Command Palette
Search for a command to run...
MuseV のワンクリックデプロイ
概要
One-sentence Summary
The authors propose S2VG, a training-free framework that leverages off-the-shelf monocular video generators to produce 3D stereoscopic and spatial videos through denoising frame matrix inpainting augmented by disocclusion boundary re-injection, yielding significant improvements over prior methods across evaluations on videos from Sora, Lumiere, WALT, and Zeroscope.
Key Contributions
- Introduces a pose-free and training-free framework that repurposes off-the-shelf monocular video generation models to synthesize immersive 3D and stereoscopic videos. The method eliminates explicit camera pose estimation and fine-tuning to directly convert standard monocular outputs into multi-view spatial content adaptable to stereoscopic pairs or 4D Gaussians.
- Proposes a novel frame matrix inpainting framework that warps generated monocular frames into predefined viewpoints using estimated depth information to synthesize missing content across spatial and temporal dimensions. This pipeline integrates a disocclusion boundary re-injection scheme and an outpainting-then-inpainting design to resolve occlusion artifacts and preserve complete object structures.
- Validates the approach through experiments on outputs from Sora, Lumiere, WALT, and Zeroscope, demonstrating consistent improvements in spatial-temporal consistency and visual quality over existing stereoscopic and spatial video synthesis techniques.
Introduction
The rapid advancement of VR and AR applications has created a strong demand for high-fidelity stereoscopic and spatial videos that maintain strict geometric and temporal coherence across multiple viewpoints. While monocular video generation has progressed significantly, existing 3D synthesis techniques primarily rely on reconstruction-based novel view synthesis, which suffers from unstable camera pose estimation and an inability to realistically synthesize occluded or disoccluded regions. To overcome these limitations, the authors present a pose-free and training-free framework that repurposes off-the-shelf monocular video diffusion models for immersive 3D content creation. Their approach warps initial frames into virtual viewpoints and introduces a frame matrix representation to jointly refine spatial and temporal consistency during the denoising process. Furthermore, they implement a disocclusion boundary re-injection scheme to eliminate latent-space artifacts and optimize the generated sequences into dynamic 4D Gaussians, enabling seamless novel-view synthesis without requiring explicit camera pose tracking.
Method
The proposed method for stereoscopic and spatial video generation operates as a training-free pipeline that leverages an off-the-shelf depth estimator and a pretrained monocular video diffusion model. The framework begins with the generation of a monocular video for the left view using a video diffusion model, conditioned on a text prompt or a single image. To produce the corresponding right view while maintaining 3D consistency, the system first estimates depth from the left view video. This depth information is then used to perform stereoscopic warping, generating an initial right view sequence and its associated disocclusion masks. The disoccluded regions are subsequently completed through a diffusion-based inpainting process, which synthesizes plausible content to yield the final right-view video.
