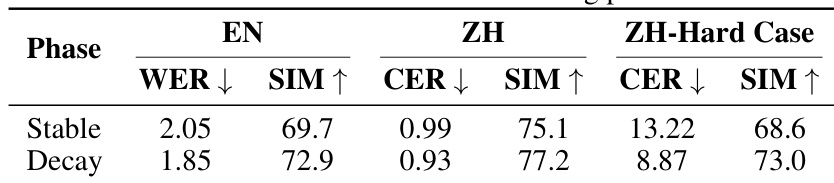
The authors evaluate the impact of a two-phase Warmup-Stable-Decay learning rate schedule on model performance. Results show that transitioning from the stable phase to the decay phase leads to consistent improvements across all measured metrics for both English and Chinese. The decay phase reduces error rates in both English and Chinese compared to the stable phase Speaker similarity scores improve across all tested languages during the decay phase The model demonstrates enhanced robustness on challenging Chinese cases following the decay phase
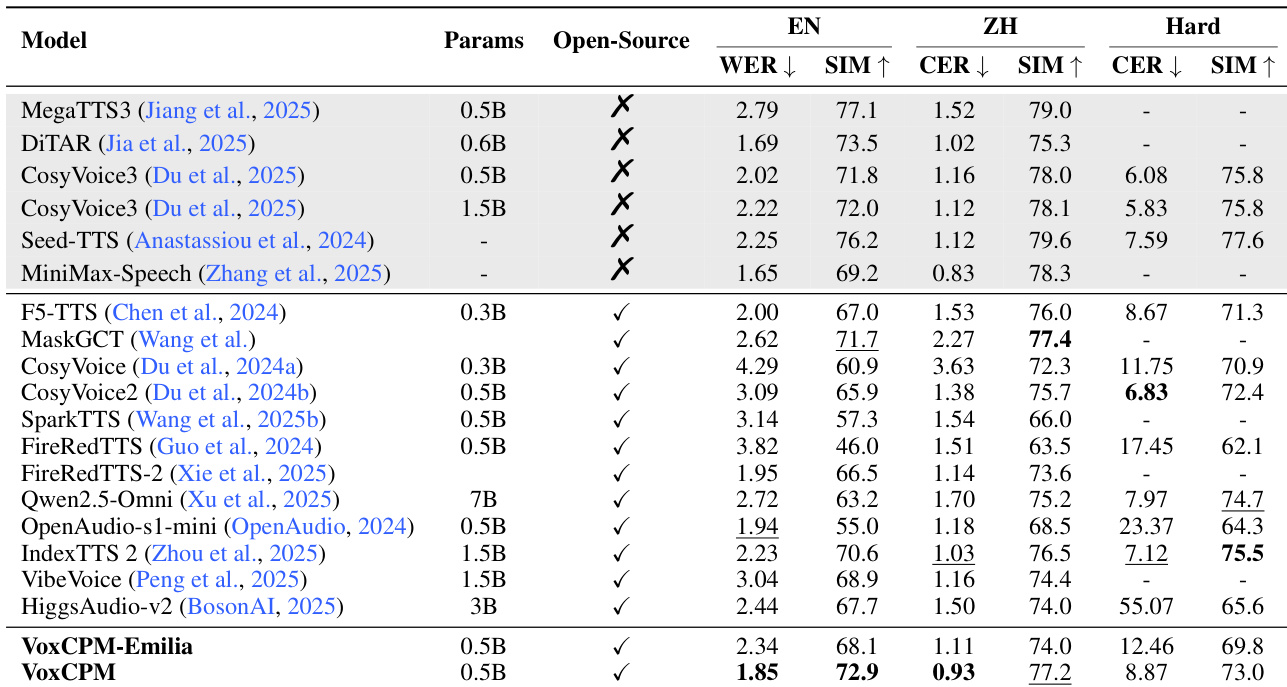
The authors compare VoxCPM and its Emilia variant against several state-of-the-art open-source and closed-source TTS models using English and Chinese benchmarks. Results show that VoxCPM achieves competitive performance in both intelligibility and speaker similarity across standard and challenging test sets. VoxCPM demonstrates superior English intelligibility and speaker similarity compared to most listed open-source models. On the challenging Hard test set, VoxCPM maintains high performance in both Chinese character error rates and speaker similarity. The VoxCPM-Emilia variant shows competitive results despite being trained on a smaller dataset, indicating architectural robustness.
The authors evaluate VoxCPM against several state-of-the-art TTS models using the CV3-EVAL benchmark, which focuses on expressive and in-the-wild performance. Results demonstrate that VoxCPM achieves superior performance in terms of intelligibility on both Chinese and English benchmarks compared to most baseline models. VoxCPM achieves the lowest error rates for both Chinese and English on the standard CV3-EVAL benchmark. On the more challenging CV3-Hard-EN subset, VoxCPM outperforms several competitive models in word error rate. While VoxCPM shows strong intelligibility, other models such as CosyVoice3 variants exhibit higher speaker similarity scores.
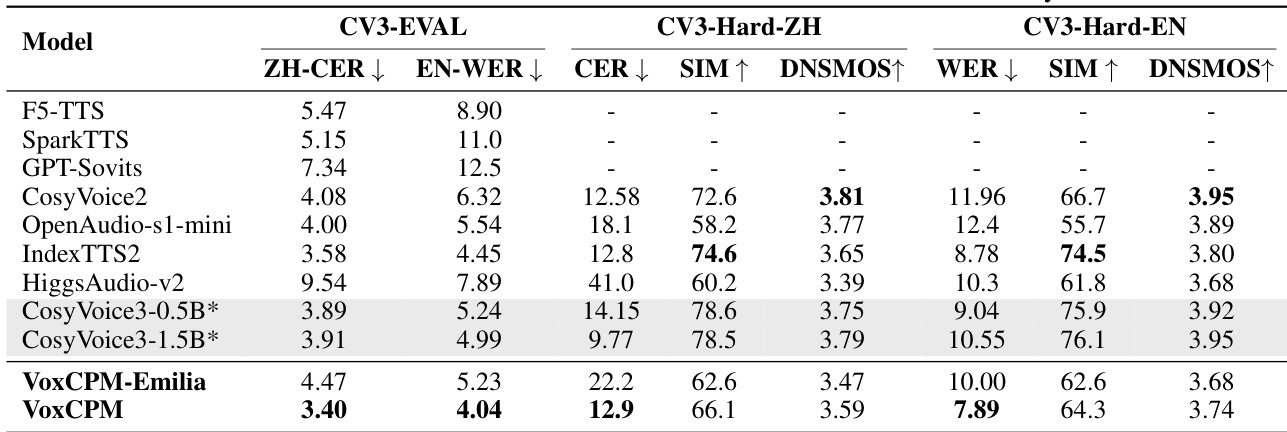
The authors conduct subjective and objective evaluations to compare VoxCPM and its variants against various state-of-the-art models across English and Chinese benchmarks. The experiments validate that VoxCPM achieves superior speaker similarity and high intelligibility, even when tested on challenging datasets or using the more efficient Emilia variant. Additionally, the results demonstrate that implementing a two-phase learning rate decay schedule significantly enhances model robustness and performance across all tested languages.