Command Palette
Search for a command to run...
MUSE-Autoskill: スキルの作成、記憶、管理、評価による自己進化的エージェント
MUSE-Autoskill: スキルの作成、記憶、管理、評価による自己進化的エージェント
Huawei Lin Peng Li Jie Song Fuxin Jiang Tieying Zhang
概要
大規模言語モデル(LLM)エージェントは、複雑なタスクを解決するために再利用可能なスキルに依存している。しかし、既存のスキル作成アプローチは、スキルを孤立かつ静的なアーティファクトとして扱うため、その再利用性、信頼性、長期的な改善が制限されている。我々は、スキルセントリックなエージェントフレームワークである MUSE-Autoskill Agent(Memory-Utilizing Skill Evolution)を提案する。このフレームワークでは、エージェントは統一的なライフサイクル(作成、記憶、管理、評価、改善)の下で、スキルを作成し、再利用し、改善することにより、タスク解決能力を継続的に向上させることができる。本フレームワークにより、エージェントは必要に応じてスキルを作成し、タスク間でそれらを保存および再利用し、効率的に整理および選択し、ユニットテストやランタイムフィードバックを通じて評価して継続的に改善することが可能となる。さらに、各スキルにわたる経験を蓄積し、時間の経過とともにより効果的な再利用と適応を可能にするスキルレベルの記憶(skill-level memory)を導入する。SkillsBench 上での実験は、ライフサイクル管理されたスキルがタスクの成功、効率、再利用、およびエージェント間転送を向上させることを示す初期証拠を提供しており、スキルを経験を備え、テスト可能で、長寿命なアセットとして扱うことの重要性を浮き彫りにしている。
One-sentence Summary
MUSE-Autoskill is a self-evolving agent framework that addresses the limitations of isolated and static skills through a unified lifecycle of creation, memory, management, evaluation, and refinement, leveraging skill-level memory and evaluation via unit tests and runtime feedback to enable continuous improvement, with SkillsBench experiments demonstrating improved task success, efficiency, reuse, and cross-agent transfer.
Key Contributions
- The paper introduces MUSE-Autoskill Agent, a training-free framework that unifies skill creation, memory, management, evaluation, and refinement into a single lifecycle.
- This approach incorporates skill-level memory to accumulate per-skill experience across tasks and uses unit-test-driven evaluation to automatically trigger refinement when tests fail.
- Experiments on SkillsBench demonstrate that lifecycle-managed skills improve task success and efficiency while empirically validating cross-agent skill transfer without modification.
Introduction
Large language model agents require reusable skills to handle complex real-world tasks, but current methods often treat these capabilities as isolated and static artifacts. This approach limits reliability because prior systems lack structured memory for individual skills and omit rigorous validation through unit tests. The authors introduce MUSE-Autoskill, which unifies the skill lifecycle through creation, memory management, evaluation, and refinement. Their framework leverages skill-level memory to accumulate experience and automated testing to trigger continuous self-improvement. Consequently, agents can achieve higher task success rates and transfer validated skills across different systems without additional training.
Dataset
-
Dataset Composition and Sources
- The authors construct a dataset comprising agent skills and execution trajectories from the MUSE-Autoskill runtime.
- Skills are stored as self-contained directories compatible with Anthropic's Agent Skills format.
- Trajectories are recorded within per-session workspaces created for each task invocation.
-
Key Details for Each Subset
- Skills: Each entry is a directory rooted at a kebab-case name containing a
SKILL.mdfile. The file requires YAML frontmatter with a name and description. Optional subdirectories include scripts, tests, and resources, though documentation-only skills are the dominant pattern. - Sessions: Every task creates a directory named with a UUID-like string under the agent home directory. This workspace holds instruction prompts, submitted inputs, output artifacts, and log streams.
- Events: The
events.jsonlfile captures a strictly ordered stream of every plan, action, and observation.
