Command Palette
Search for a command to run...
Kiss3DGen: 3D Asset Generation을 위한 Image Diffusion Model의 재구성
Kiss3DGen: 3D Asset Generation을 위한 Image Diffusion Model의 재구성
Jiantao Lin Xin Yang Meixi Chen Yingjie Xu Dongyu Yan Leyi Wu Xinli Xu Lie Xu Shunsi Zhang Ying-Cong Chen
Kiss3DGen: 이미지 확산 모델 기반의 3D 에셋 생성 프레임워크
초록
Diffusion 모델은 2D 이미지 생성 분야에서 큰 성공을 거두었습니다. 그러나 3D 콘텐츠 생성의 품질과 일반화 능력은 여전히 제한적인 수준에 머물러 있습니다. 최신 기술(State-of-the-art)들은 대개 학습을 위해 대규모 3D 에셋(assets)을 필요로 하지만, 이러한 데이터를 수집하는 것은 매우 어렵습니다.본 논문에서는 잘 학습된 2D 이미지 diffusion model을 3D 생성에 재용도화(repurposing)하여, 3D 오브젝트를 효율적으로 생성, 편집 및 향상시킬 수 있는 프레임워크인 Kiss3DGen(Keep It Simple and Straightforward in 3D Generation)을 소개합니다. 구체적으로, 본 연구에서는 multi-view 이미지와 그에 대응하는 normal map으로 구성된 타일 형태의 표현 방식인 "3D Bundle Image"를 생성하도록 diffusion model을 fine-tune합니다. 이후 생성된 normal map을 사용하여 3D mesh를 재구성하고, multi-view 이미지를 통해 texture mapping을 수행함으로써 완전한 3D 모델을 완성합니다.이러한 단순한 방식은 3D 생성 문제를 2D 이미지 생성 작업으로 효과적으로 전환하여, 사전 학습된(pretrained) diffusion model에 축적된 지식의 활용을 극대화합니다. 나아가, Kiss3DGen 모델이 다양한 diffusion model 기술과 호환됨을 입증하였으며, 이를 통해 3D editing, mesh 및 texture enhancement와 같은 고급 기능을 구현할 수 있음을 보여줍니다. 광범위한 실험을 통해 본 연구의 접근 방식이 효과적임을 증명하였으며, 고품질의 3D 모델을 효율적으로 생성할 수 있는 능력을 확인하였습니다.
One-sentence Summary
Kiss3DGen is an efficient framework that repurposes pretrained 2D image diffusion models for 3D asset generation by fine-tuning them to produce "3D Bundle Images" composed of multi-view images and normal maps, a method that transforms 3D reconstruction into a 2D task to enable high-quality 3D editing and enhancement.
Key Contributions
- This work introduces Kiss3DGen, an efficient framework that repurposes pretrained 2D image diffusion models for 3D generation by transforming the process into a 2D image generation task.
- The method utilizes a novel "3D Bundle Image" representation, which consists of tiled multi-view images and corresponding normal maps, to enable 3D mesh reconstruction and texture mapping.
- The framework demonstrates high versatility and effectiveness across various tasks including text-to-3D, image-to-3D, 3D enhancement, and 3D editing, while maintaining compatibility with existing diffusion model techniques.
Introduction
High-quality 3D asset generation is essential for industries like gaming and virtual reality, yet it faces significant hurdles due to the scarcity of large-scale, high-quality 3D datasets compared to the vast availability of 2D images. Existing optimization-based methods are often too slow for practical use, while direct generation approaches struggle with limited generalizability because they rely heavily on compromised 3D training data. The authors leverage the powerful priors of pretrained 2D diffusion models by repurposing them through a framework called Kiss3DGen. They introduce a "3D Bundle Image" representation, which combines multi-view RGB images and normal maps into a single tiled format that can be processed by standard 2D diffusion architectures. This approach enables efficient text-to-3D and image-to-3D generation, as well as advanced 3D editing and enhancement by integrating with techniques like ControlNet.
