Command Palette
Search for a command to run...
OVO-S-Bench: 多モーダルLLMにおけるストリーミング空間知能のための階層型ベンチマーク
OVO-S-Bench: 多モーダルLLMにおけるストリーミング空間知能のための階層型ベンチマーク
Yifei Li Pengyiang Liu Yuhang Zang Zhongyue Shi Qi Fu Hongye Hao Jiwen Lu
概要
ロボティクス、AR、自律走行におけるマルチモーダルagentsは、連続する自己中心ストリームから場所やレイアウトについて推論する必要があり、多くの場合、現在の視野外の証拠を用いる。既存のベンチマークは、完全な動画に対してオフラインで評価するか、空間構造ではなくイベントを対象としている。本研究では、ストリーミング空間知能のための完全な人間注釈付きベンチマークであるOVO-S-Benchを導入する。本ベンチマークは、348本のソース動画にわたる1,680の質問で構成されている。注釈作業には12名の訓練された注釈者が関与し、各々がブラインドクロスレビュアーも兼任した。これには、約804人時の多ラウンド品質保証が含まれる。各質問にはクエリタイムスタンプと証拠インターバルが付随しており、評価時にはモデルがクエリに先行するプレフィックスのみを入力として与えられる。質問は、即時の自己中心知覚、時空間文脈追跡、空間シミュレーションと推論、アロセントリックマッピングという、抽象度が段階的に高まる4つのレベルにわたっている。38の独自およびオープンソースのMLLMを対象とした評価において、Gemini-3.1-Proは人間専門家より27ポイント下回り(59.2対86.6)であり、アロセントリックマッピングが主要なボトルネックとなっている。注目すべきは、ストリーミング対応および空間的にファインチューニングされたMLLMが、そのバックボーンよりも性能が劣る点である。さらに、ストリームに grounding されていない場合、chain-of-thought推論が空間エラーを増幅することが判明した。これらの限界を明らかにすることで、OVO-S-Benchは次世代のストリーミング空間MLLMのための厳格なテストベッドを確立する。
One-sentence Summary
OVO-S-Bench is a fully human-annotated hierarchical benchmark that evaluates multimodal LLMs on streaming spatial intelligence by restricting model input to the video prefix preceding a query timestamp across four levels of increasing abstraction, thereby addressing the limitations of offline, event-focused datasets for robotics, AR, and autonomous driving applications.
Key Contributions
- OVO-S-Bench is introduced as a fully human-annotated benchmark for streaming spatial intelligence comprising 1,680 questions across 348 videos. Each question includes a query timestamp and evidence interval, enforcing a strict prefix-only viewing constraint during evaluation while spanning four abstraction levels from instantaneous egocentric perception to allocentric mapping.
- Evaluation across 38 proprietary and open-source multimodal large language models reveals that Gemini-3.1-Pro trails human experts by 27 points, with allocentric mapping serving as the primary bottleneck. The results further demonstrate that streaming and spatial fine-tuning can degrade performance relative to base backbones.
- Analysis of reasoning mechanisms indicates that chain-of-thought prompting amplifies spatial errors when models lack grounding in the continuous video stream. These findings establish a rigorous testbed that directs future research toward more robust streaming spatial multimodal large language models.
Introduction
Object-level change detection requires systems to compare spatial states across different observation times and identify additions, removals, movements, or alterations. This capability is essential for applications like autonomous navigation, video surveillance, and environmental monitoring, where accurately tracking state transitions over time directly informs downstream decision-making. Prior models typically struggle with this task because they lack reliable mechanisms to retain and align prior visual states with current observations, often defaulting to simple present-frame enumeration rather than performing true temporal reasoning. To address this limitation, the authors formalize object-level change detection as a core spatiotemporal consistency verification task. They introduce a structured evaluation protocol that explicitly distinguishes cross-time comparison from static scene understanding, enabling precise measurement of how well models remember and contrast visual information across temporal sequences.