- Skills: Each entry is a directory rooted at a kebab-case name containing a
-
Data Usage in the Model
- The authors use the
events.jsonlstream for reproducibility and analysis in Appendix H. - The
ctx_state.jsonfile serializes the conversation DAG to support cross-session resume mechanisms. - Metadata such as
run_meta.jsonrecords reward, turn count, and model details.
- The authors use the
-
Processing and Metadata Construction
- All memory files use a plain Markdown format with append-only blocks for long-term, short-term, and per-skill contexts.
- Sandbox execution isolates processes by routing uploads to
/sandbox/inputs/and outputs to/sandbox/outputs/. - Skill identity relies on redundant naming where the directory name must match the frontmatter name field.
Method
The MUSE-Autoskill Agent operates as a skill-centric framework designed to solve complex tasks through the dynamic creation, reuse, and refinement of skills. The system integrates skill creation, execution, memory management, and evaluation within a unified agent loop.
The overall architecture is organized into four primary components: Skill Creation, Skill Management, Self-Evolution and Correction, and a Memory Mechanism.
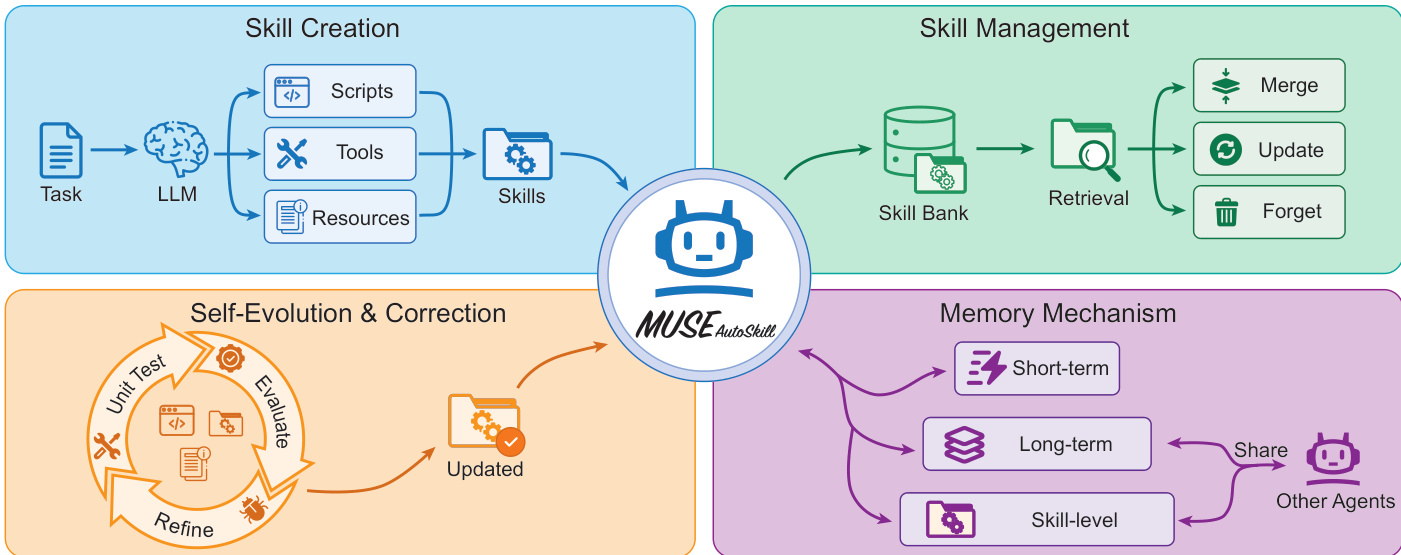
Skill Creation allows the agent to generate new capabilities when existing ones are insufficient. Skill Management handles the retrieval, merging, updating, and forgetting of skills stored in a Skill Bank. The Self-Evolution module ensures quality through unit testing and refinement loops. Finally, the Memory Mechanism maintains short-term, long-term, and skill-level memory to support context retention and knowledge accumulation.
