Command Palette
Search for a command to run...
안전 사전 훈련: 차세대 안전 인공지능으로 나아가기
안전 사전 훈련: 차세대 안전 인공지능으로 나아가기
Pratyush Maini Sachin Goyal Dylan Sam Alex Robey Yash Savani Yiding Jiang Andy Zou Matt Fredrikson Zachary C. Lipton J. Zico Kolter
초록
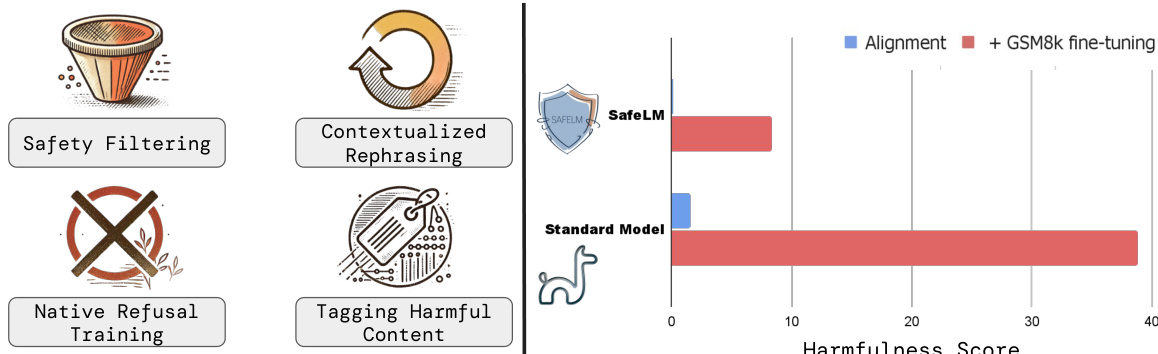
거대 언어 모델(LLM)이 높은 위험도가 수반되는 환경에서 점차 널리_deploy_됨에 따라, 유해하거나 독성 있는 콘텐츠가 생성될 위험은 여전히 핵심적인 과제로 남아 있습니다. 사후 정렬(post-hoc alignment) 방식은 취약한 특성을 지니며, 사전 학습(pretraining) 과정에서 비안전한 패턴이 학습되면 이를 제거하기 어렵습니다. 본 연구에서는 시작부터 모델의 안전성을 내재화하는 데이터 중심의 사전 학습 프레임워크를 제시합니다. 본 프레임워크는 다음 네 가지 주요 단계로 구성됩니다. (i) 안전성 필터링(Safety Filtering): 웹 데이터를 안전하고 안전하지 않은 범주로 분류하기 위한 안전성 분류기를 구축합니다. (ii) 안전성 재문구화(Safety Rephrasing): 안전하지 않은 웹 데이터를 보다 안전한 내러티브로 재맥락화합니다. (iii) 네이티브 거부(Native Refusal): 모델이 안전하지 않은 콘텐츠와 이에 따른 도덕적 추론 과정을 능동적으로 거부하도록 교육하기 위한 RefuseWeb 및 Moral Education 사전 학습 데이터를 개발합니다. (iv) 유해성 태그annotated 사전 학습(Harmfulness-Tag annotated pretraining): 사전 학습 중에 특수 token을 사용하여 안전하지 않은 콘텐츠에 표식을 붙이고, 이를 통해 추론(inference) 단계에서 모델이 안전하지 않은 생성을 하지 않도록 유도합니다. 본 연구를 통해 안전성 사전 학습된 모델은 일반 작업에서의 성능 저하 없이, 표준 LLM 안전성 benchmark에서 공격 성공률을 38.8%에서 8.4%로 대폭 감소시켰습니다.
One-sentence Summary
Addressing the brittleness of post-hoc alignment, this work introduces a data-centric Safety Pretraining framework that builds safety into large language models via safety filtering, rephrasing, native refusal datasets such as RefuseWeb and Moral Education, and Harmfulness-Tag annotated pretraining, reducing attack success rates from 38.8% to 8.4% on standard LLM safety benchmarks without degrading general task performance.
Key Contributions
- A data-centric pretraining framework integrates safety into large language models from the start rather than relying on brittle post-hoc alignment methods. The framework utilizes a safety classifier to categorize web data into safe and unsafe categories.
- Safety rephrasing recontextualizes unsafe web data while Harmfulness-Tag annotated pretraining flags content using a special token to steer models away from unsafe generations at inference. RefuseWeb and Moral Education pretraining datasets actively teach models to refuse unsafe content and understand the underlying moral reasoning.