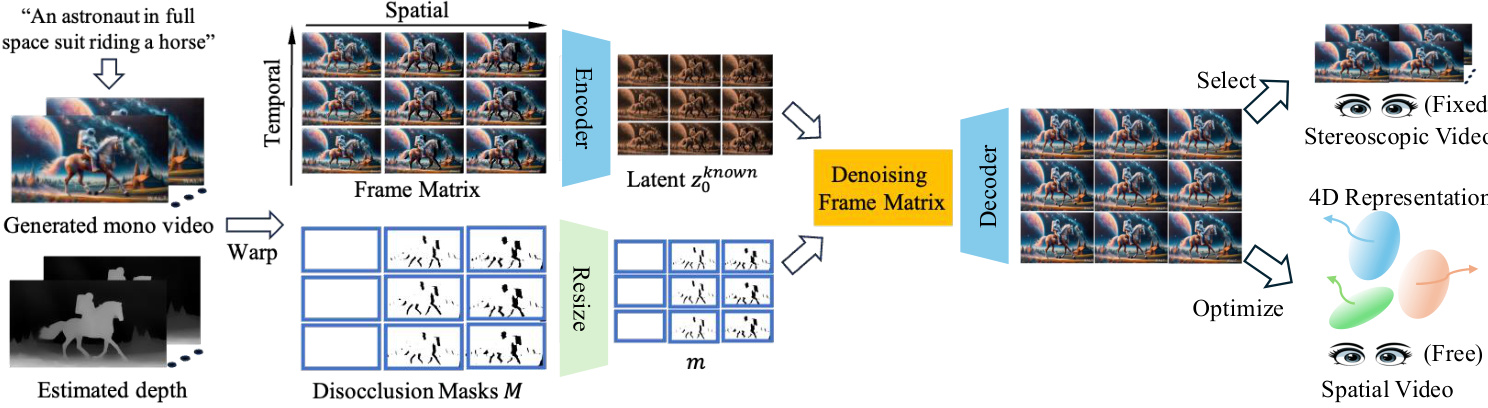
The core of the framework is a novel frame matrix representation designed to enhance both spatial/semantic coherence and temporal consistency. This representation structures the warped video frames into a two-dimensional array, where each row corresponds to multiple camera perspectives captured at the same timestamp, and each column represents a temporal sequence of frames from a fixed camera viewpoint. This structure enables the joint denoising of both spatial and temporal sequences. The denoising process is performed in an alternating manner, extending a resampling mechanism to denoise column sequences (temporal) and row sequences (spatial) multiple times. At each denoising step, the latent features of the known regions are preserved while the unknown regions are denoised using the video diffusion model. This iterative process ensures that the generated content is consistent across both space and time.

To address artifacts introduced by the warping process, such as isolated pixels and cracks, the method employs a multi-plane projection technique. This approach partitions the camera view space into discrete planes stratified by depth, which naturally separates foreground and background elements. Isolated pixels are detected and removed by convolving the mask images with a 3times3 kernel, while cracks are identified and filled using local pixel interpolation. The processed planes are then composited into a final warped image through back-to-front blending. For cases where the monocular video contains partially visible objects, a video outpainting step is applied to extend the visible content before warping.
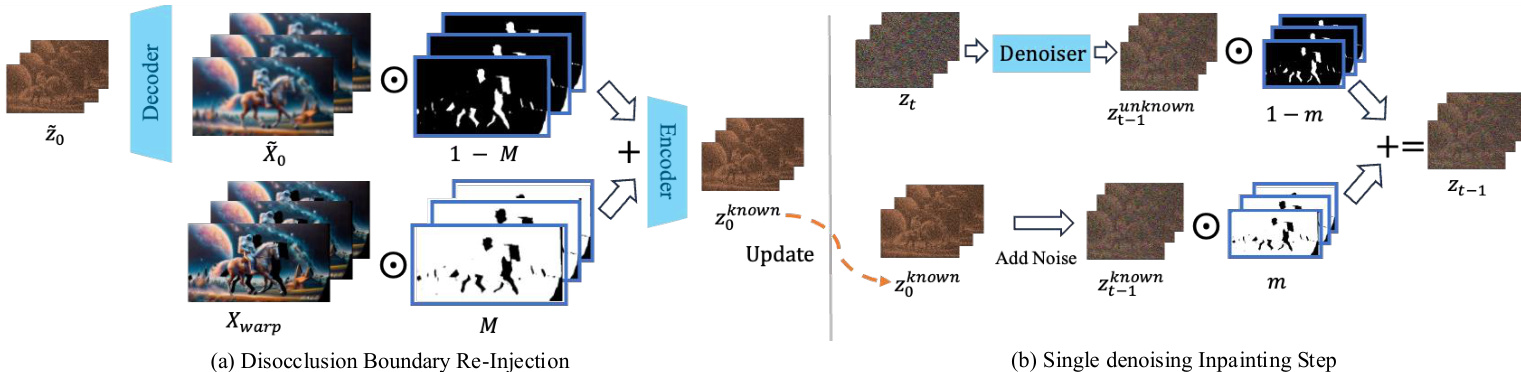
A critical component for improving the quality of the inpainted results is the disocclusion boundary re-injection mechanism. This strategy addresses the issue of feature corruption at the boundary of the disoccluded regions, which occurs due to the downsampling of the latent features by the VAE encoder. The method predicts denoised latent features, decodes them into a video, and then replaces the unoccluded regions with the warped pixels. The resulting composite video is re-encoded to obtain an updated latent representation, which is used in the subsequent denoising iterations. This refinement step significantly reduces artifacts and enhances the fidelity of the generated content.