Dataset

Dataset Composition and Sources
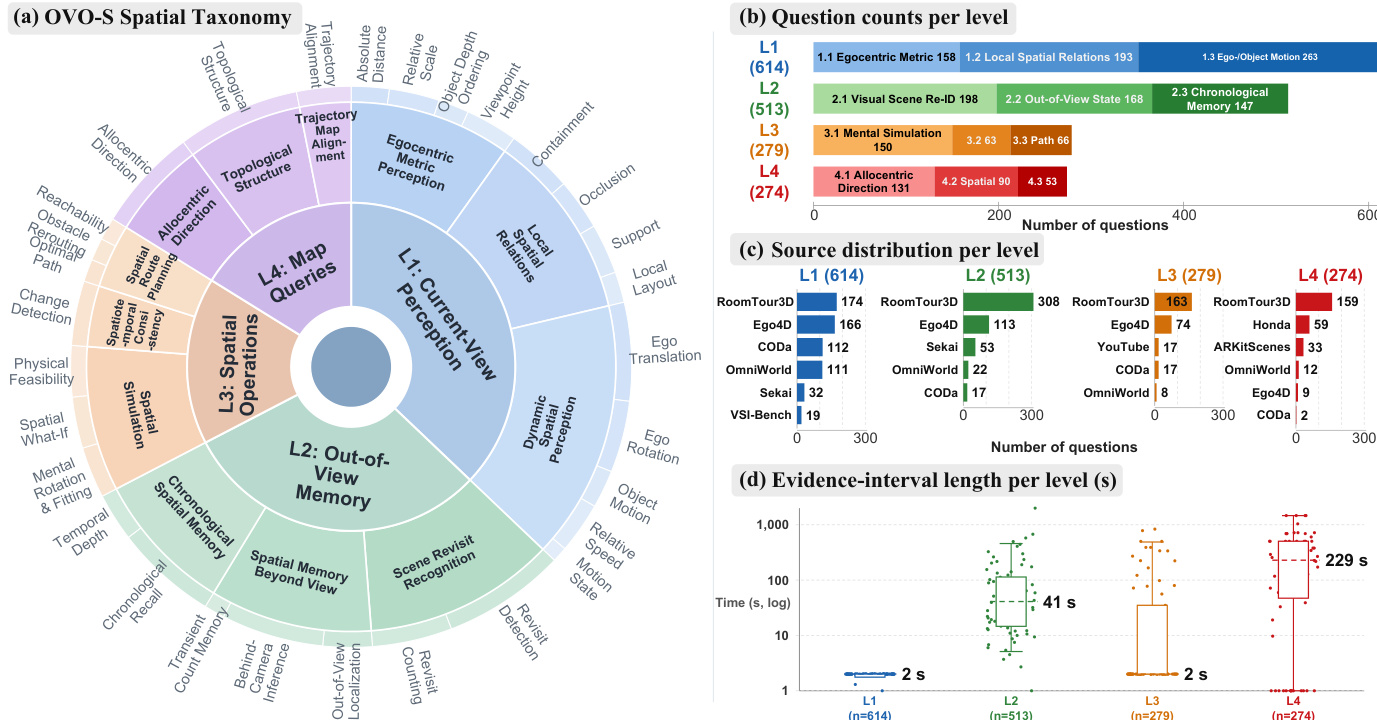
- The authors introduce OVO-S-Bench, a fully human-annotated benchmark containing 1,680 questions distributed across 348 source videos.
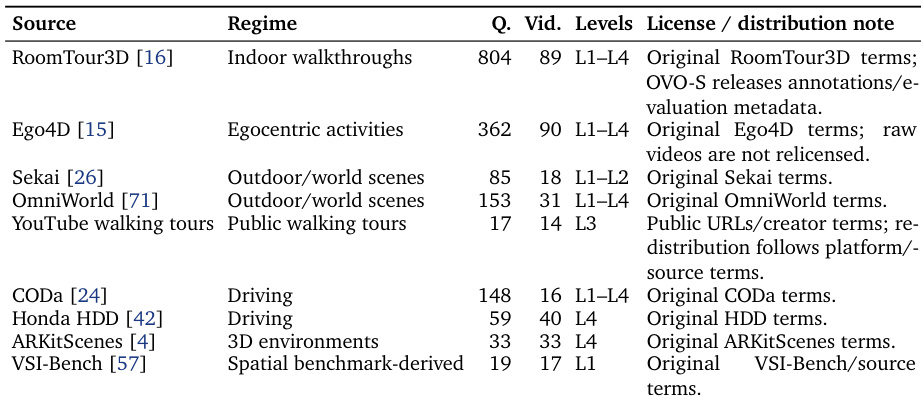
- The videos are sourced from nine publicly accessible datasets spanning five distinct regimes: indoor walkthroughs, egocentric daily activities, outdoor and world scenes, autonomous driving footage, and spatially annotated 3D environments.