The end-to-end workflow is driven by a Master Agent running a ReAct loop, interacting with a Skill Subsystem.
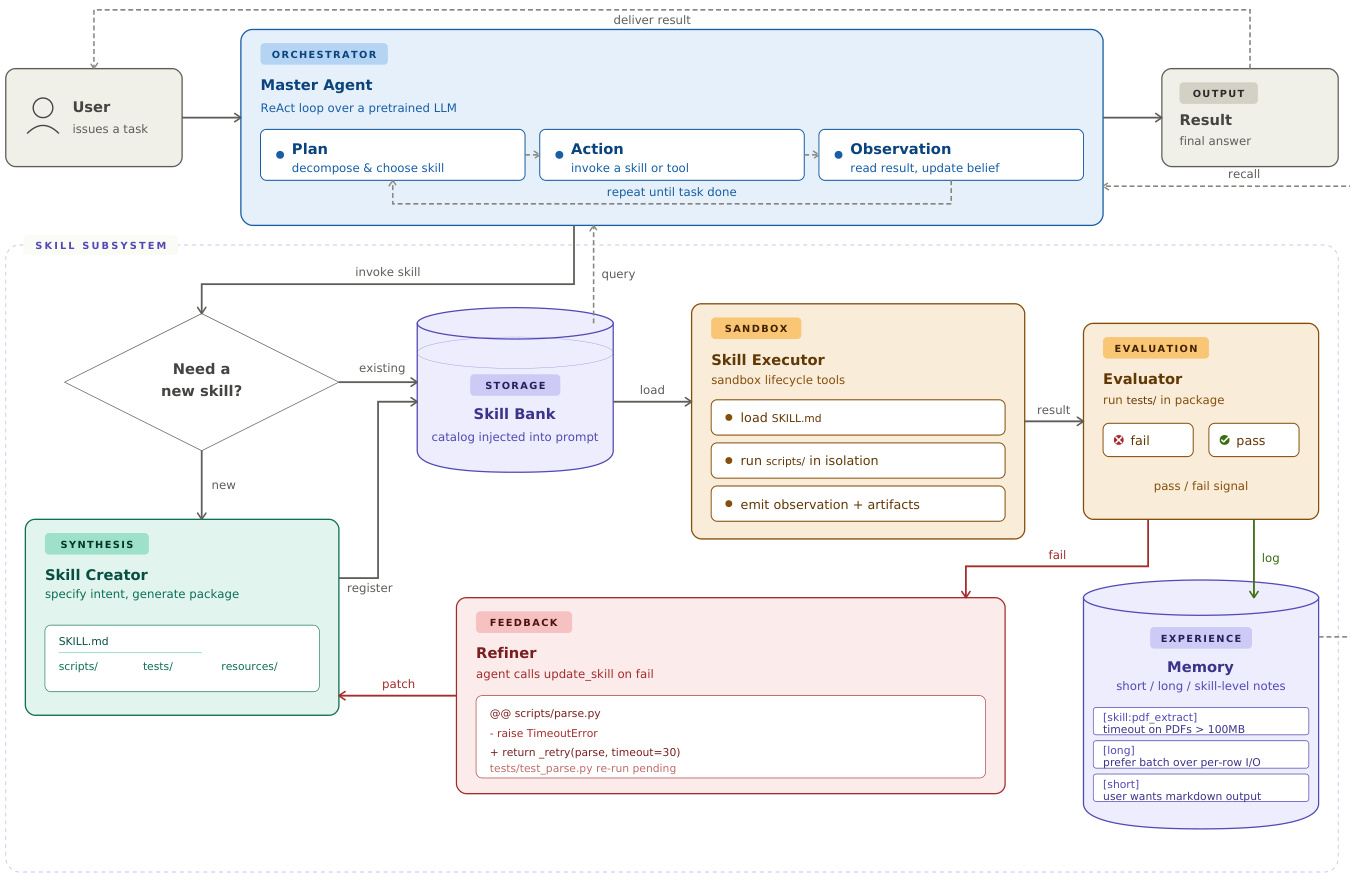
When a user issues a task, the Master Agent enters a cycle of Planning, Action, and Observation. During the Planning stage, the agent decomposes the problem and decides whether to invoke an existing skill or create a new one. If a new skill is required, the system dispatches the Skill Creator to synthesize a package containing a SKILL.md definition, executable scripts, and unit tests. This package is then subjected to an Evaluation phase within a sandbox environment. If the tests pass, the skill is registered in the Skill Bank and observations are logged to Memory. If the tests fail, a Refiner module patches the code based on error feedback, and the cycle repeats until the skill is validated.