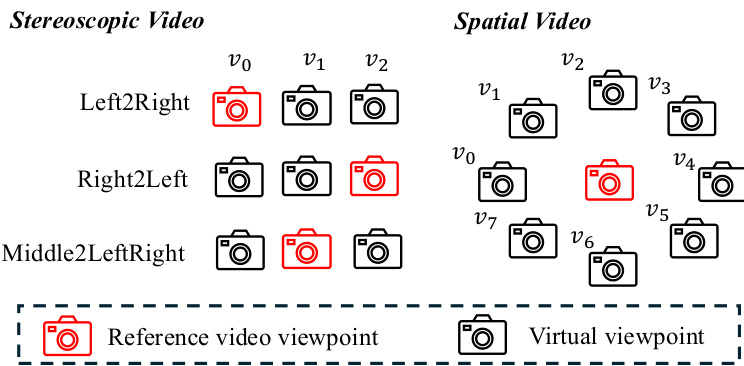
Finally, the framework extracts stereoscopic and spatial videos from the inpainted frame matrix. For stereoscopic video, the leftmost and rightmost columns of the frame matrix are selected to represent the left and right eye views, respectively. For spatial video, which supports continuous viewpoint changes, the generated multi-view observations are optimized into a 4D representation, specifically using Deformable Gaussian Splatting. This optimization process learns a set of 3D Gaussians in a canonical space, with their positions and appearances modeled as dynamic entities using time-dependent offsets, enabling continuous and consistent view synthesis.
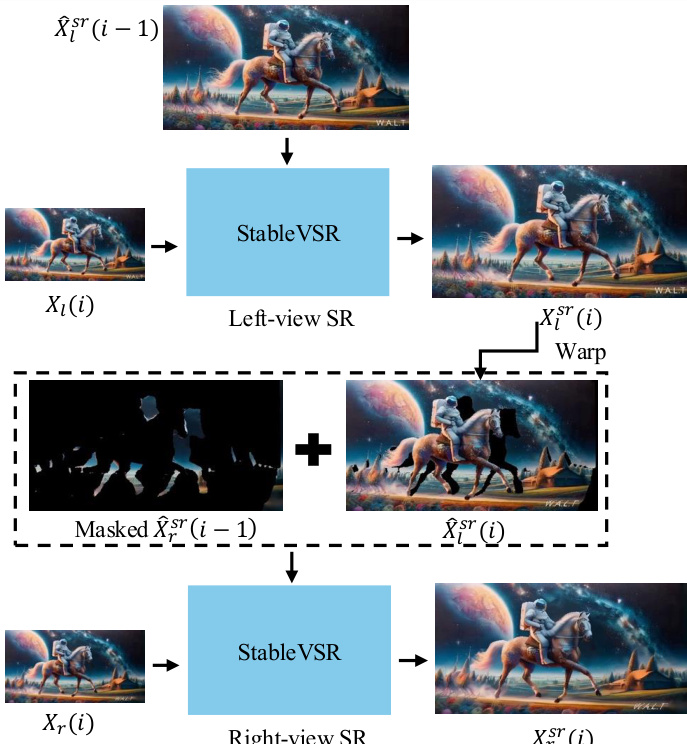
An optional stereo video super-resolution scheme is also implemented. This pipeline uses a pre-trained monocular video super-resolution model. The left-view video is upsampled using a temporal condition from the previous upsampled frame to ensure inter-frame consistency. The right-view upsampling, in contrast, incorporates both a temporal condition and a cross-view condition from the upsampled left-view frame to maintain stereo coherence. This approach ensures that the final stereoscopic video is both temporally stable and spatially coherent.
