Command Palette
Search for a command to run...
연속적 오디오 언어 모델 (Continuous Audio Language Models)
연속적 오디오 언어 모델 (Continuous Audio Language Models)
Simon Rouard Manu Orsini Axel Roebel Neil Zeghidour Alexandre Défossez
Pocket-TTS: 고품질의 경량 스트리밍 TTS 시스템
초록
Audio Language Models (ALM)은 오디오를 이산적인(discrete) token의 시퀀스로 표현함으로써 음성 및 음악 생성 분야의 지배적인 패러다임으로 부상했습니다. 그러나 가역적인(invertible) 텍스트 token과 달리, 오디오 token은 제한된 비트레이트를 가진 손실 압축 코덱(lossy codecs)으로부터 추출됩니다. 그 결과, 오디오 품질을 높이기 위해서는 더 많은 token을 생성해야 하며, 이는 충실도(fidelity)와 연산 비용(computational cost) 사이의 트레이드오프(trade-off)를 발생시킵니다.본 논문에서는 Continuous Audio Language Models (CALM)를 연구함으로써 이 문제를 해결합니다. CALM은 매 타임스텝(timestep)마다 문맥 임베딩(contextual embedding)을 생성하는 대규모 Transformer backbone을 구현합니다. 이렇게 생성된 시퀀스 정보는 consistency modeling을 통해 오디오 VAE의 다음 연속 프레임(continuous frame)을 생성하는 MLP의 조건(condition)으로 작용합니다. CALM은 손실 압축을 피함으로써 기존의 이산형(discrete) 모델보다 낮은 연산 비용으로 더 높은 품질을 달성합니다. 음성 및 음악에 대한 실험 결과, CALM은 최첨단(state-of-the-art) 이산형 audio language model 대비 향상된 효율성과 충실도를 입증하였으며, 이를 통해 경량화된 고품질 오디오 생성을 가능하게 합니다.
One-sentence Summary
By employing a Transformer backbone and consistency modeling to generate continuous VAE frames directly, CALM avoids the fidelity-versus-cost trade-off inherent in lossy discrete tokenization to achieve superior efficiency and quality in speech and music generation.
Key Contributions
- The paper introduces Continuous Audio Language Models (CALM), a framework for autoregressive audio generation that operates directly in the continuous latent space of a VAE to bypass the limitations of discrete quantization.
- This work implements a dual-transformer architecture that combines noise-injected long-term context with clean short-term context and utilizes consistency modeling to replace traditional diffusion heads for more efficient inference.
- Experiments on speech and music generation tasks demonstrate that the method achieves higher fidelity and improved efficiency compared to state-of-the-art discrete models, notably reaching comparable quality with only one step of consistency modeling.
Introduction
Current audio language models primarily rely on discretizing audio into sequences of tokens using lossy neural codecs. While effective, this approach creates a strict trade-off where higher fidelity requires increasing the bitrate, which significantly raises the computational cost due to the growing number of tokens. Previous attempts to use continuous latent modeling have often struggled with slow sampling speeds or difficulty maintaining high quality across complex, long-form audio tasks like music generation.
The authors leverage a Continuous Audio Language Model (CALM) framework that predicts sequences directly within the continuous latent space of a VAE, bypassing the need for quantization. They replace traditional diffusion heads with continuous consistency models to drastically accelerate inference and introduce a dual-transformer design that uses both noised long-term context and clean short-term context to prevent error accumulation. These innovations allow the model to achieve high-fidelity speech and music generation with significantly lower computational overhead than discrete alternatives.
Dataset