- Annotation was conducted by twelve trained volunteers with backgrounds in 3D computer vision, accumulating approximately 804 person-hours of work.
Subset Details and Taxonomy
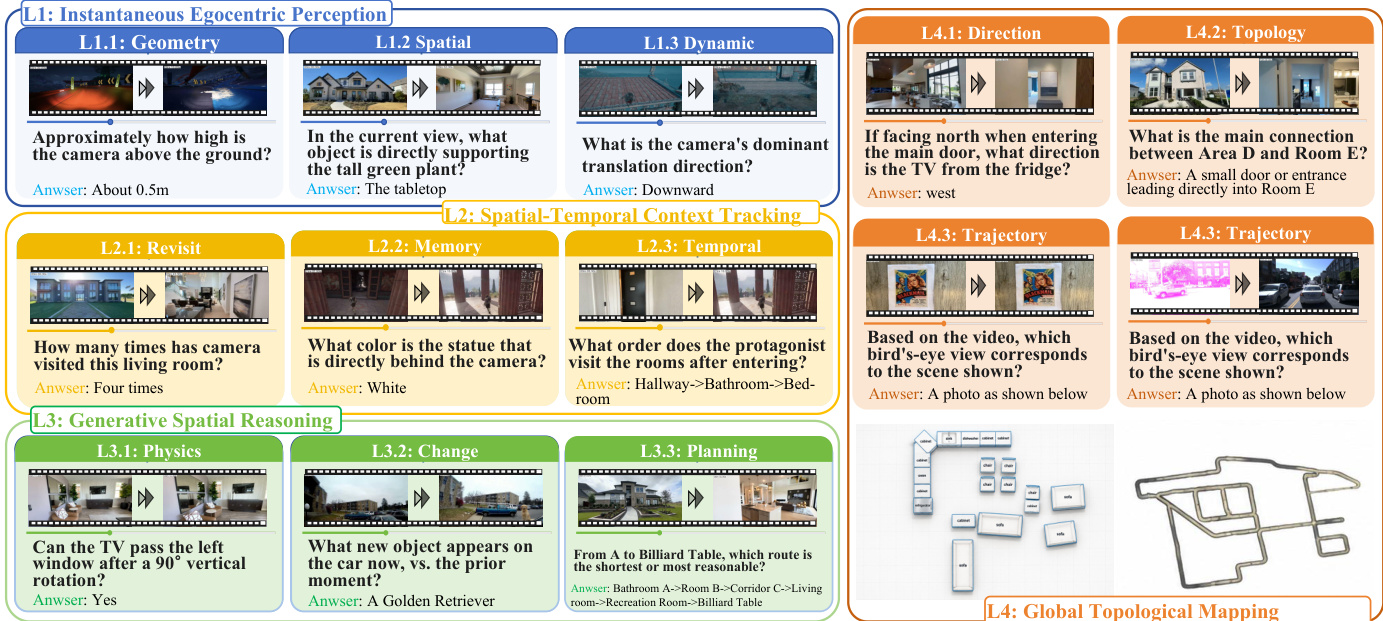
- The dataset is organized into four hierarchical levels of spatial abstraction, each containing specific task families and totaling thirty canonical task types.
- Level one focuses on instantaneous egocentric perception, requiring answers from frames immediately surrounding the query point.
- Level two tests spatiotemporal context tracking, where evidence appeared earlier in the video but is no longer visible at query time.
- Level three demands spatial simulation and reasoning, including mental rotation, hypothetical state changes, and route planning.
- Level four requires allocentric spatial mapping, forcing the model to integrate multiple viewpoints into a global topological representation or match trajectories to bird's-eye maps.
- The mean video prefix length at query time is 8.8 minutes, with evidence intervals scaling significantly from level one to level four.