Dataset
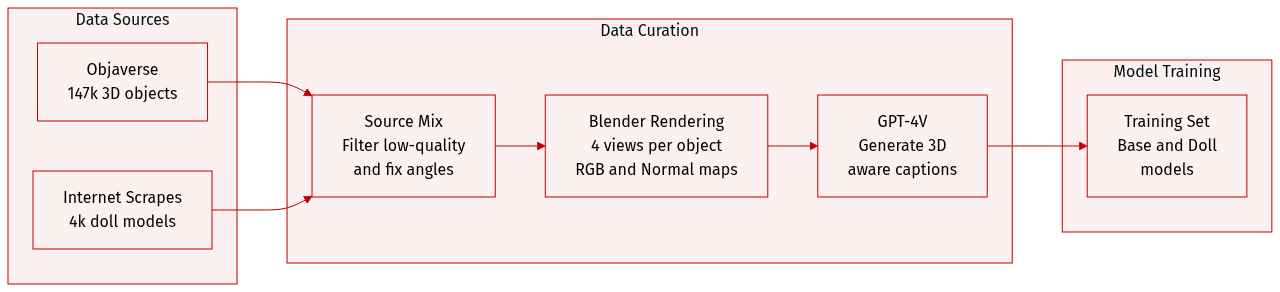
The authors constructed two distinct datasets to support different model capabilities:
-
Dataset Composition and Sources
- Kiss3DGen-Base Dataset: Derived from the Objaverse dataset, this collection contains 147k high-quality 3D objects.
- Kiss3DGen-Doll Dataset: A specialized subset of 4k high-quality, cartoon-style human body models curated from the internet.
-
Data Processing and Filtering
- Quality Control: The authors excluded objects from Objaverse that lacked texture maps or possessed low polygon counts. They further performed manual curation to remove incomplete objects, scanned flat surfaces, and large-scale scenes.
- Orientation Correction: To address irregular object orientations, the authors manually annotated and corrected the front-facing angle for every object.
-
Rendering and Metadata Construction
- Rendering Configuration: Objects were rendered using Blender with a camera distance of 4.5 units and a 30-degree field of view.
- View Generation: For each object, the authors rendered four views at 90-degree azimuthal increments. The first view was aligned to the corrected front-facing angle, while the elevation was fixed at 5 degrees.
- Output Specifications: Each view produced RGB and Normal maps at a resolution of 512 by 512 pixels.
- Captioning: The four rendered views were used as inputs for GPT-4V to generate 3D-aware caption annotations.
Method
The authors propose Kiss3DGen, a framework that repurposes a powerful Diffusion Transformer (DiT) for 3D generation tasks. The core approach involves a two-stage process: Stage I focuses on 3D Bundle Image generation, and Stage II handles 3D reconstruction.
As shown in the framework diagram:
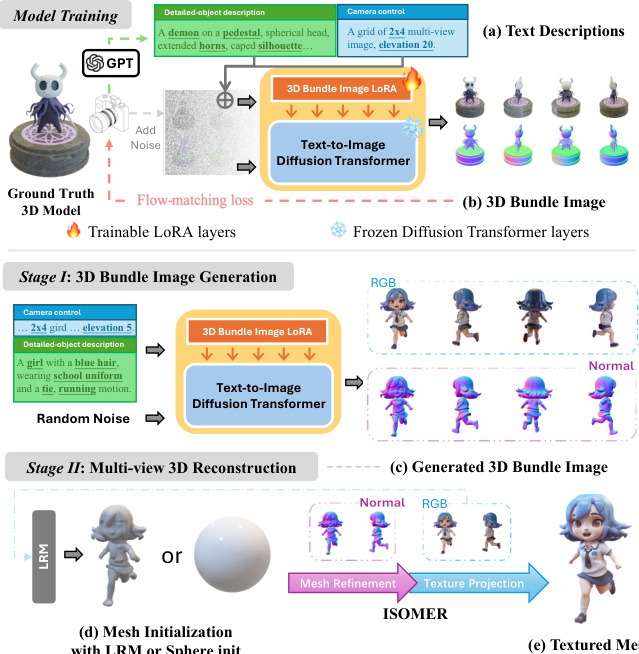
In Stage I, the Kiss3DGen-Base model is trained to generate high-quality 3D Bundle Images. A 3D Bundle Image is a multi-view representation consisting of four distinct views, each paired with its corresponding normal map. This combination of RGB and normal maps captures both color and geometric information. To achieve this, the authors leverage a pretrained Flux DiT model and train a LoRA layer to retarget the model for 3D Bundle Image generation. To enhance semantic alignment, detailed captions are generated for each bundle using GPT-4V. The DiT architecture is particularly suited for this task as its attention blocks are effective at modeling the long-range dependencies between different views and the cross-modal relationships between RGB images and normal maps.
