Command Palette
Search for a command to run...
Cache 기반 추론을 이용한 스트리밍 자동 음성 인식을 위한 Stateful Conformer
Cache 기반 추론을 이용한 스트리밍 자동 음성 인식을 위한 Stateful Conformer
Vahid Noroozi Somshubra Majumdar Ankur Kumar Jagadeesh Balam Boris Ginsburg
Nemotron-Speech-Streaming-ASR: 자동 음성 인식 데모
초록
본 논문에서는 FastConformer 아키텍처를 기반으로 한 효율적이고 정확한 스트리밍 음성 인식(streaming speech recognition) 모델을 제안합니다. 본 연구에서는 다음과 같은 방식을 통해 FastConformer 아키텍처를 스트리밍 애플리케이션에 적합하도록 최적화하였습니다: (1) 인코더 내의 look-ahead context와 past context를 모두 제한하였으며, (2) 비자기회귀(non-autoregressive) 방식인 인코더가 추론(inference) 단계에서 자기회귀(autoregressively) 방식으로 동작할 수 있도록 activation caching 메커니즘을 도입하였습니다.제안된 모델은 기존의 많은 스트리밍 모델에서 흔히 발생하는 학습(train) 시점과 추론(inference) 시점 사이의 정확도 격차를 해소할 수 있도록 정교하게 설계되었습니다. 또한, 제안된 인코더는 Connectionist Temporal Classification (CTC) 및 RNN-Transducer (RNNT) 디코더를 포함한 다양한 디코더 구성과 함께 작동할 수 있습니다. 이에 더해, CTC와 RNNT 디코더가 인코더를 공유하는 hybrid CTC/RNNT 아키텍처를 도입하여 정확도를 높이는 동시에 연산량을 절감하였습니다.LibriSpeech 데이터셋과 멀티 도메인 대규모 데이터셋을 통해 제안된 모델을 평가한 결과, 기존의 버퍼 기반 스트리밍 모델(buffered streaming model) 베이스라인과 비교하여 더 낮은 latency 및 inference time으로 더 높은 정확도를 달성할 수 있음을 입증하였습니다. 또한, 단일 latency 모델보다 다양한 latency를 가진 모델을 함께 학습시키는 것이 더 높은 정확도를 달성할 수 있음을 보여주었으며, 이를 통해 단일 모델만으로도 여러 가지 latency를 지원할 수 있음을 확인하였습니다.
One-sentence Summary
By constraining look-ahead and past contexts and introducing an activation caching mechanism, the authors propose a stateful FastConformer architecture for streaming automatic speech recognition that eliminates the accuracy disparity between training and inference and supports hybrid CTC/RNNT decoders to achieve superior accuracy and lower latency on the LibriSpeech and multi-domain large-scale datasets.
Key Contributions
- The paper introduces an efficient streaming speech recognition model based on the FastConformer architecture by constraining both look-ahead and past contexts in the encoder to minimize the accuracy gap between training and inference.
- A novel activation caching mechanism is presented that converts the non-autoregressive encoder into an autoregressive recurrent model during inference, which eliminates the need for redundant buffer computations and reduces inference costs.
- A hybrid CTC/RNNT architecture is developed using a shared encoder with both decoders to improve accuracy and convergence speed while saving computation, outperforming conventional buffered streaming models on the LibriSpeech and multi-domain datasets.
Introduction
Streaming automatic speech recognition (ASR) is essential for real-time applications, yet it faces a significant accuracy gap compared to offline models that utilize global context. Traditional streaming methods often rely on large overlapping buffers to mitigate this gap, which leads to redundant and costly computations, or they use architectures that create inconsistencies between training and inference. The authors leverage the FastConformer architecture to introduce a stateful streaming model that utilizes an activation caching mechanism. This approach converts a non-autoregressive encoder into an autoregressive recurrent model during inference, allowing for efficient processing without the need for overlapping chunks. By constraining both look-ahead and past contexts during training, the authors ensure consistency between training and streaming modes, significantly reducing latency and computational overhead while improving accuracy.
Method
The authors propose a cache-aware streaming FastConformer designed to maintain consistent behavior between training and inference by controlling the left and right contexts of each audio step. While the original FastConformer encoder utilizes self-attention, convolutions, and linear layers, the streaming version requires specific modifications to ensure causality. For instance, the authors replace batch normalization with layer normalization to avoid using statistics from the entire input sequence and ensure all convolution layers are fully causal through specific padding strategies.