Experiment
The evaluation setup tests the proposed method against multiple video inpainting, novel view synthesis, and stereo-specific baselines across both stereoscopic and spatial video generation tasks. Qualitative assessments reveal that the approach consistently generates sharp, temporally coherent content in disoccluded regions, effectively overcoming the blurry artifacts, pose instability, and view inconsistencies that limit existing techniques, while ablation studies confirm that key components like the frame matrix and depth smoothing are critical for maintaining semantic alignment. Ultimately, the method proves highly effective at producing realistic stereoscopic and 4D videos without relying on explicit camera poses or rigid stereo constraints.
The authors conduct experiments to evaluate their method for generating stereoscopic and spatial videos, comparing it against various baselines including video inpainting and novel view synthesis approaches. Results show that their method outperforms existing methods in terms of semantic consistency, video quality, and human perception, particularly in maintaining temporal coherence and producing sharp, plausible content in disoccluded regions. The effectiveness of key components such as the frame matrix and disocclusion boundary re-injection is validated through ablation studies. The proposed method achieves superior performance in semantic consistency and video quality compared to baseline methods, as demonstrated by higher scores in CLIP feature similarity and aesthetic metrics. Ablation studies confirm that the frame matrix and disocclusion boundary re-injection are critical for maintaining semantic coherence and producing high-quality results in disoccluded regions. The method outperforms existing approaches in human perception evaluations, showing better stereo effects, temporal consistency, and overall experience, especially when compared to single-image view synthesis and video inpainting baselines.

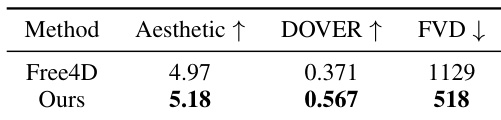
The authors conduct a comparative evaluation of their method against a baseline approach in spatial video generation, focusing on video quality metrics. Results show that their method achieves superior performance across all measured metrics, indicating higher aesthetic quality, better video consistency, and improved generation fidelity compared to the baseline. The evaluation is based on rendering videos from optimized 4D scenes and assessing them using established quantitative measures. The proposed method outperforms the baseline in all evaluated metrics for spatial video generation. The method achieves higher aesthetic quality and video consistency compared to the baseline. The results demonstrate improved video fidelity as measured by the FVD metric.
The authors conduct a comprehensive evaluation of their method against multiple baselines in stereoscopic video generation, using both human perception studies and objective metrics. Results show that their approach outperforms existing methods in key aspects such as stereo effect, temporal consistency, and overall experience, while also achieving superior semantic alignment and video quality. The method demonstrates robustness across different configurations and effectively maintains coherence in both spatial and temporal domains. The proposed method achieves the highest scores across all human perception metrics, including stereo effect, temporal consistency, image quality, and overall experience. The method outperforms baselines in semantic consistency and video quality, as measured by CLIP feature similarity and established metrics like aesthetic score, DOVER, and FVD. Ablation studies confirm the importance of key components such as frame matrix, disocclusion boundary re-injection, and warping processing for maintaining coherence and reducing artifacts.

The authors evaluate their stereoscopic and spatial video generation method against multiple baseline approaches through comparative analysis and human perception studies. These experiments validate the model's capacity to maintain strong semantic alignment, temporal coherence, and realistic stereo effects while effectively reconstructing disoccluded regions. Ablation studies further confirm that specific architectural components, particularly the frame matrix and disocclusion boundary re-injection, are critical for preserving visual consistency and reducing artifacts. Overall, the approach consistently outperforms existing techniques by delivering superior aesthetic quality and a more immersive viewing experience.