Data Usage and Evaluation Protocol
- The authors use this dataset strictly for evaluation rather than model training, establishing a strict streaming protocol where models only receive the video prefix preceding the designated query timestamp.
- The benchmark evaluates thirty-eight multimodal and video foundation models, including proprietary systems, general backbones, and architectures specifically fine-tuned for streaming or spatial tasks.
- Each question is designed to be uniquely answerable from the visual prefix, with distractors carefully crafted to remain visually plausible while preventing resolution through language patterns or world knowledge.
Processing, Metadata, and Quality Control
- The authors construct a strict temporal split using query timestamps and evidence intervals, ensuring all supporting visual cues appear strictly before the model is evaluated.
- A multi-stage filtering pipeline removes shortcut vulnerabilities by running a text-only language model probe, followed by blind cross-review from a second annotator and adjudication by senior researchers.
- Specialized construction techniques are applied to higher levels, including generative image editing for consistency checks, standardized named-entity labeling for unviewed rooms, and automated bird's-eye view rendering for map alignment tasks.
- The final dataset is released as a single JSONL file containing structured metadata for each item, including video paths, temporal markers, task categories, and aligned answer keys, with frame extraction reserved solely for offline analysis and error categorization.
Method
The authors present a comprehensive framework for evaluating spatial reasoning in video understanding models, structured around a four-level taxonomy of spatial abstraction: L1 (Instantaneous Egocentric Perception), L2 (Spatial-Temporal Context Tracking), L3 (Generative Spatial Reasoning), and L4 (Global Topological Mapping). Each level represents a distinct cognitive and computational challenge, with L1 focusing on immediate visual perception from a first-person perspective, L2 requiring the retention of spatiotemporal facts after visual support is lost, L3 involving mental simulation of spatial changes or hypothetical scenarios, and L4 demanding the construction of an allocentric (viewer-independent) map of the environment. The framework is designed to enforce a streaming protocol, where models are only allowed to access video content up to the query timestamp, simulating real-time, causal reasoning from an egocentric video stream.
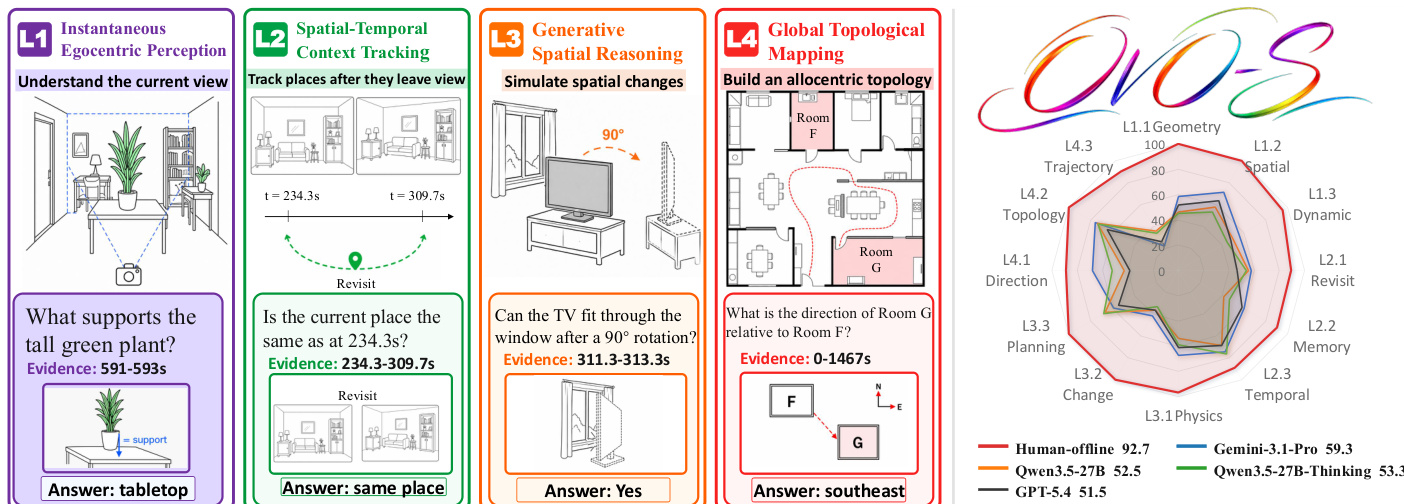
The overall architecture of the benchmark is visualized in the framework diagram, which illustrates the progression from L1 to L4. At the L1 level, the task is to understand the current view, such as identifying what supports a visible object. The L2 level introduces the challenge of tracking spatial context over time, for instance, determining if a location remains the same after a period of absence. The L3 level requires simulating spatial changes, like predicting whether an object can fit through a doorway after a rotation. Finally, the L4 level demands global topological mapping, such as inferring the directional relationship between rooms in an allocentric layout. This hierarchy ensures a systematic evaluation of spatial reasoning capabilities, from immediate perception to complex, integrated world modeling.