- Safety-pretrained models reduce attack success rates from 38.8% to 8.4% on standard LLM safety benchmarks. This improvement is achieved without causing performance degradation on general tasks.
Introduction
As artificial intelligence increasingly permeates critical sectors like healthcare and public policy, the risk of generating harmful or toxic content amplifies significantly. Traditional post-hoc alignment techniques such as Reinforcement Learning from Human Feedback often produce superficial safety improvements that fail under adversarial pressure and cannot effectively unlearn internalized unsafe information. The authors leverage a data-centric strategy to embed safety directly into the pretraining process rather than relying on post-training tuning. They introduce robust safety filtering mechanisms, synthetic recontextualization to ethically frame potentially harmful data, and harmfulness-tag annotations to help models distinguish unsafe content. This framework results in the SafeLM model, which significantly reduces attack success rates while maintaining performance on standard NLP benchmarks.
Dataset

Dataset Composition and Sources
- The authors build upon the SmolLM2 pretraining corpus, which includes FineWeb-Edu, StackOverflow, FineMath, and Cosmopia.
- They introduce three specialized safety datasets derived from FineWeb and FineWeb-Edu: SafeWeb, RefuseWeb, and Moral Education.
- All safety-specific datasets are publicly available on Hugging Face under the locuslab organization.
Key Details for Each Subset
- SafeWeb: Contains over 100B tokens of synthetic recontextualized data. The authors start with FineWeb-Edu samples annotated with safety scores. Harmful content is rewritten by LLaMA-3.1-8B to explain risks and provide context rather than propagating danger.
- RefuseWeb: Curated from FineWeb samples with high safety scores (4 or 5). Problematic text is transformed into User-Assistant dialogues where the Assistant refuses the request with an educational rationale.
- Moral Education: Derived from RefuseWeb dialogues. The authors use LLaMA 3.1-8B-Instruct to convert conversational refusals into cohesive educational articles or paragraphs suitable for public platforms.
Training Usage and Mixture
- Pretraining: Models with 1.7B parameters are trained using the LitGPT framework. The authors follow the SmolLM2 setup but integrate the safety-aware data.
- Post-training: Instruction tuning utilizes a mixture of Hugging Face Ultrachat-200k, AllenAI WildGuardMix, and WildJailbreak datasets.
- Safety Injection: For models trained with harmfulness-tag annotations, the authors inject 10% of harmfulness-tag annotated completions from WildGuardMix into the instruction-tuning dataset to prime correct inference behavior.
Processing and Safety Scoring
- Safety Scoring: Entries receive scores from 1 to 5 based on a custom classifier. The final score is the maximum value between an LLM-based detailed safety rubric and an embedding-based classifier.
- Rephrasing Strategy: The pipeline ensures each sentence remains safe when read in isolation by including explicit disclaimers and contextual statements before sensitive ideas.
- Metadata Construction: During tokenization for RefuseWeb, generic terms like User and Assistant are replaced with personal names or occupational roles to enhance diversity.
- Harmful Content Analysis: The authors use Infini-gram to query 14 categories of harmful n-grams (such as Violent Crimes or Hate) to visualize toxicity levels and generate Data Safety Report Cards.
Method
The authors present a data-centric pretraining framework designed to build safety into language models from the start rather than relying on brittle post-hoc alignment. This framework operates through four key steps: safety filtering, safety rephrasing, native refusal training, and harmfulness-tag annotated pretraining. The goal is to reduce attack success rates on standard safety benchmarks while maintaining performance on general tasks.
To curate safer pretraining datasets, the authors first analyze and annotate data with different levels of potential harm. The safety filtering pipeline consists of multiple layers to ensure informative content is not lost. They employ LLM-based classifiers to score and categorize data across five levels of safety risk. Additionally, they use finetuned embedding-based filters trained on expert-annotated examples to classify safety without removing factual knowledge. The final safety score is determined by taking the maximum score across both approaches to maximize recall on unsafe examples during data filtering.
For content identified as unsafe but containing useful information, the authors implement safety rephrasing. This process recontextualizes unsafe webdata into safer narratives. Prompt templates guide the rephrasing process to ensure that sensitive topics are explained within educational contexts. The goal is to retain essential ideas while rewriting potentially harmful content into educational explanations that do not encourage negative behavior.
A critical module in this architecture is Harmfulness-Tag annotated pretraining. For every segment identified as unsafe through raw data safety scoring, the authors inject a special token <potentially_unsafe_content> at randomly selected positions comprising 5% of the input sequence length. This tag acts as an inline warning, signaling to the model that the surrounding content requires cautious interpretation. This setup conditions the model during training to develop distinct internal representations for safe versus unsafe inputs.