To manage context limits during long-horizon tasks, the agent employs an adaptive context compression strategy over a Directed Acyclic Graph (DAG) of conversation turns.
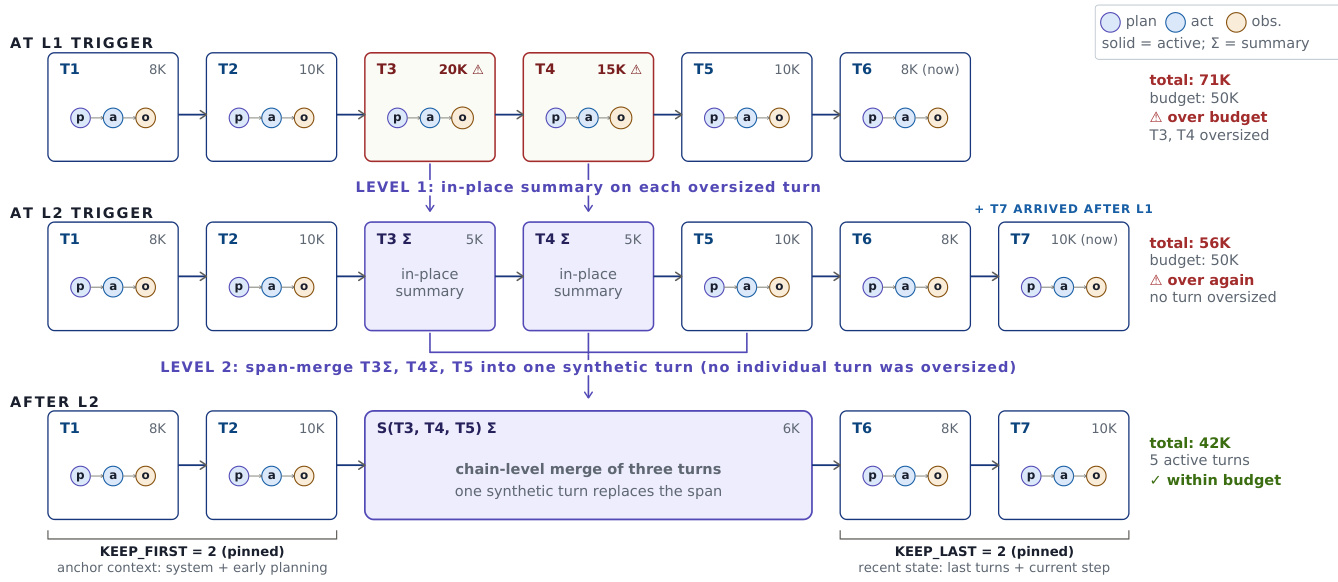
The system maintains a history where the first K and last K turns are pinned to preserve system instructions and recent state. When the total token count exceeds a budget, Level 1 compression triggers an in-place summary of individual oversized turns. If the budget is still exceeded, Level 2 compression merges a contiguous span of intermediate turns into a single synthetic summary node. This hierarchical approach ensures that the active chain remains within the model's context window while preserving the full history for replayability and analysis.
