HyperAI
Command Palette
Search for a command to run...
MuseV 無制限のバーチャル ヒューマン ビデオ生成デモ

プロジェクト紹介
MuseV これは、2024 年 3 月に Tencent Music Entertainment の Tianqin Lab によってオープンソース化されたバーチャル ヒューマン ビデオ生成フレームワークです。高品質のバーチャル ヒューマン ビデオとリップ シンクの生成に焦点を当てています。高度なアルゴリズムを利用して、高度な一貫性と自然な表現を備えた長編ビデオ コンテンツを生成します。公開されているものと組み合わせることができます ミューズトーク 組み合わせて使用すると、完全な「仮想ヒューマン ソリューション」を構築できます。
このモデルには次のような特徴があります。
- これは、エラー蓄積の問題を発生させずに、無限長生成のための新しい視覚条件並列ノイズ除去スキームの使用をサポートしており、特にカメラ位置が固定されたシーンに適しています。
- キャラクタータイプのデータセットに基づいてトレーニングされたバーチャルヒューマンビデオ生成用の事前トレーニング済みモデルが提供されます。
- 画像からビデオへ、テキストから画像からビデオへ、およびビデオからビデオへの生成をサポートします。
- 互換性がある
Stable Diffusionテキストと画像の生成エコシステムを含むbase_model、lora、controlnet待って。 - 以下を含む複数の参照画像テクノロジーをサポート
IPAdapter、ReferenceOnly、ReferenceNet、IPAdapterFaceID。
エフェクト表示
結果を生成するすべてのフレームは、によって直接生成されます。 MuseV 時間的超解像や空間的超解像などの後処理を一切行わずに生成されます。
このチュートリアルでは、次のすべてのテスト ケースを実装できます。テスト後、7 秒のビデオを生成するのに約 2 分半かかります。テストされた最長のビデオは 20 秒で 8 分かかります。
キャラクターエフェクト表示
| 画像 | ビデオ | プロンプト |
 | (傑作、最高品質、高解像度:1)、静かな美しい海の風景 | |
 | (傑作、最高品質、ハイレゾ:1)、ギターの演奏 | |
 | (傑作、最高品質、ハイレゾ:1)、ギターの演奏 |
シーンエフェクト表示
| 画像 | ビデオ | プロンプト |
 | (傑作、最高品質、高解像度:1)、静かな美しい滝、終わりのない滝 | |
 | (傑作、最高品質、高解像度:1)、静かな美しい海の風景 |
既存のビデオに基づいてビデオを生成する
| 画像 | ビデオ | プロンプト |
 | (傑作、最高品質、ハイレゾ:1)、踊っている、アニメーション |
ステップの実行
1. このチュートリアルの右上隅にある「クローン」ボタンを見つけて、「クローン」をクリックした後、プラットフォームのデフォルト設定を直接使用してコンテナを作成します。コンテナが正常に実行され開始されると、次のページが表示されます。下の図のプロンプトに従ってプロジェクト操作インターフェイスに入ります。
❗注意❗ モデルのサイズが大きいため、コンテナが正常に起動された後、API アドレスを開く前にモデルがロードされるのを待つのに約 1 分かかる場合があります。
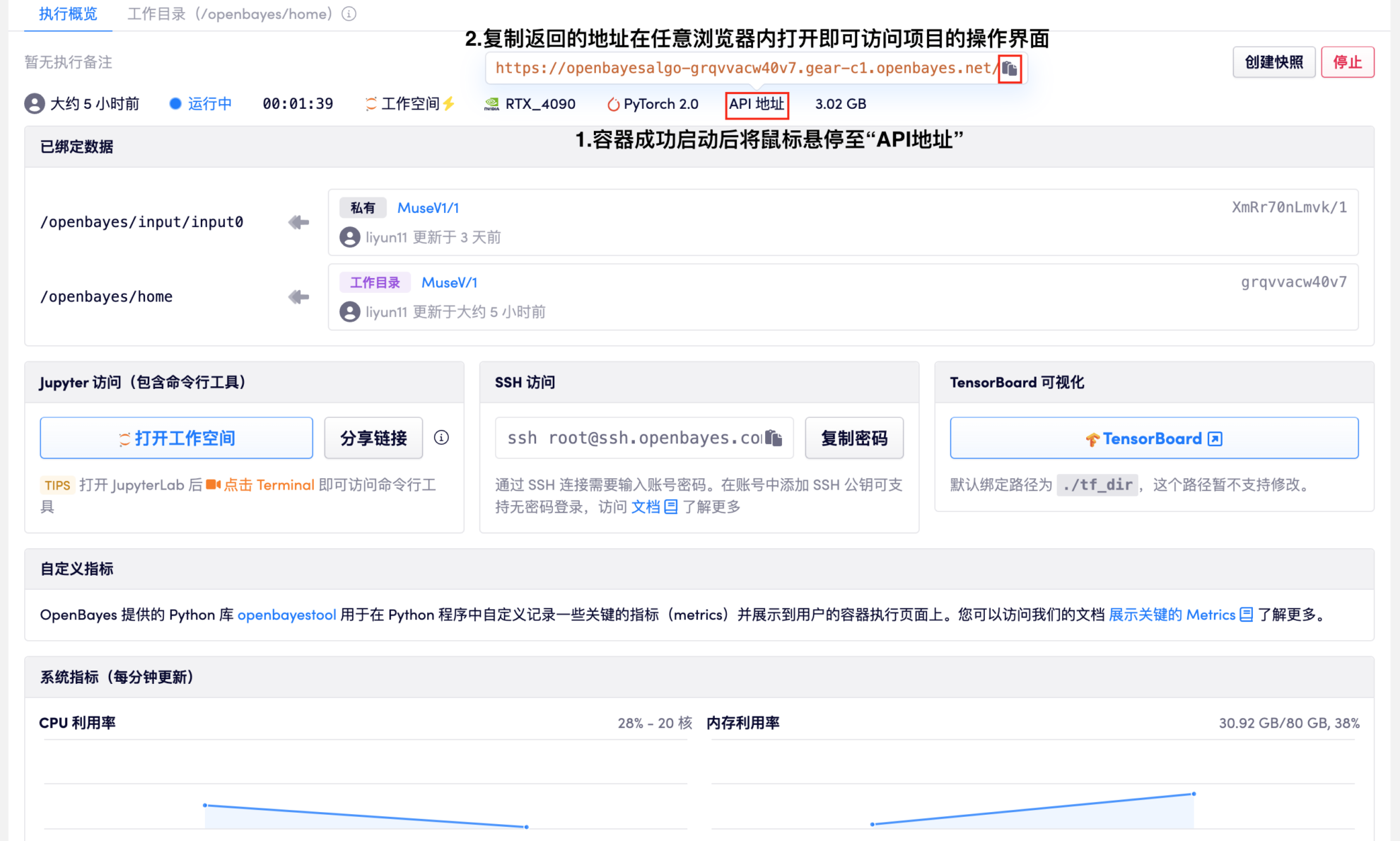
2. このページの使用方法は次のように説明されています。

交流とディスカッション
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。

このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。