The model's interaction with the video stream is governed by a frame-sampling policy that determines which frames are consumed. The policy must adhere to a prefix-only constraint, meaning only frames preceding the query time are accessible. The authors consider several sampling strategies, including a naive baseline that uses only the query frame, a nearest-16f@4fps policy that samples frames from a causal sliding window, and a uniform sampling policy that distributes frames evenly across the prefix. An oracle policy, which is not available at deployment, allocates the frame budget exclusively within annotated evidence intervals to establish an upper bound on performance. Additionally, a log-decay-128 policy implements a recency-weighted schedule, allocating more frames to the most recent time intervals, thereby modeling a coarse exponential prior of near-importance without ground-truth evidence. This sampling mechanism ensures that the model must reason from a constrained, streaming input, mimicking real-world scenarios.
The evaluation framework is designed to address three structural gaps in existing benchmarks: the lack of a streaming protocol in spatial benchmarks, the limited focus on spatial structure in streaming benchmarks, and the absence of the L4 allocentric-mapping level in prior video benchmarks. By enforcing a streaming protocol at the item granularity, the benchmark ensures that evidence is ephemeral and must be reasoned about in real-time. The source videos cover a diverse range of domains, including indoor walkthroughs, outdoor footage, and 3D-rendered environments, providing a comprehensive test bed. The tasks are stratified into the four levels of spatial abstraction, with the previously untested L4 level annotated using named-entity, bird's-eye, and topological supervision, enabling the first empirical test of whether spatial reasoning gaps observed under offline access persist or worsen under causal streaming conditions.
Experiment
The evaluation tests 38 multimodal systems under a strict streaming protocol that restricts visual input to the prefix preceding the query, benchmarking them against human experts and text-only controls to isolate genuine spatial reasoning capabilities. Benchmarking validates a substantial performance gap driven by an allocentric mapping bottleneck that resists scaling and specialized training, while chain-of-thought analysis confirms that explicit reasoning aids cross-frame integration but frequently introduces grounding errors. Further experiments demonstrate that advanced frame-sampling and memory-compression strategies fail to consistently improve performance, indicating that the deficit stems from fundamental reasoning and persistent state limitations rather than contextual retrieval or architectural specialization.
The the the table compares the performance of various models on a video understanding task, focusing on overall accuracy and per-level accuracy across four difficulty levels. Specialized methods, including spatially fine-tuned, streaming, and memory-compression models, generally underperform their base models, with the most significant drops observed on higher-level tasks requiring allocentric mapping. The results highlight a consistent performance gap between models and human experts, particularly on the most complex level, and show that even advanced techniques like chain-of-thought reasoning offer limited gains on certain tasks. Specialized methods consistently underperform their base models, with the largest drops on the highest-level task requiring allocentric mapping. Chain-of-thought reasoning provides modest gains on mid-level tasks but offers little benefit for current-view perception. The performance gap between models and human experts remains substantial, especially on the most complex level, indicating a fundamental challenge in spatial reasoning from streaming video.