To manage the context size in self-attention layers, the authors evaluate three distinct approaches. The first is zero look-ahead, which uses masking to ensure each step only accesses past tokens, resulting in low latency but potentially lower accuracy. The second is regular look-ahead, where a fixed number of future tokens are accessible. As shown in the figure below, in this approach, the dependency on future frames increases as the model moves deeper into the network, which can lead to significant latency and unnecessary re-computation of tokens.
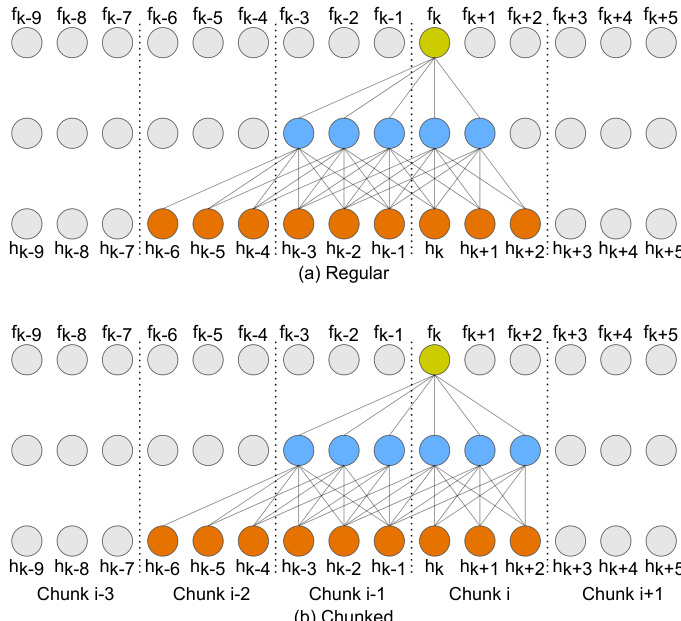
The third approach, chunk-aware look-ahead, addresses these limitations by splitting the input into chunks of size C. In this configuration, tokens within a chunk can access other tokens in the same chunk and a limited number of previous chunks. Refer to the framework diagram to see how this approach maintains a constant dependency on future frames regardless of network depth. This method eliminates redundant computations and allows for an average look-ahead that is larger than the regular approach, improving accuracy within the same latency budget.
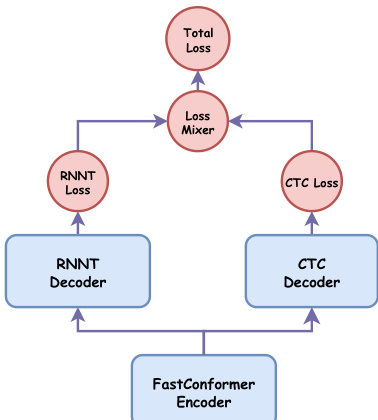
To optimize the training process, the authors employ a hybrid architecture that utilizes both a CTC decoder and an RNNT decoder sharing a single encoder. This design allows for faster convergence and improved accuracy for both decoders through joint training. The total loss optimized during training is a weighted summation of the individual losses:
ltotal=α⋅lctc+lrnntwhere α is a hyperparameter controlling the balance between the two. The architecture of this hybrid model is illustrated in the figure below:

During streaming inference, the model processes input in chunks. To avoid the inefficiency of re-computing past context, the authors implement a caching mechanism. For causal 1D depth-wise convolutions, a fixed-size cache stores the last K−1 activations. For self-attention layers, the cache size grows until it reaches the maximum allowed left context size Lc, at which point the oldest activations are dropped. This caching strategy ensures that the streaming inference results are identical to processing the entire audio in a single step while significantly reducing computational duplication.
Experiment
The researchers evaluated a cache-aware streaming FastConformer architecture using CTC and RNNT decoders across LibriSpeech and the large-scale NeMo ASRSET 3.0 datasets. The experiments demonstrate that cache-aware models provide superior accuracy, lower latency, and greater computational efficiency compared to traditional buffered streaming approaches. Furthermore, the results show that utilizing a hybrid architecture and multi-lookahead training improves model robustness and accuracy across various latency requirements.