Experiment
Evaluated on the SkillsBench benchmark, the framework demonstrates that skill usage substantially improves agent performance across different system designs while establishing that MUSE-Autoskill integrates this content more effectively than baseline models. Automatic skill generation successfully distills high-quality knowledge from successful trajectories that often surpasses human-authored references and transfers seamlessly to other agent architectures without modification. These generated skills achieve Pareto-optimal outcomes by simultaneously increasing task accuracy and reducing computational costs compared to both baseline and human skill conditions.
The authors evaluate three agents on a benchmark of 51 tasks to measure the impact of using human-authored skills versus relying on base knowledge. Results indicate that providing skills significantly boosts performance across all tested systems. MUSE-Autoskill demonstrates superior capability in leveraging these skills to achieve the highest overall accuracy. Every agent shows a marked improvement in task completion rates when equipped with human-authored skills. MUSE-Autoskill consistently secures the top performance ranking across both experimental conditions. The introduction of skills yields a comparable relative gain for all agents, highlighting the universal value of the mechanism.

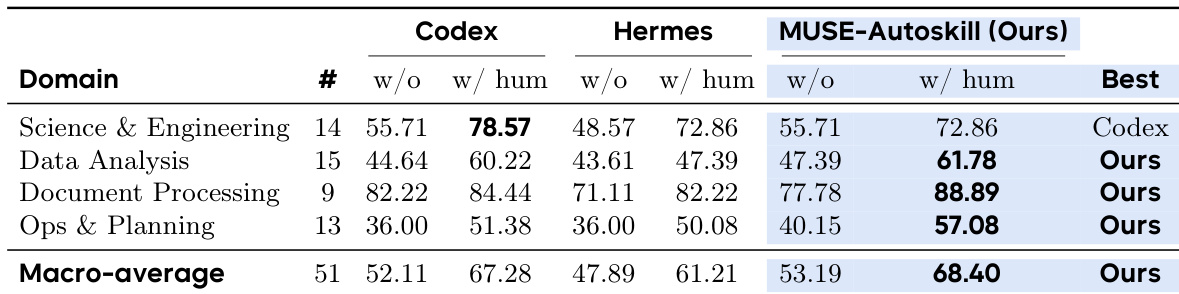
The authors evaluate three agents on a benchmark of tasks spanning four domains, comparing performance without skills versus with human-authored skills. Results show that human skills consistently improve accuracy for all agents, with the proposed MUSE-Autoskill framework achieving the highest macro-average score in both conditions. The proposed method outperforms baseline agents in the majority of tested domains, specifically excelling in data analysis, document processing, and operations planning. Human skills consistently improve accuracy for all evaluated agents. MUSE-Autoskill achieves the highest macro-average performance with human skills. The proposed method leads in three out of four domain categories.
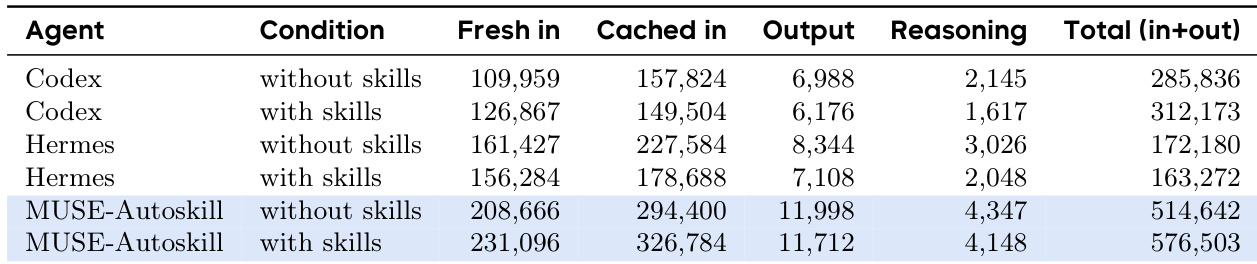
The the the table compares token usage across three agents, showing that MUSE-Autoskill consumes significantly more tokens than Codex and Hermes due to deeper reasoning loops. While prompt caching accounts for a majority of input tokens for all systems, the impact of adding human skills varies by agent, increasing costs for MUSE-Autoskill and Codex but reducing them for Hermes. MUSE-Autoskill demonstrates the highest overall token consumption, utilizing substantially more input tokens than the other agents in both skill conditions. Prompt caching absorbs a significant portion of the input load, handling roughly half of the total input tokens across all agents and configurations. Adding human skills results in divergent efficiency trends, increasing total token usage for MUSE-Autoskill and Codex while reducing it for Hermes.
