Command Palette
Search for a command to run...
PanoWan: 위도/경도 인지 메커니즘을 통한 Diffusion Video Generation Model의 360° 확장
PanoWan: 위도/경도 인지 메커니즘을 통한 Diffusion Video Generation Model의 360° 확장
Yifei Xia Shuchen Weng Siqi Yang Jingqi Liu Chengxuan Zhu Minggui Teng Zijian Jia Han Jiang Boxin Shi
초록
파노라마 비디오 생성(Panoramic video generation)은 몰입형 360° 콘텐츠 제작을 가능하게 하며, 장면 일관성이 유지되는 세계 탐색이 요구되는 응용 분야에서 매우 가치 있는 기술입니다. 그러나 기존의 파노라마 비디오 생성 모델들은 데이터셋 규모의 한계와 공간적 특징 표현(spatial feature representations)의 차이로 인해, 고품질의 다양한 파노라마 비디오를 생성하는 데 있어 기존 text-to-video 모델의 사전 학습된 생성적 사전 지식(generative priors)을 활용하는 데 어려움을 겪고 있습니다.본 논문에서는 최소한의 모듈만을 사용하여 사전 학습된 text-to-video 모델을 파노라마 도메인으로 효과적으로 확장(lift)하는 PanoWan을 소개합니다. PanoWan은 위도 왜곡을 방지하기 위해 위도 인식 샘플링(latitude-aware sampling)을 채택하였으며, 회전된 시맨틱 디노이징(rotated semantic denoising)과 패딩된 픽셀 단위 디코딩(padded pixel-wise decoding)을 통해 경도 경계에서의 매끄러운 전환을 보장합니다. 이러한 확장된 표현을 학습하기 위한 충분한 파노라마 비디오를 제공하고자, 본 연구에서는 캡션과 다양한 시나리오를 포함한 고품질 파노라마 비디오 데이터셋인 PANOVID를 제안합니다. 결과적으로, PanoWan은 파노라마 비디오 생성 분야에서 최첨단(state-of-the-art) 성능을 달성하였으며, zero-shot 다운스트림 작업에 대한 견고성(robustness)을 입증하였습니다.
One-sentence Summary
To lift pre-trained text-to-video models to the 360° panoramic domain, the authors propose PanoWan, a framework that utilizes latitude-aware sampling, rotated semantic denoising, and padded pixel-wise decoding to prevent spatial distortion and boundary discontinuities, achieving state-of-the-art performance through training on the newly introduced PANOVID dataset.
Key Contributions
- The paper introduces PanoWan, a framework that lifts generative priors from pre-trained text-to-video models to the panoramic domain using minimal architectural modifications.
- This method utilizes latitude-aware sampling to prevent latitudinal distortion and combines rotated semantic denoising with padded pixel-wise decoding to ensure seamless transitions at longitude boundaries.
- The researchers contribute PANOVID, a high-quality panoramic video dataset featuring diverse scenarios and annotated text descriptions, which enables the model to achieve state-of-the-art performance and strong zero-shot generalization.
Introduction
Panoramic video generation is essential for creating immersive 360 degree content for virtual reality, interactive gaming, and embodied AI simulations. While conventional text-to-video models possess strong generative priors, existing methods struggle to adapt these models to the panoramic domain due to limited dataset scales and spatial representation gaps, such as latitudinal distortions and visible seams at longitude boundaries. The authors leverage these pre-trained priors by introducing PanoWan, a framework that utilizes latitude-aware sampling, rotated semantic denoising, and padded pixel-wise decoding to ensure spatial consistency and seamless transitions. To support this approach, they also contribute PANOVID, a high-quality dataset containing over 13,000 captioned panoramic video clips.
Dataset

PANOVID Dataset Overview
The authors introduce PANOVID, a large-scale dataset designed to overcome the scarcity of paired data for text-based panoramic video generation.
- Dataset Composition and Sources: The dataset is aggregated from multiple panoramic video sources, including 360-1M, 360+x, Imagine360, WEB360, Panonut360, the Miraikan 360-degree Video Dataset, and a public collection of immersive VR videos.
- Key Details and Scale: The final collection consists of over 13,000 high-quality video clips, totaling approximately 944 hours of footage.
- Metadata Construction and Processing:
- Captioning and Labeling: The authors utilize Qwen-2.5-VL to generate descriptive text captions and predict Point-of-Interest (POI) categories for every video.
- Redundancy Removal: To ensure semantic diversity, the pipeline removes redundant samples based on caption similarity.
- Quality Filtering: Within each POI category, videos undergo a rigorous filtering process based on optical flow smoothness and aesthetic scores, retaining only the highest-ranked samples to ensure semantic balance and visual quality.
Method
The authors propose PanoWan, a framework designed to adapt conventional video diffusion models for panoramic video generation by addressing the unique spatial characteristics of equirectangular projection (ERP). The core approach leverages a pre-trained video diffusion backbone, specifically Wan 2.1, and utilizes Low-Rank Adaptation (LoRA) to fine-tune a minimal subset of parameters. This strategy allows the model to preserve the strong generative priors of the original model while learning the spherical coordinate mapping required for 360-degree views.