Once the 3D Bundle Images are generated, Stage II performs 3D reconstruction. The authors utilize LRM or a sphere initialization followed by optimization-based mesh refinement and texture projection via ISOMER to convert the 2D bundle into a textured 3D mesh.
To extend the framework's utility, the authors introduce Kiss3DGen-ControlNet, which enables 3D enhancement, editing, and image-to-3D generation. For 3D enhancement, a low-quality mesh is rendered into a 3D Bundle Image and processed through ControlNet-Tile and ControlNet-Normal modules. To maintain semantic integrity during enhancement, Florence-2 is used to generate captions for the RGB components. The authors introduce two hyperparameters to control this process: λ1 represents the ControlNet Strength, where the feature y is calculated as y=F(x)+λ1Fc(c), and λ2 represents the fraction of diffusion steps during which the ControlNet is active.
As shown in the figure below:
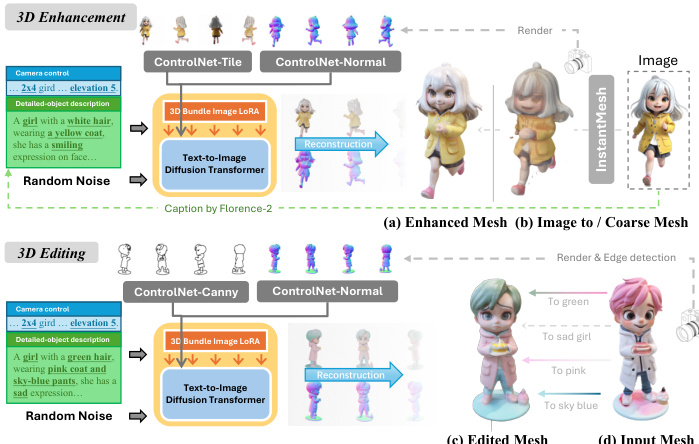
For 3D editing, the framework allows users to alter specific attributes like shape or texture by adjusting the ControlNet weight and providing customized captions. This is implemented using ControlNet-Canny and ControlNet-Normal. Additionally, the framework supports image-to-3D generation by taking a coarse mesh from existing pipelines and refining it through the enhancement pipeline.
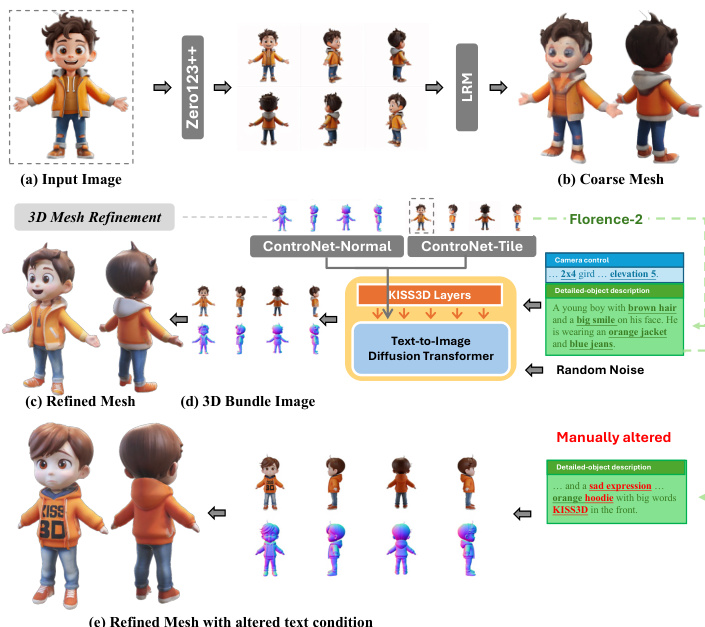
Finally, the authors present an advanced image-to-3D pipeline that integrates multi-modal conditions, including both images and text. This allows for precise textual control during the 3D mesh refinement stage, enabling users to achieve specific desired outcomes from an initial image input.
Refer to the figure below:
Experiment
The evaluation assesses the Kiss3DGen framework through text-to-3D, image-to-3D, and multi-view synthesis tasks using the Google Scanned Objects dataset. Experiments validate the effectiveness of the proposed 3D Bundle Image mechanism, the robustness of LRM-based mesh initialization, and the efficiency of the model even when trained on reduced datasets. Overall, the results demonstrate that the method achieves superior performance in texture fidelity, geometric coherence, and semantic alignment compared to state-of-the-art baselines.