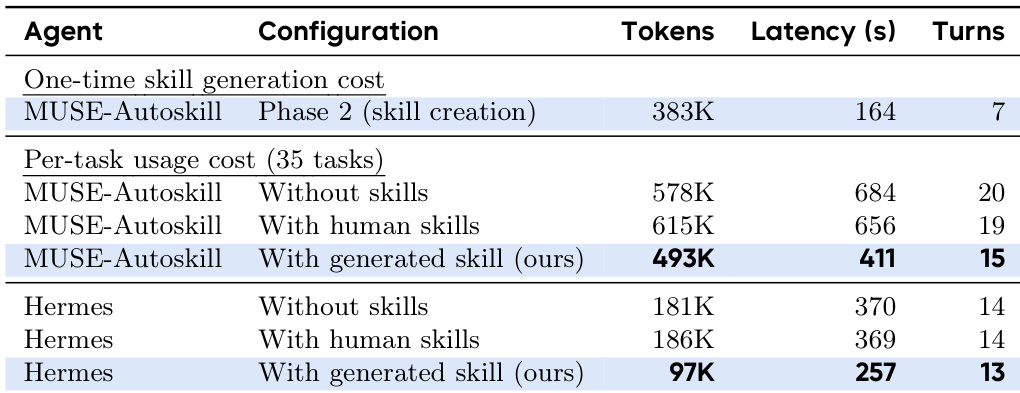
The the the table compares the computational costs of skill generation and usage for MUSE-Autoskill and Hermes agents across different configurations. It shows that while generating a skill incurs a one-time cost, using the resulting generated skill is more efficient than relying on human skills or no skills. Both agents achieve lower token usage, reduced latency, and fewer interaction turns when utilizing the automatically generated skills. Generated skills result in lower token consumption and latency compared to human skills. The framework reduces the number of turns required to complete tasks. The upfront cost of skill creation is outweighed by efficiency gains during usage.
The authors evaluate three agents on a benchmark of 51 tasks to assess the impact of skill usage and automatic generation. Results indicate that MUSE-Autoskill achieves the highest overall performance, while all agents demonstrate substantial improvements when utilizing human-authored skills. Furthermore, skills generated automatically by MUSE-Autoskill successfully transfer to other agents, significantly boosting their accuracy and approaching the performance levels seen with human skills. MUSE-Autoskill consistently outperforms Codex and Hermes across baseline and skill-assisted conditions. All agents experience substantial accuracy gains when utilizing human-authored skills compared to using no skills. Skills generated automatically by MUSE-Autoskill transfer successfully to Hermes, significantly boosting its performance.