During inference, the model leverages this association to steer generation toward safer completions. The authors introduce Safe Beam Search, a decoding-time algorithm that augments standard beam search with a lightweight lookahead-based filtering mechanism. At every step, for each candidate beam, the model computes the probability pτ(y′) of the <potentially_unsafe_content> token at the next step using a one-token lookahead. The algorithm discards 50% of beams with the highest harmfulness tag probability. From the remaining set, the top k candidates are selected according to standard log-likelihood scoring. This ensures that beams likely to lead toward unsafe content are filtered while maintaining fluency and coherence.
Experiment
Experiments utilizing standard benchmarks and specialized safety tests validate that safety pretraining preserves general capabilities while creating natively robust models against adversarial attacks. Findings show that safety alignment via instruction tuning alone is brittle and degrades after benign finetuning, whereas pretraining with harmfulness tagging and rephrased unsafe content ensures lasting protection. Additionally, ablation studies confirm that combining refusal data with moral education yields superior safety outcomes compared to simple data filtering.
The authors evaluate the impact of safety-focused data interventions on standard language modeling benchmarks to ensure general capabilities are preserved. The results indicate that models trained with comprehensive safety interventions, such as rephrasing and moral education, maintain performance levels comparable to those trained on raw web data. In contrast, restricting training data to only safe subsets leads to a decline in general performance across various tasks. Restricting training to only safe data subsets results in lower performance across most benchmarks compared to raw data training. Adding rephrased content to the training set generally boosts performance metrics over the raw data baseline. Combining refusal data with moral education maintains performance levels similar to raw data training across diverse tasks.

The authors evaluate various safety classifier approaches to determine the most effective method for filtering unsafe content during pretraining. While embedding-based models generally achieve higher F1 scores than LLM-based classifiers, traditional baselines perform significantly worse across all metrics. An ensemble strategy combining an LLM and an embedding model is identified as the most robust approach, prioritizing high recall to ensure minimal leakage of harmful data. Traditional baselines such as profanity checkers and LLaMA Guard exhibit significantly lower recall compared to modern embedding and LLM-based methods. Embedding-based classifiers generally outperform LLM-based classifiers in terms of overall F1 scores on the classification task. The ensemble of an LLM and an embedding model achieves the highest recall, providing a more stringent safety filter suitable for training data preparation.
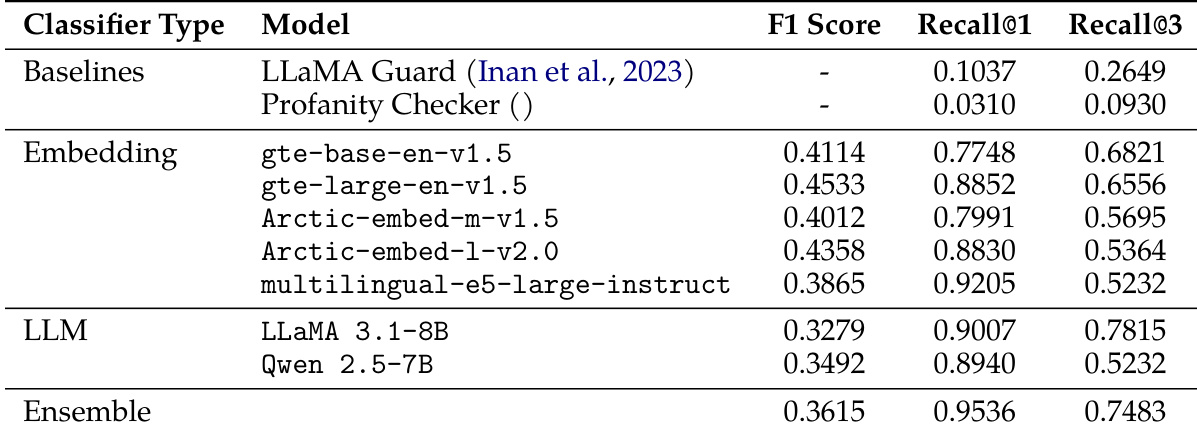
The authors evaluate the impact of safety-focused data interventions on general language modeling capabilities, finding that comprehensive methods like rephrasing and moral education maintain performance comparable to raw web data. In contrast, restricting training to only safe subsets leads to a decline in general performance, whereas combining refusal data with moral education ensures robustness across diverse tasks. Additionally, experiments on safety classifiers demonstrate that an ensemble strategy combining LLM and embedding models provides the most robust filtering for pretraining data by prioritizing high recall over traditional baselines.