The overall architecture is designed to mitigate the distortions inherent in mapping spherical signals to Cartesian coordinates. Refer to the framework diagram:
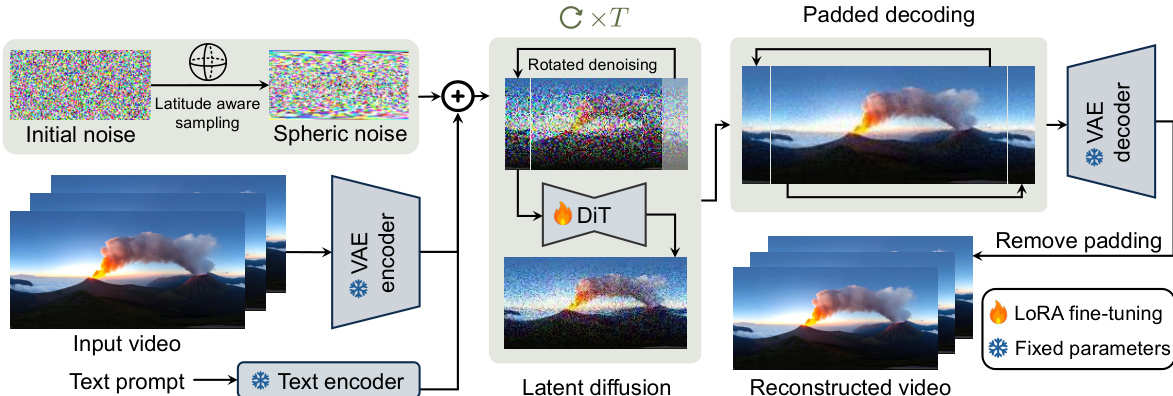
The process begins with the video diffusion backbone, which employs spatial-temporal Variational AutoEncoders (VAEs) to map high-dimensional videos into compact latent codes. To address the extreme horizontal stretching in polar regions caused by ERP, the authors introduce a latitude-aware sampling mechanism. Instead of using standard independent and identically distributed (i.i.d.) Gaussian noise, the model remaps the horizontal sampling coordinates based on the latitude. This ensures that the initial noise aligns with the spherical frequency distribution, effectively preserving frequency consistency across the sphere.
Once the spherical noise is prepared, it serves as the latent code within the VAE-encoded latent space. During the iterative denoising process, the model employs a Diffusion Transformer (DiT) backbone. To prevent seam artifacts at the longitudinal boundaries (the meeting point of the easternmost and westernmost longitudes), the authors implement rotated semantic denoising. This module works by horizontally rolling the latent code by a specific number of columns at each denoising step. By shifting the latent grid, the transition errors are spread evenly across all longitudes rather than concentrating at a single seam, significantly suppressing visual artifacts.
Finally, to ensure seamless pixel-level transitions, the framework utilizes padded pixel-wise decoding. Rather than decoding the denoised latent code directly, the authors apply a circular padding operator to extend the latent code with additional context from the opposite side of the sphere. The VAE decoder then processes this extended representation, and the result is center-cropped to return the final panoramic video. This ensures that pixels near the original seam boundaries are decoded with sufficient horizontal context, resulting in a seamless and continuous visual output.
Experiment
The evaluation utilizes a combination of adapted general video metrics, user preference studies, and a specialized quantitative metric to assess spherical consistency and longitude boundary continuity. Comparative experiments demonstrate that PanoWan outperforms existing methods by maintaining superior global consistency and avoiding the polar distortions or complex scene failures seen in prior models. Ablation studies further validate that the proposed latitude-aware and longitude-aware modules are essential for ensuring correct geometric rendering and seamless transitions across the panoramic seam.
The authors conduct an ablation study to evaluate the impact of latitude-aware sampling, rotated semantic denoising, and padded pixel-wise decoding on panoramic video generation. The results demonstrate that the full model outperforms versions with individual modules removed across both general and panoramic quality metrics. The complete model achieves the highest performance in general video quality, text-video alignment, and image quality. Removing latitude-aware sampling primarily degrades general metrics, while omitting denoising or decoding modules negatively impacts panoramic continuity. The full implementation provides superior motion patterns and scene richness compared to baseline methods and ablated versions.
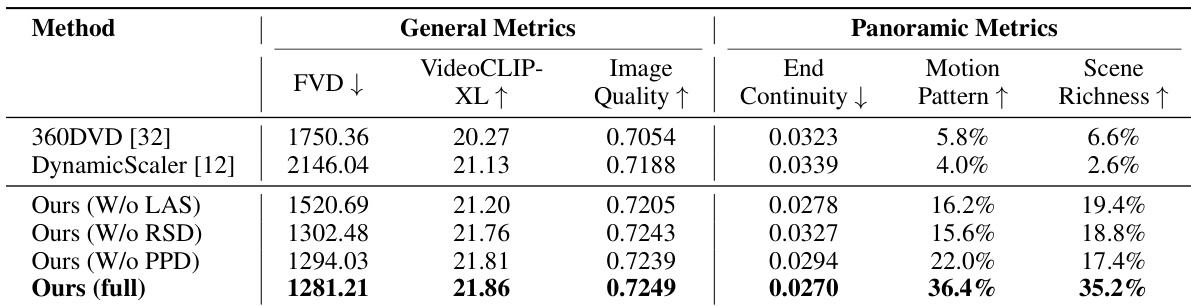
The authors conduct an ablation study to evaluate the individual contributions of latitude-aware sampling, rotated semantic denoising, and padded pixel-wise decoding to panoramic video generation. The results show that the full model provides superior motion patterns, scene richness, and text-video alignment compared to baseline and ablated versions. While removing sampling components degrades general video quality, omitting the denoising or decoding modules specifically compromises panoramic continuity.