The authors utilize a large scale dataset totaling 88,000 hours of audio to train their text to speech models.
- Dataset Composition and Sources: The training data is aggregated from multiple diverse sources, including AMI, Carletta (2007), EARNINGS22, GIGASpeech, SPGISpeech, TED-LIUM, VoxPopuli, LibriHeavy, and Emilia.
- Data Processing and Evaluation: To ensure high quality, the authors employ human assessment frameworks for both speech and music.
- Acoustic Quality: Audio clips are rated on a scale from bad to excellent, focusing on clarity, balance, richness, and naturalness.
- Meaningfulness and Enjoyment: The researchers use a comparative approach where listeners evaluate pairs of clips. For speech, clips are judged on meaningfulness and naturalness, while music clips are judged on enjoyment.
- Scoring: These comparative evaluations are converted into Elo scores using Bayesian estimates of the posterior mean within a Bradley-Terry model.
Method
The authors propose the Continuous Audio Language Model (CALM) architecture, which moves away from traditional discrete token modeling in favor of autoregressive modeling over continuous latent vectors. The process begins with a VAE-GAN framework where a fully causal VAE encoder transforms the audio into a sequence of continuous latent vectors (x1,…,xS). Unlike RVQ-based models that rely on codebooks, this approach utilizes a VAE bottleneck to enforce a Gaussian prior and regularize the latent space.
The core architecture of CALM consists of three integrated components designed to ensure both long-term coherence and local high-resolution detail. As shown in the framework diagram:
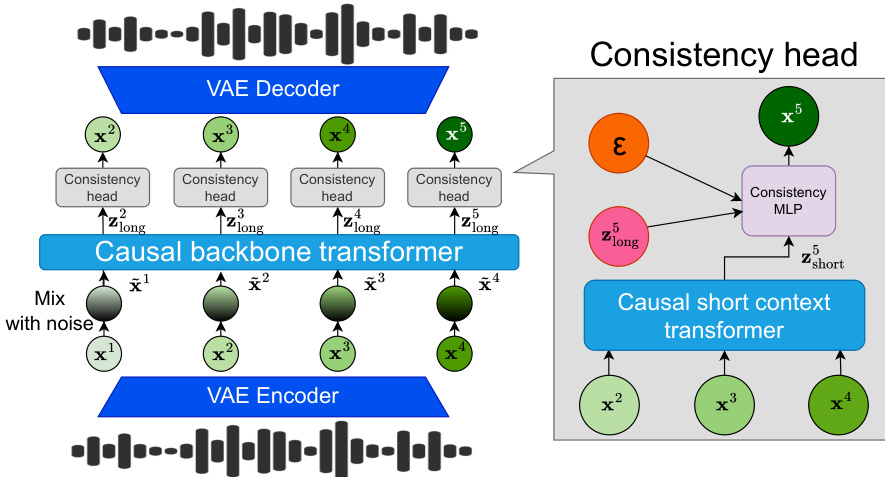
First, the model employs a Causal Backbone Transformer Tlong,θ1 to capture long-term dependencies. To improve robustness against error accumulation during inference, the authors implement a noise injection mechanism during training. Instead of using clean latents, the backbone receives noised inputs x~s=ksϵs+1−ksxs, where ks∼U(0,1) and ϵs∼N(0,I). This allows the backbone to produce a context vector zlongs that is resilient to the deviations encountered during autoregressive generation.
Second, to prevent the loss of fine-grained information caused by the backbone's noise injection, a lightweight Short-Context Transformer Tshort,θ2 is introduced. This module attends to a local window of the K previous clean latents, producing a short-context embedding zshorts=Tshort,θ2(xs−K,…,xs−1).
Third, these two representations are fused into a combined feature Zs=zlongs+zshorts, which conditions a small MLP-based Consistency Model head fϕ. This head is designed for rapid, high-fidelity sampling. The training objective for the entire system is a continuous-time consistency loss:
LCALM(θ,ϕ,ψ)=s=1∑SmathbbEt,epsilonleft[fracewpsi(t)Dleft∣Fphileft(mathbfxts,t,mathbfZsright)−Fbarphileft(mathbfxts,t,mathbfZsright)−cos(t)fracdfbarphi(mathbfxts,t,mathbfZs)dtright∣22−wpsi(t)right]where xts=cos(t)xs+sin(t)ϵ. By jointly training the backbone, the short-context transformer, and the consistency head, the model achieves efficient 1-step generation at inference time by mapping a noisy input directly to the clean latent xs.
Experiment
The experiments evaluate the CALM framework across speech continuation, text-to-speech, and music generation tasks to validate its efficiency and audio quality. Results demonstrate that the consistency-based sampling head significantly outperforms traditional discrete models by providing faster inference speeds and superior semantic meaningfulness without sacrificing acoustic quality. Additionally, the findings show that combining noisy long-term context with clean short-term context is essential for maintaining detail in music generation, while the framework also demonstrates strong scalability and competitive performance in text-to-music benchmarks.
The authors compare several music generation models based on speed and quality metrics for 30 second generation tasks. Results show that consistency-based models offer significant speed improvements over the baseline while maintaining or improving audio quality and enjoyment levels. Consistency models achieve substantial overall and sampler head speedups compared to the baseline The TrigFlow approach produces high quality results but requires significantly more inference time Consistency-based methods demonstrate improved FAD scores and competitive human ratings

