Command Palette
Search for a command to run...
Stochastic Gradient Descent의 빠른 불확실성 정량화를 위한 저비용 부트스트랩
Stochastic Gradient Descent의 빠른 불확실성 정량화를 위한 저비용 부트스트랩
Henry Lam Zitong Wang
초록
확률적 경사 하강법 (SGD) 또는 확률적 근사법은 모델 학습 및 확률적 최적화 분야에서 광범위하게 활용되어 왔습니다. SGD 의 수렴성에 대한 분석을 다루는 방대한 문헌이 존재함에도 불구하고, SGD 를 통해 얻어진 해에 대한 통계적 추론 (inference) 은 비교적 최근에야 연구되기 시작했습니다. 그러나 불확실성 정량화 (uncertainty quantification) 에 대한 요구가 증가함에 따라 이는 매우 중요한 주제입니다. 본 연구에서는 SGD 해에 대한 신뢰구간을 구성하기 위해 계산 비용이 저렴한 두 가지 리샘플링 기반 방법을 고찰합니다. 첫 번째 방법은 데이터에서 복원 추출 (resampling with replacement) 을 수행하여 소수의 SGD 를 병렬로 실행하는 방식이며, 두 번째 방법은 이를 온라인 방식으로 운영합니다. 제안된 방법론은 기존 부트스트랩 (bootstrap) 기법을 개선한 것으로 볼 수 있으며, 리샘플링 요구 사항을 크게 줄여 계산 부하를 현저히 감소시키고, 기존 배칭 (batching) 방법에서 요구되는 복잡한 혼합 조건 (mixing conditions) 을 우회할 수 있습니다. 이러한 성과는 최근 제안된 '저렴한 부트스트랩 (cheap bootstrap)' 아이디어와 SGD 에 대한 Berry-Esseen 유형의 오차 상한 (bound) 을 정교화함으로써 달성되었습니다.
One-sentence Summary
Henry Lam and Zitong Wang from Columbia University propose two computationally cheap resampling methods to construct confidence intervals for stochastic gradient descent solutions. By leveraging a cheap bootstrap idea and refining Berry-Esseen bounds, their approach significantly reduces resampling requirements while bypassing complex mixing conditions in existing batching techniques for uncertainty quantification.
Key Contributions
- The paper introduces two computationally cheap resampling-based methods to construct confidence intervals for stochastic gradient descent solutions, utilizing either parallel runs with few replications or an online operational framework.
- These approaches enhance established bootstrap schemes by substantially reducing resampling requirements and bypassing the intricate mixing conditions typically needed in existing batching methods.
- Theoretical validity is supported by applying a recent cheap bootstrap concept and refining a Berry-Esseen-type bound specifically for stochastic gradient descent to ensure accurate uncertainty quantification.
Introduction
Stochastic gradient descent (SGD) is a cornerstone of modern machine learning and stochastic optimization, yet quantifying the statistical uncertainty of its solutions remains a critical challenge for applications requiring reliable confidence intervals. Prior approaches struggle with significant limitations, including the need for unavailable Hessian information, sensitivity to hyperparameter tuning in batch mean methods, high computational overhead from maintaining large ensembles in online bootstraps, or the requirement to fundamentally alter the SGD trajectory. The authors leverage a recent "cheap bootstrap" concept and refine a Berry-Esseen-type bound to introduce two computationally efficient resampling methods that construct valid confidence intervals with minimal resampling requirements while bypassing complex mixing conditions.
Method
The authors leverage a bootstrap approach designed to surmount challenges in SGD inference without requiring mixing-related tuning or substantial modification to the original SGD. This methodology synthesizes the recent cheap bootstrap idea with a derivation of the asymptotic joint distribution among SGD and resampled SGD runs. The framework supports both offline and online implementations, termed Cheap Offline Bootstrap (COfB) and Cheap Online Bootstrap (CONB).
For the offline version, COfB reruns the SGD using resampling with replacement from the data B times. It constructs confidence intervals from these resampled iterates via an approach similar to the standard error bootstrap. The key assertion is that B can be very small, such as 3, making the approach computationally less demanding than the delta method or online bootstrap. The online version, CONB, runs multiple, namely B+1, SGDs in parallel on the fly as new data comes in. It borrows the idea of perturbing the gradient estimate in the SGD iteration but maintains a very small number of SGD runs.
A comparison among different methods highlights the computational and memory advantages of the proposed approach. Refer to the comparison table below for a summary of these distinctions.
