Command Palette
Search for a command to run...
FLUX.1-schnell Vincent 画像デモ


チュートリアルの紹介
FLUX.1 は、テキストの説明から画像を生成できる 120 億個の大規模なパラメータ モデルです。テキストから画像への合成における画像の詳細、タイムリーなコンプライアンス、文体の多様性、およびシーンの複雑さの新しい最先端のレベルを定義します。 このチュートリアルでは、FLUX.1 [schnell] バージョンのモデルを使用します。このモデルと環境は、チュートリアルのガイドラインに従って推論ダイアログに直接使用できます。
モデルが大きいため、A6000 を使用して実行する必要があり、1 枚のカード 4090 を使用して起動することはできません。
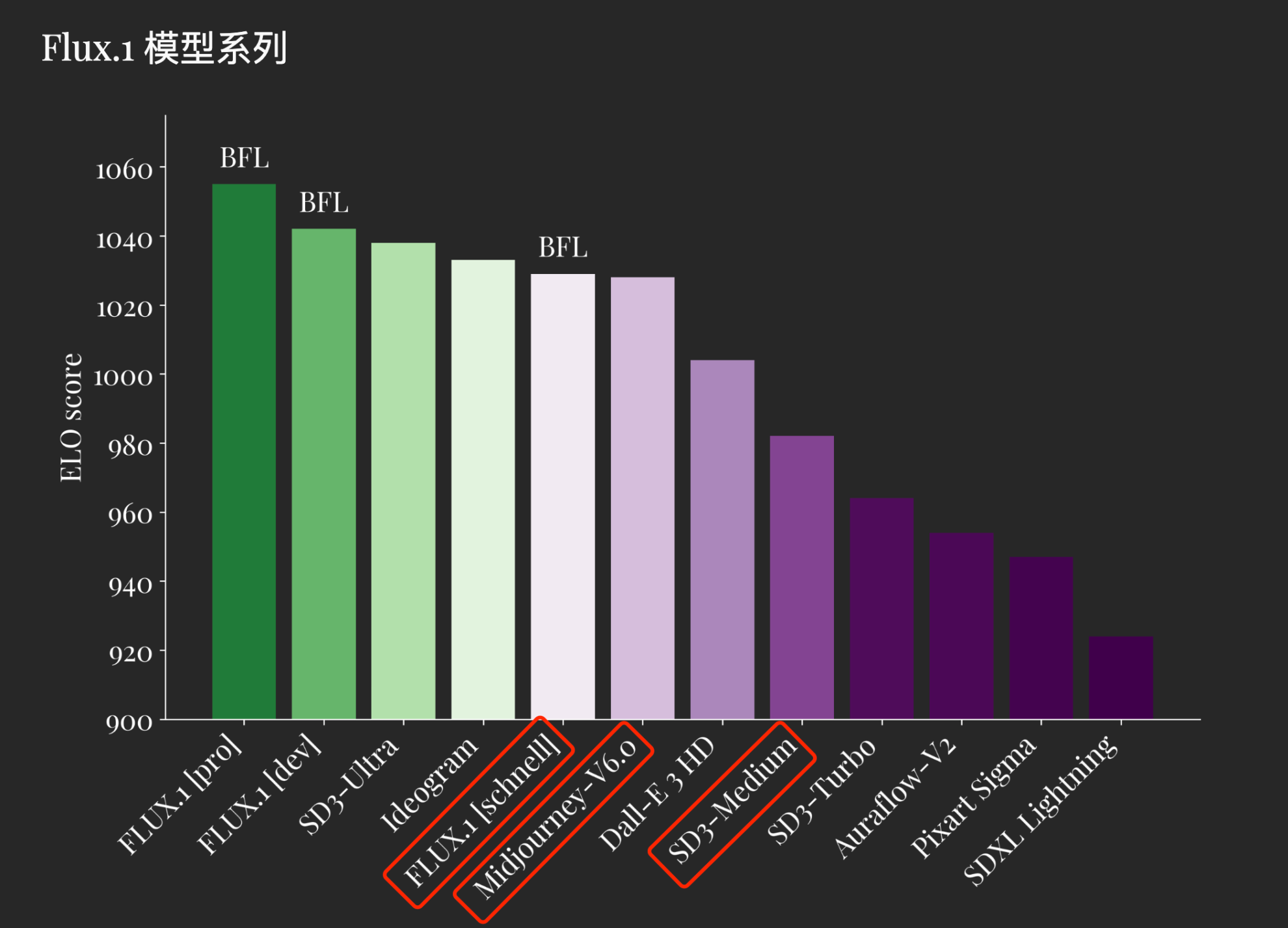
FLUX.1 は、画像合成における最先端技術を定義します。 FLUX.1 [pro] および [dev] は、ビジュアル品質、迅速なフォローアップ、サイズ/長さおよび幅の変更、植字と出力の多様性。 