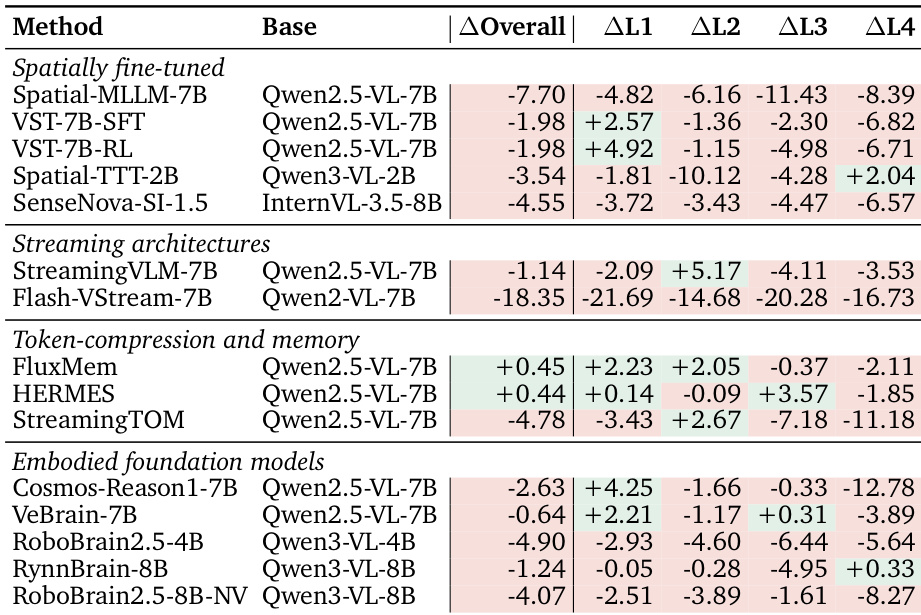
The authors evaluate a range of models on a video understanding task using a standardized streaming protocol, comparing performance across different models and configurations. Results show that while some models achieve high accuracy on certain metrics, there is a significant gap between human performance and the best-performing models, with a notable performance drop at the allocentric mapping level. The evaluation highlights that specialized methods and thinking modes do not consistently improve performance, and that model performance is influenced by the complexity of the spatial reasoning required. Performance varies significantly across models, with the best models achieving high accuracy on certain metrics but still falling short of human performance. A substantial performance drop occurs at the allocentric mapping level, indicating a bottleneck in spatial reasoning. Specialized methods and thinking modes do not consistently outperform their base models, suggesting that current approaches are not fully effective in addressing the core challenges of the task.
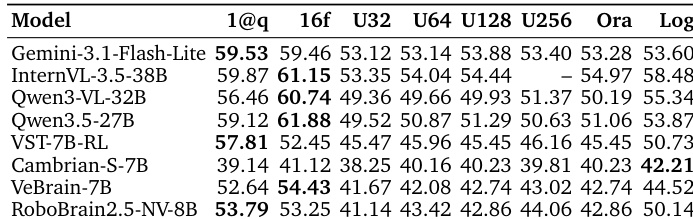
The authors evaluate a range of models on a spatial reasoning benchmark, focusing on their performance across different levels of spatial understanding. The results show that models struggle with allocentric mapping tasks, which require integrating information from a broader visual context, and that specialized methods do not consistently outperform their base backbones. Additionally, the gap between model performance and human performance remains significant, particularly on complex tasks requiring long-range spatial reasoning. Models show a significant performance gap on allocentric mapping tasks compared to simpler egocentric perception tasks. Specialized methods for streaming or memory compression do not consistently improve overall accuracy over their base backbones. The performance of models remains substantially below human levels, especially on tasks requiring long-range spatial reasoning.
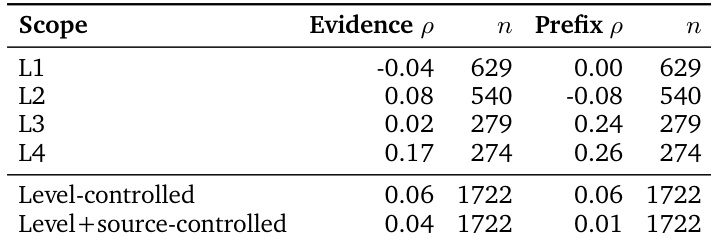
The the the table presents Spearman correlation coefficients between query-level mean accuracy and evidence-span duration, as well as prefix duration, under different control conditions. The correlations are small and not statistically significant, indicating that longer evidence spans or prefixes do not consistently predict lower accuracy. The results suggest that the difficulty of higher-level tasks, particularly allocentric mapping, is not driven by the length of the input but by the complexity of the spatial reasoning required. Correlations between accuracy and evidence-span or prefix duration are weak and not statistically significant. The allocentric mapping bottleneck is not explained by input length but by the complexity of spatial reasoning. The small positive correlation between evidence span and accuracy contradicts the hypothesis that longer inputs are harder to process.