The delta method, random scaling, and online bootstrap demand a relatively heavy computation or memory load. In contrast, the proposed methods introduce B but keep it very small, resulting in a light computational and memory load. Additionally, the second derivative is only required by the delta method, which can be a challenge in some application scenarios.
The theoretical guarantees rely on establishing the asymptotic joint distribution, particularly independence, among SGD and resampled SGD runs. The authors prove a joint central limit theorem for both the original and resampled SGD runs when resampling with replacement. This guides the aggregation of outputs to construct asymptotically exact-coverage intervals. The confidence intervals are based on t-statistic construction and follow the behavior of t-intervals. While the widths are larger than those of normality intervals, they shrink rapidly as B increases.
In high-dimensional sparse settings, the authors extend the methods via a two-stage approach. The first stage reduces the problem to a lower-dimensional subspace via Lasso model selection. The second stage applies COfB or CONB to the problem confined to the support of the estimated parameter. This procedure correctly identifies the support of the true model parameter and provides confidence intervals with exact coverage for non-zero entries.
Experimental results support the statements regarding coverage probabilities and widths of confidence intervals. The results indicate that the methods generally deliver the most accurate coverage probabilities. Refer to the linear and logistic regression results below.
Although the methods produce wider confidence intervals, the interval width decreases sharply when B increases even slightly. In addition, the experiments suggest that the method outperforms others in terms of robustness. The analysis also applies to high-dimensional sparse linear regression to enlarge the scope of applicability. Refer to the sparse linear regression results below.
Experiment
- Experiments on linear and logistic regression with fixed dimensionality validate that the proposed COfB and COnB methods achieve accurate 95% coverage probabilities across various dimensions and covariance structures, whereas baseline methods like the delta method and HiGrad suffer from significant under-coverage as dimensionality increases.
- Comparative analysis demonstrates that while the proposed methods produce slightly wider confidence intervals than some baselines, they offer superior computational efficiency compared to the online bootstrap and avoid the high computational cost of matrix operations required by the delta and random scaling methods.
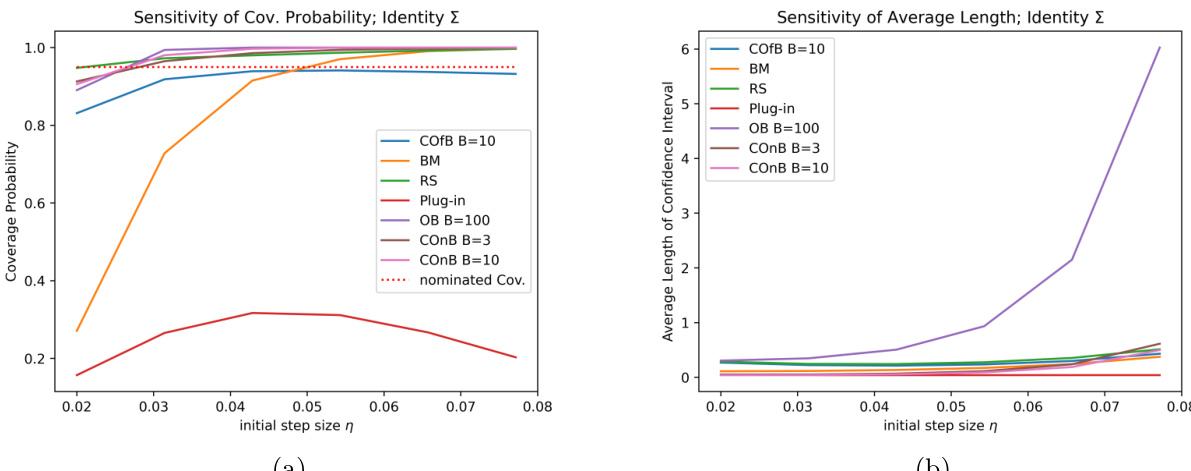
- Sensitivity analysis confirms that the proposed methods maintain stable coverage probabilities regardless of the initial step size, unlike the batch mean method which requires careful tuning, and the delta method which fails to provide valid intervals under varying step sizes.
- Experiments in sparse linear regression settings verify that the approach correctly identifies non-zero coefficients with near-nominal coverage while producing singleton intervals for zero coefficients, effectively handling model selection uncertainty.
- Robustness tests reveal that while the methods perform well under well-conditioned curvature and various learning rate schedules, performance degrades in extreme ill-conditioned scenarios, leading to wider intervals and reduced coverage accuracy.