Command Palette
Search for a command to run...
Quadratic Gradient: Hessian과 Gradient를 종합하여 Gradient Descent와 Newton-Type Methods를 연결하는 통합 프레임워크
Quadratic Gradient: Hessian과 Gradient를 종합하여 Gradient Descent와 Newton-Type Methods를 연결하는 통합 프레임워크
John Chiang
초록
이차 차수 최적화, 특히 뉴턴형 방법의 수렴 가속화는 알고리즘 연구에서 여전히 핵심적인 과제로 남아 있습니다. 본 논문에서는 기존 연구에서 제안된 Quadratic Gradient(QG)를 확장하여 일반적 볼록 수치 최적화 문제에 대한 적용성을 엄밀하게 검증합니다. 우리는 고전적인 고정 헤시안 (fixed Hessian) 뉴턴 프레임워크와 차별화된 Quadratic Gradient 의 새로운 변형을 제시합니다. 이 새로운 Quadratic Gradient 는 고정 헤시안 뉴턴 방법의 수렴 조건을 만족하지는 않지만, 실험 결과를 통해 기존 방법 대비 때로는 더 우수한 수렴 속도를 보임을 확인하였습니다. 본 변형은 일부 고전적 수렴 제약을 완화하면서도 양정치 (positive-definite) 헤시안 근사치를 유지하며, 수렴 속도 측면에서 기존 방법과 동등하거나 경우에 따라 더 뛰어난 경험적 성능을 입증합니다. 더 나아가, 원래 QG 와 제안된 변형 모두 비볼록 최적화 영역에서도 효과적으로 적용 가능함을 보였습니다. 본 연구의 주요 동기는 전통적인 스칼라 학습률의 한계에 있습니다. 우리는 대각 행렬이 이질적인 비율로 그래디언트 요소를 더 효과적으로 가속화할 수 있다고 주장합니다. 우리의 연구 결과는 Quadratic Gradient 를 현대 최적화를 위한 다목적이고 강력한 프레임워크로 정립합니다. 또한, 헤시안-벡터 곱 (Hessian-vector products) 을 통해 헤시안 대각 성분을 효율적으로 추정하기 위해 Hutchinson's Estimator 를 통합하였습니다. 특히, 제안된 Quadratic Gradient 변형이 딥러닝 아키텍처에서 매우 효과적임을 입증하여, 표준 적응형 옵티마이저에 대한 견고한 이차 차수 대안을 제공함을 보여줍니다.
One-sentence Summary
John Chiang proposes a novel Quadratic Gradient variant that replaces fixed Hessian Newton frameworks with a diagonal matrix approach to accelerate convergence in Deep Learning. By integrating Hutchinson's Estimator for efficient Hessian diagonal approximation, this method outperforms traditional scalar learning rates in non-convex optimization landscapes.
Key Contributions
- The paper introduces a novel variant of the Quadratic Gradient that departs from the fixed Hessian Newton framework by maintaining a positive-definite Hessian proxy, which allows for effective application to non-convex optimization landscapes where traditional methods often fail.
- This work integrates Hutchinson's Estimator to efficiently approximate the Hessian diagonal via Hessian-vector products, reducing the computational complexity of second-order information from O(n2) to O(n) and enabling scalability for Deep Learning architectures.
- Experimental results demonstrate that the proposed Quadratic Gradient variants achieve comparable or superior convergence rates compared to original methods and standard adaptive optimizers, validating their utility as a robust second-order alternative for general convex and non-convex problems.
Introduction
Modern numerical optimization struggles to balance the scalability of first-order methods like SGD with the rapid convergence of second-order approaches like Newton's method, as the former fails on ill-conditioned curvatures while the latter incurs prohibitive computational costs and sensitivity to Hessian indefiniteness. Prior work on the Quadratic Gradient (QG) has shown promise in specific tasks like logistic regression but often relies on fixed Hessian approximations that limit general applicability and theoretical convergence guarantees. The authors leverage a novel QG variant that synthesizes curvature information into a diagonal matrix to replace scalar learning rates, enabling dimension-wise acceleration without satisfying the strict constraints of traditional fixed Hessian Newton methods. By integrating Hutchinson's Estimator for efficient Hessian diagonal approximation, they establish a unified framework that extends to general convex and non-convex landscapes, offering a robust second-order alternative to standard adaptive optimizers in Deep Learning.
Dataset
The provided text only lists the titles "mnist" and "credi" under the section "Large-Scale Datasets" without offering any descriptive content. Consequently, it is not possible to draft a dataset description covering composition, sources, filtering rules, training splits, or processing strategies based on this input. No further details regarding dataset size, metadata construction, or model usage are available in the source material.