FLUX.1 [schnell] は、これまでで最も先進的な数ステップ モデルであり、競合他社だけでなく、Midjourney v6.0 や DALL・E 3 (HD) などの強力な非蒸留モデルをも上回ります。
アクセシビリティとモデルの機能のバランスをとるために、FLUX.1 は FLUX.1 [pro] 、 FLUX.1 [dev] 、および FLUX.1 [schnell] の 3 つのバージョンで利用できます。
FLUX.1 [pro]: FLUX.1 の最高の機能で、最高のインスタント トラッキング、ビジュアル品質、画像の詳細、出力の多様性を備えた最先端のパフォーマンス画像生成を実現します。商用目的ではないため、使用するには研究チームに連絡する必要があります。 FLUX.1 [dev]: FLUX.1 [dev] は、非商用アプリケーションに適した、オープンウェイトのガイド付きリファインメント モデルです。 FLUX.1 [dev] は FLUX.1 [pro] から直接派生し、同様の品質とタイムリーなコンプライアンスを提供しながら、同様のサイズの標準モデルよりも効率的です。 FLUX.1 [dev] ウェイトは HuggingFace で入手でき、Replicate または Fal.ai で直接試すことができます。商用目的ではありません。 FLUX.1 [schnell]: このモデルは、ローカル開発および個人使用向けに調整されています。 FLUX.1 [schnell] は、Apache 2.0 ライセンスに基づいて公開されています。
主な特長
- 最先端の出力品質と競争力のあるチップダウンで、クローズドソースの代替品のパフォーマンスに匹敵します。
- 潜在的な敵対的拡散蒸留を使用してトレーニングされた FLUX.1 [schnell] は、わずか 1 ~ 4 つのステップで高品質の画像を生成します。
- このモデルは、apache-2.0 ライセンスに基づいてリリースされており、個人、科学、商業目的で使用できます。
他のヴィンセントグラフモデルスコアとの比較
推論ステップをデプロイする
このチュートリアルでは、モデルと環境をデプロイしました。チュートリアルのガイドラインに従って、推論ダイアログに大規模なモデルを直接使用できます。具体的なチュートリアルは次のとおりです。
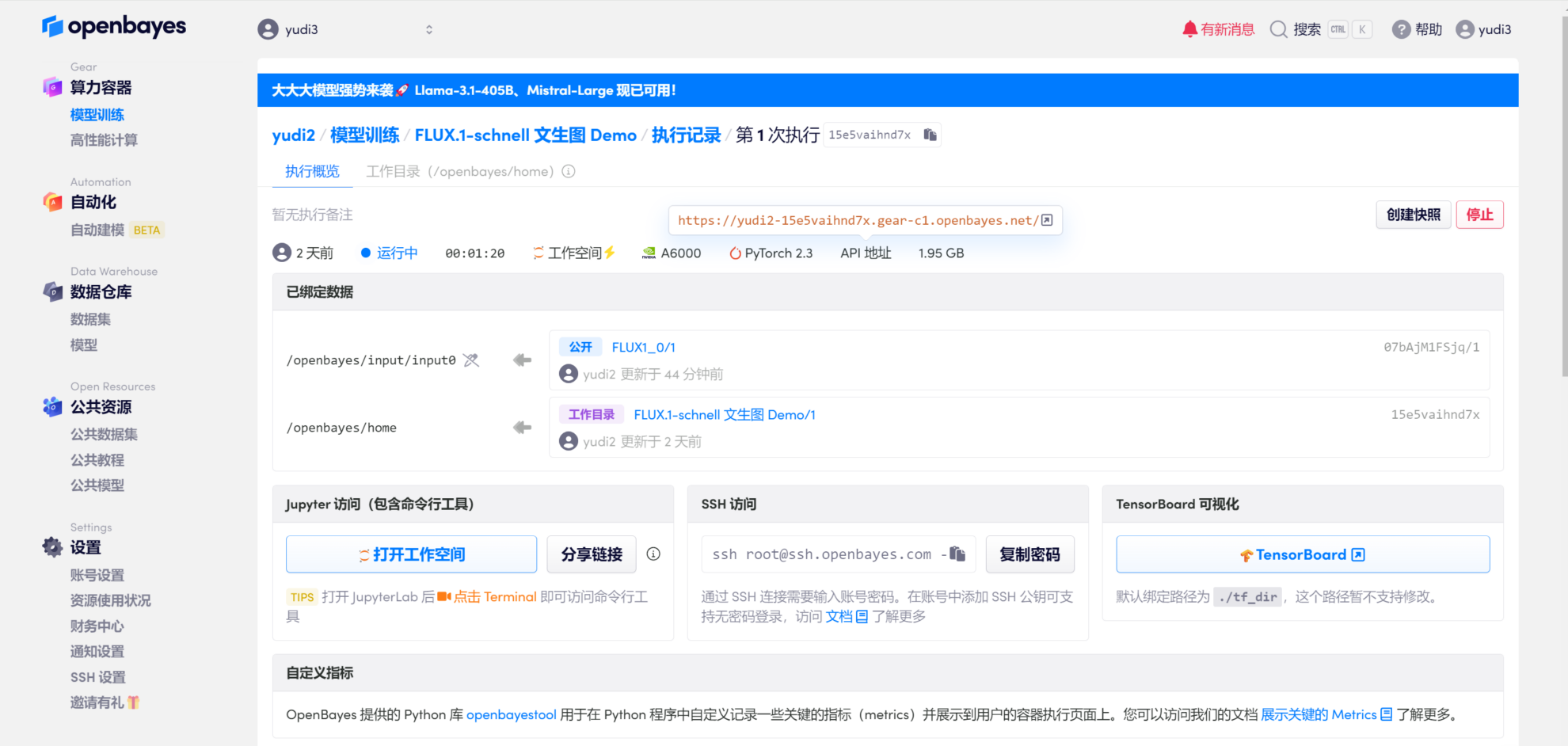
1.インターフェースを開きます