The authors compare the inference time of their framework against several state-of-the-art methods across three different tasks. Results show that the proposed method achieves competitive performance while maintaining reasonable processing speeds. The proposed method demonstrates efficient inference times across text-to-3D, image-to-3D, and 3D-to-3D tasks. In the 3D-to-3D task, the proposed approach is significantly faster than the compared baseline. The framework maintains a balance between computational speed and task performance compared to existing models.

The authors compare their image-to-3D generation methods against existing state-of-the-art models using various geometric and visual quality metrics. The results demonstrate that the proposed approach achieves competitive or superior performance across most evaluated dimensions, even when trained on a smaller dataset. The base model achieves high visual quality and geometric accuracy, outperforming several established methods. A version of the model trained on a reduced dataset of 50k samples maintains strong performance comparable to the larger scale version. The proposed method shows significant advantages in terms of reconstruction fidelity and structural similarity.
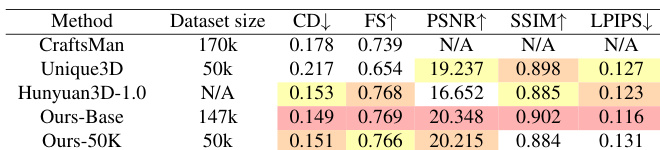
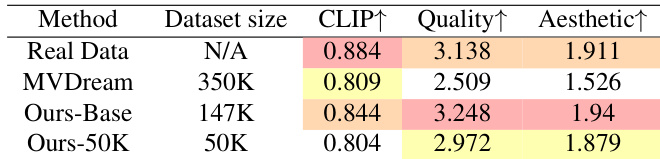
The authors compare their text-to-multi-view synthesis approach against MVDream using different dataset scales and real-world data benchmarks. The results demonstrate that the proposed method achieves high levels of visual quality and aesthetic appeal, even when trained on a significantly smaller dataset. The base model outperforms MVDream across CLIP score, quality, and aesthetic metrics. The method trained on a reduced dataset of 50K samples remains highly competitive and maintains strong performance. The proposed approach even surpasses the real data benchmarks in terms of visual quality and aesthetics.
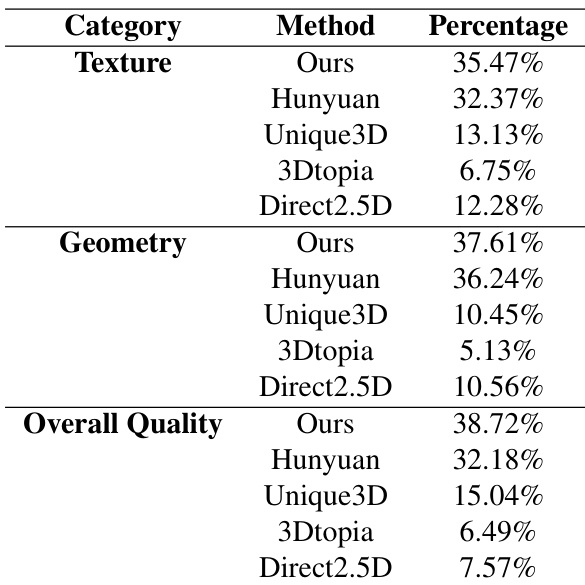
The authors conduct a user study to evaluate the preference for 3D generation results across different methods. The results demonstrate that the proposed approach is preferred by users more frequently than existing state-of-the-art methods in terms of texture, geometry, and overall quality. The proposed method achieves the highest user preference across all evaluated categories. In terms of texture and geometry, the proposed approach shows a clear advantage over competing models. The proposed method also leads in overall quality preference compared to the baseline methods.
The authors compare two different initialization methods for the reconstruction stage of their framework. The results demonstrate that initializing with an LRM model leads to better performance across all evaluated metrics compared to using a simple sphere shape. LRM initialization achieves higher text-image alignment than sphere initialization The LRM approach produces superior visual quality and aesthetic results Initializing with a sphere leads to lower scores across all assessed dimensions

The framework is evaluated through comparative analyses of inference efficiency, reconstruction fidelity, multi-view synthesis quality, and user preference across various 3D generation tasks. The results demonstrate that the proposed method maintains a superior balance between computational speed and high-quality visual and geometric output, even when trained on reduced datasets. Furthermore, user studies and initialization tests confirm that the approach achieves higher aesthetic appeal and better alignment than existing state-of-the-art methods, particularly when utilizing LRM-based initialization.