Experiment
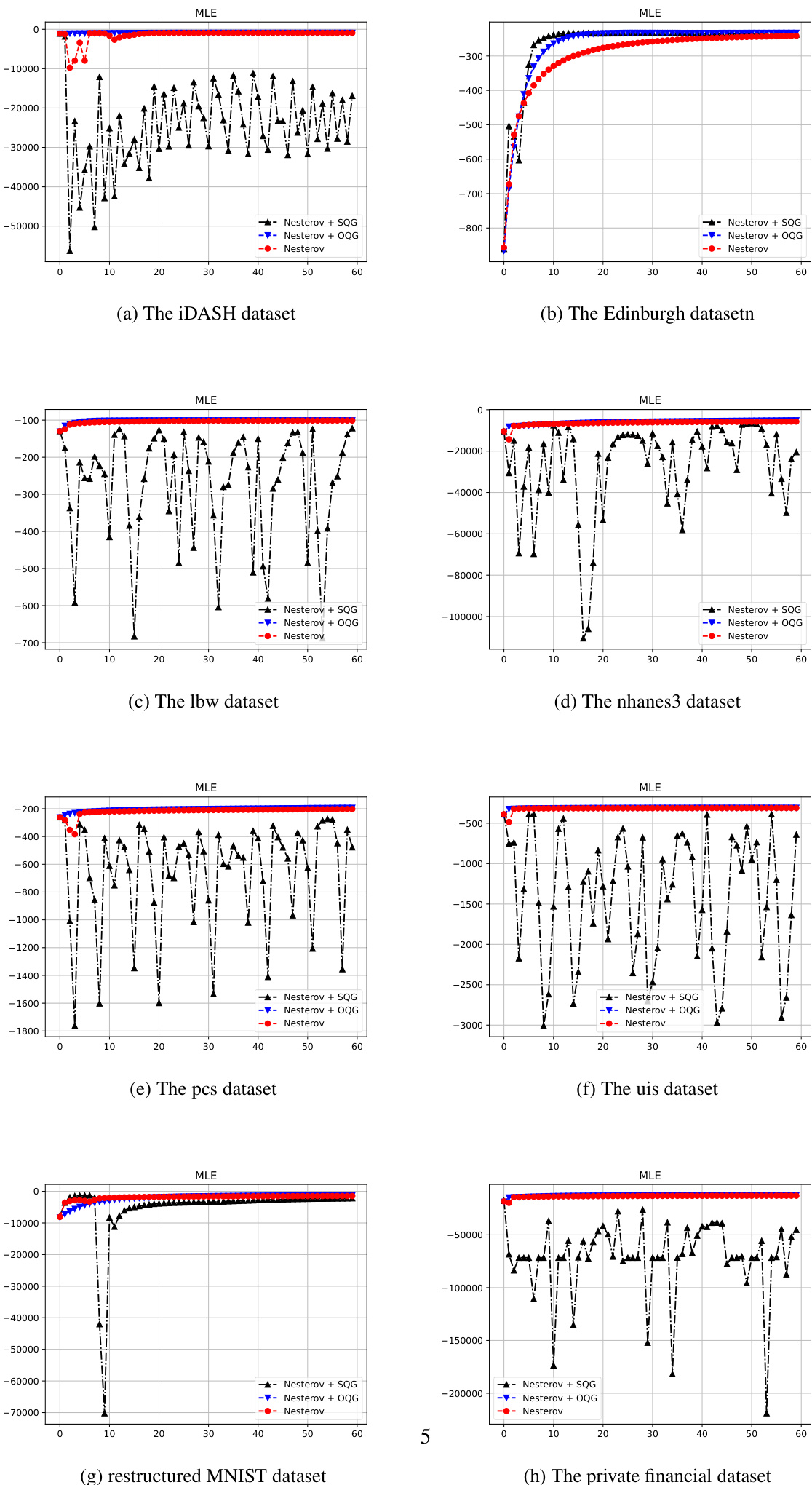
- Logistic regression experiments on multiple datasets validate that the Simplified Quadratic Gradient (SQG) framework maintains high computational efficiency and convergence speed comparable to the original method while offering a more streamlined architecture, though it requires conservative learning rate decay for NAG to ensure stability.
- Deep learning tests on ResNet-18 demonstrate that the new QG variant achieves faster convergence than Adam and exhibits superior stability in non-convex regions compared to AdaHessian, with computational overhead comparable to second-order methods.
- Benchmark evaluations on convex and non-convex functions confirm the algorithm's ability to handle dimensional scaling and navigate ill-conditioned valleys effectively.
- Saddle point analysis reveals that the QG variant overcomes the stagnation typical of first-order methods by utilizing spectral information to assign large adaptive steps along directions of minimal curvature, allowing the optimizer to escape saddle points efficiently.
- Overall, the framework successfully bridges first and second-order optimization by integrating Hessian approximations to accelerate convergence and robustly manage complex topological features in high-dimensional spaces.