The authors compare different music compression models based on reconstruction metrics including ViSQOL and SISNR. Results show that while a smaller VAE matches the performance of a high-level RVQ codec, increasing the latent dimensions significantly improves reconstruction quality. A VAE with higher dimensions outperforms the standard RVQ codec in both ViSQOL and SISNR metrics The 32-dimensional VAE achieves reconstruction quality comparable to the 4-level RVQ EnCodec model Increasing the VAE bottleneck from 96 to 128 dimensions leads to superior acoustic reconstruction performance

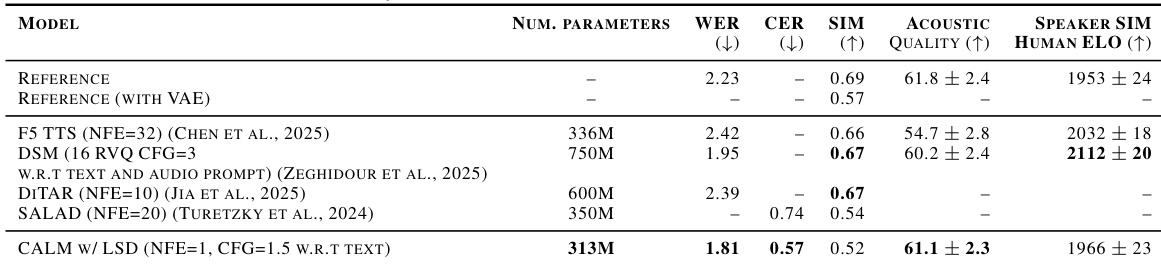
The authors evaluate their CALM model with Lagrangian Self-Distillation (LSD) for text-to-speech tasks on the Librispeech test-clean set. The results demonstrate that the proposed model achieves superior performance in speech recognition accuracy and character error rates compared to several established baselines. The CALM model with LSD achieves the lowest word error rate and character error rate among the compared models The model maintains competitive acoustic quality compared to existing large-scale baselines The proposed method performs well on speech recognition metrics despite having fewer parameters than several competitors
The authors evaluate the CALM model on the MusicCaps dataset for text-to-music generation, comparing it against several established baselines. The results demonstrate that the CALM model with consistency sampling achieves competitive performance across multiple metrics. The CALM model achieves a lower FAD score compared to several baseline models including MusicLM and MusicGen Medium. The model shows competitive performance in terms of CLAP similarity and KL Divergence relative to other generative approaches. Results indicate that applying CALM with CLAP conditioning leads to competitive text-to-music generation capabilities.

The authors conduct an ablation study on the music CALM Consistency 4-step model to evaluate the necessity of its various components. The results demonstrate that the base model achieves the best performance, while removing key elements leads to significant performance degradation. The base model achieves the lowest FAD score among all tested variants Removing the short-context transformer or noise augmentation results in higher FAD scores The absence of all studied components leads to the poorest model performance

The authors evaluate various music generation and compression models alongside the CALM framework to assess speed, audio quality, and reconstruction accuracy. The results demonstrate that consistency-based models significantly improve generation speed without sacrificing enjoyment, while increasing latent dimensions in VAEs enhances acoustic reconstruction. Furthermore, the CALM model shows superior performance in text-to-speech and text-to-music tasks, with ablation studies confirming that its core components are essential for maintaining high generative quality.