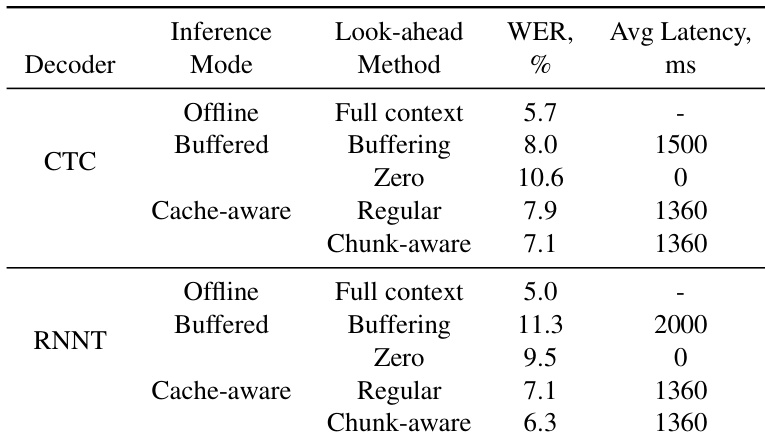
The authors compare the performance of CTC and RNNT decoders across different inference modes, including offline, buffered, and cache-aware approaches. Results show that cache-aware methods, particularly the chunk-aware approach, provide better accuracy and lower latency compared to buffered streaming. Cache-aware models achieve higher accuracy than buffered streaming models for both CTC and RNNT decoders. Chunk-aware streaming outperforms regular look-ahead methods in terms of accuracy at equivalent latency levels. The accuracy degradation from offline models is smaller in cache-aware streaming than in buffered streaming approaches.
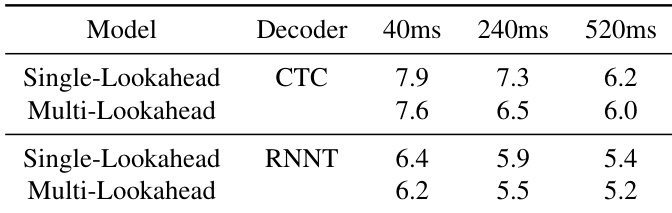
The authors compare single-lookahead models against multi-lookahead models across different latencies for both CTC and RNNT decoders. Results show that training with multiple lookaheads improves accuracy and robustness across all tested latency levels. Multi-lookahead models achieve better accuracy than single-lookahead models for both CTC and RNNT decoders. The performance improvement from multi-lookahead training is consistent across various latency settings. RNNT decoders generally demonstrate higher accuracy compared to CTC decoders in this configuration.
The authors evaluate the performance of cache-aware streaming models using both CTC and RNNT decoders across multiple speech datasets. Results demonstrate that cache-aware approaches consistently outperform buffered streaming methods in terms of accuracy across various benchmarks. Cache-aware models achieve higher accuracy than buffered streaming models while maintaining significantly lower latency Increasing the look-ahead size leads to improved accuracy for both CTC and RNNT decoders RNNT-based cache-aware models generally show better performance across most benchmarks compared to their CTC counterparts

The authors compare regular and chunk-aware streaming approaches using hybrid and non-hybrid architectures for both CTC and RNNT decoders. Results show that the chunk-aware approach provides more flexibility across different latency levels and generally achieves better accuracy than the regular approach. Chunk-aware models achieve higher accuracy than regular look-ahead models at comparable latency levels Hybrid architectures demonstrate superior performance compared to non-hybrid architectures in the chunk-aware setting The RNNT decoder consistently outperforms the CTC decoder across the evaluated latency settings
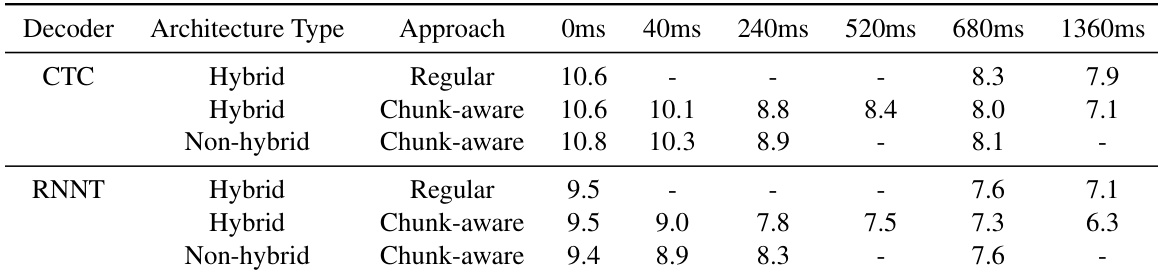
The experiments evaluate various inference modes, look-ahead strategies, and architectural configurations for CTC and RNNT decoders across multiple speech datasets. The results demonstrate that cache-aware and chunk-aware streaming approaches consistently provide superior accuracy and lower latency compared to traditional buffered or regular look-ahead methods. Furthermore, training with multi-lookahead models and utilizing hybrid architectures enhances robustness and performance, with RNNT decoders generally outperforming CTC decoders across most settings.