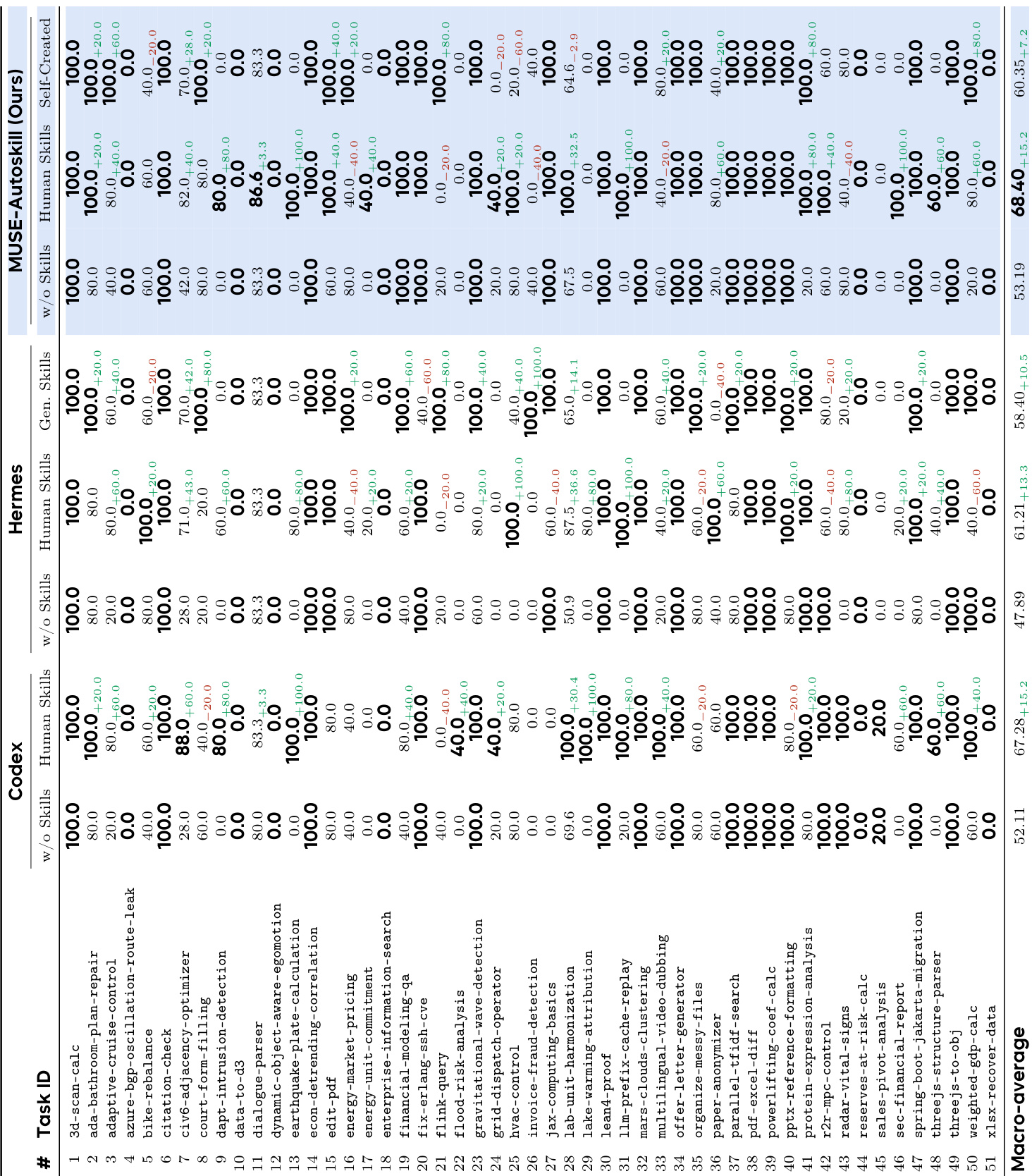
The authors evaluate three agents across multiple domains to measure the impact of using human-authored versus automatically generated skills on task performance. Results indicate that equipping agents with skills significantly boosts accuracy for all systems, with MUSE-Autoskill consistently achieving the highest overall performance. Additionally, automatically generated skills prove efficient by reducing latency and interaction turns compared to human skills and successfully transfer to other agents, although MUSE-Autoskill incurs higher overall token usage due to deeper reasoning.