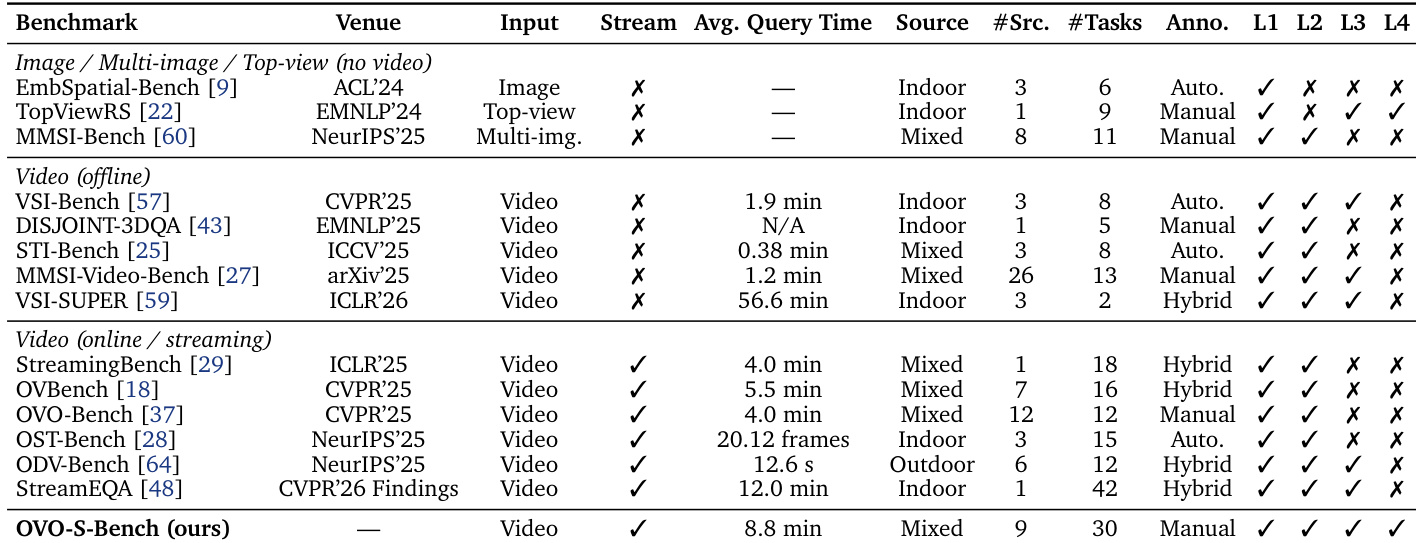
The authors evaluate a range of multimodal models on a video understanding task using a streaming protocol that limits access to frames before a query timestamp. Results show a significant performance gap between human experts and the best models, with the strongest systems still falling short on allocentric mapping tasks. The evaluation highlights that specialized methods and thinking modes do not consistently improve accuracy, and the bottleneck in spatial reasoning appears to stem from the need to abstract long-range spatial relationships rather than from limited memory or frame access. Human performance significantly exceeds the best model accuracy, especially on allocentric mapping tasks. Specialized models and thinking modes fail to outperform their base backbones, indicating a lack of improvement from current design strategies. The primary bottleneck in spatial reasoning is not frame retention or sampling but the ability to abstract long-range spatial relationships across the video prefix.
The experiments evaluate multimodal models on a video understanding benchmark using a streaming protocol that restricts frame access to a query timestamp, systematically assessing performance across escalating spatial reasoning difficulties. The results validate that specialized architectural modifications and chain-of-thought reasoning consistently fail to outperform base models, particularly on allocentric mapping tasks that demand long-range visual integration. Furthermore, the analysis confirms that task difficulty stems from the inherent complexity of abstracting spatial relationships rather than limitations in memory capacity or input length. Ultimately, these findings highlight a fundamental bottleneck in current architectures, as models remain substantially behind human experts in handling complex spatial reasoning from streaming video.