ページの右上隅にある「クローン」をクリックしてコンテナをクローンし、起動します。リソースを構成したら、コンテナを起動し、API アドレスのリンクを直接クリックしてデモ インターフェイスに入ります。
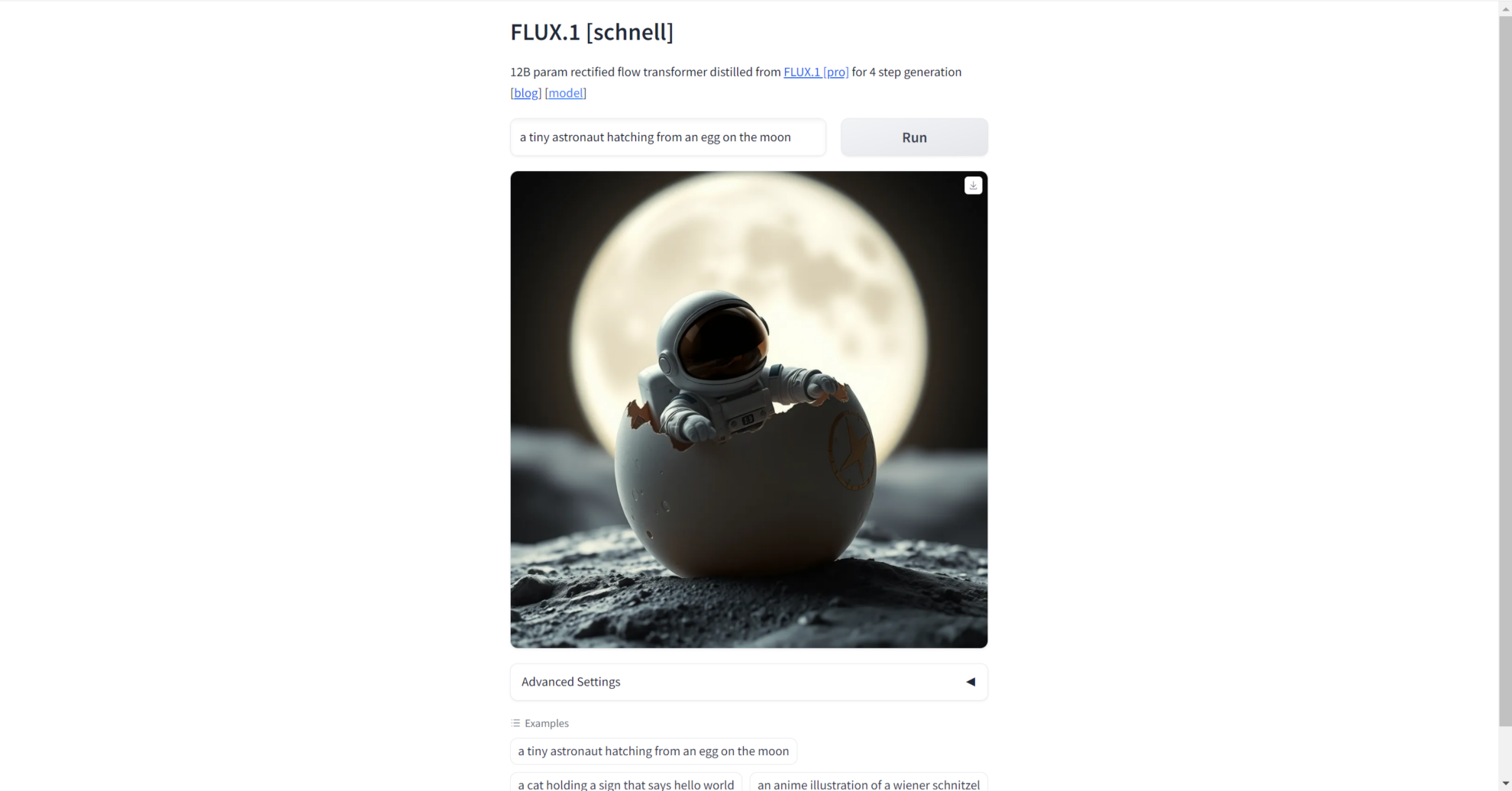
2. プロンプトの単語を入力します
インターフェイスを開いたら、画像を生成したいプロンプトの単語を入力して、対応する高品質の画像を生成できます。例の例を使用して検証することもできます。
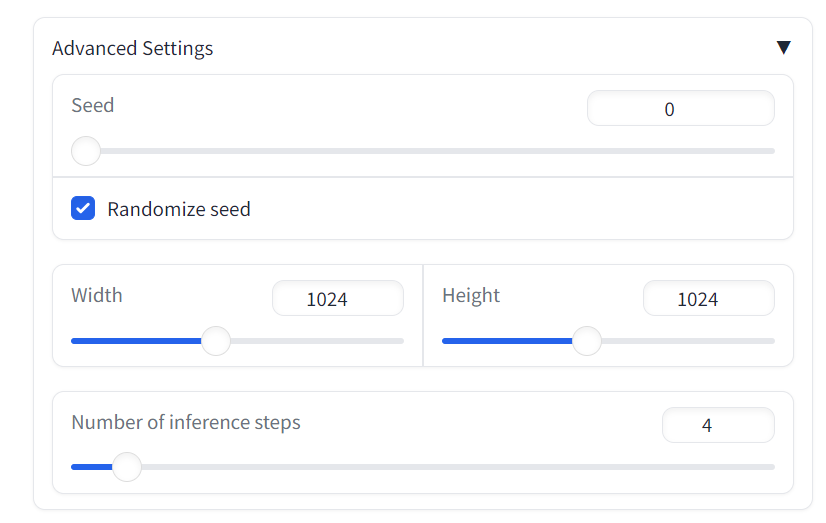
3.パラメータを変更する
モデルにはユーザーが調整できるパラメータが多数あります。モデルの推論ステップ数を個別に調整し、画像の長さや幅などのパラメーターを生成できます。
話し合ってコミュニケーションする
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しましたので、お友達がコードをスキャンしてメモを作成し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりするためにグループに参加することを歓迎します↓。 