Command Palette
Search for a command to run...
動画吹き替えのための長さ認識型音声翻訳
動画吹き替えのための長さ認識型音声翻訳
Harveen Singh Chadha Aswin Shanmugam Subramanian Vikas Joshi Shubham Bansal Jian Xue Rupeshkumar Mehta Jinyu Li
Linly 吹き替えのワンクリックデプロイ:ワンクリック動画ダウンロード+翻訳+吹き替え+字幕
概要
動画吹き替えにおいて、翻訳された音声と元の音声を同期させることは重要な課題である。本研究の焦点は、リアルタイムかつデバイス上での動画吹き替えシナリオに適応した効率的な同期の実現にある。私たちは、事前定義されたタグを用いて、短、標準、長の3種類の異なる長さの翻訳を生成する音素ベースのエンドツーエンドの長さ感知型音声翻訳(LSST)モデルを開発した。さらに、単一のデコーディングパスで異なる長さの翻訳を生成する効率的な手法である長さ感知ビームサーチ(LABS)を導入した。このアプローチは、長さ感知を備えていないベースラインと比較して同等のBLEUスコアを維持しつつ、ソース音声とターゲット音声の同期品質を大幅に向上させ、スペイン語では平均意見点(MOS)が0.34、韓国語では0.65それぞれ向上した。
One-sentence Summary
The authors propose a phoneme-based end-to-end length-sensitive speech translation (LSST) model for real-time, on-device video dubbing that employs predefined length tags and a length-aware beam search (LABS) decoder to generate short, normal, and long translations in a single pass, maintaining comparable BLEU scores to a baseline without length awareness while achieving mean opinion score synchronization gains of 0.34 for Spanish and 0.65 for Korean.
Key Contributions
- A phoneme-based Length-Sensitive Speech Translation (LSST) model generates short, normal, and long candidate translations using predefined length tags. This phoneme-based length ratio method provides a consistent and scalable representation for cross-lingual duration modeling.
- A Length-Aware Beam Search (LABS) decoding strategy produces varying-length translations within a single decoding pass. This approach eliminates the computational overhead of multiple decoding iterations, significantly reducing latency and system complexity for real-time on-device deployment.
- The framework maintains comparable BLEU scores to standard baselines while substantially improving audio synchronization. The method achieves mean opinion score gains of 0.34 for Spanish and 0.65 for Korean, confirming its effectiveness for temporally aligned video dubbing.
Introduction
End-to-end speech-to-text translation has become essential for automatic video dubbing, a technology that significantly improves global content accessibility. Successful dubbing demands precise temporal alignment between source and target audio, but speech duration naturally varies across languages, often causing mismatched pacing and unnatural delivery. Prior length-control methods typically rely on text-to-text translation, character-based modeling that lacks cross-lingual consistency, or multi-pass decoding strategies that introduce unacceptable latency for real-time, on-device deployment. To overcome these hurdles, the authors introduce a Length-Sensitive Speech Translation framework paired with Length-Aware Beam Search, which efficiently generates short, normal, and long translation candidates in a single decoding pass using phoneme-based length ratios to ensure accurate and fluid temporal alignment.
Method
The authors leverage a phoneme-based end-to-end length-sensitive speech translation (LSST) model designed to generate translations of varying lengths—short, normal, and long—tailored for real-time, on-device video dubbing scenarios. The core of the approach lies in conditioning the translation process on predefined length control tokens: <short>, <normal>, and <long>. These tokens are prepended to each target translation during training, replacing the standard Start of Sequence (SOS) token. The assignment of a length tag is determined by the ratio of the target-to-source text length, computed using phoneme counts to ensure cross-lingual consistency. Specifically, the length tag ℓ is assigned as follows:
where r denotes the target-to-source length ratio and α=0.1. Phoneme-based length computation is preferred over character-based methods, particularly when dealing with languages using different writing systems such as English and Korean, due to structural differences in orthography that make character counts less reliable for duration estimation.
During inference, the LSST model can generate multiple length variants by conditioning on the respective length token. However, generating all three variants independently is computationally expensive. To address this, the authors introduce the length-aware beam search (LABS) algorithm, which enables the efficient generation of all length variants in a single decoding pass.

As shown in the figure below: the LABS algorithm modifies standard beam search by initializing the beam with the length-specific tokens L={s,n,l}, corresponding to <short>, <normal>, and <long>. At each time step t, the algorithm expands the beam by generating new hypotheses for each length tag ℓ∈L, extending each hypothesis b in the length-specific sub-beam Bt(ℓ) with every token v in the target vocabulary V. The set of new hypotheses for each length tag is given by:
where ⊕ denotes token appending and St+1(ℓ) is the updated score of the extended hypothesis, calculated as:
St+1(ℓ)=St(ℓ)+logP(v∣b,ℓ,x)The complete beam at time step t+1 is formed by the union of all length-specific sub-beams:
Bt+1=ℓ∈L⋃Bt+1(ℓ)Pruning is performed in a length-aware manner to maintain diversity while controlling beam size. The pruning function Prune(Bt+1,N,L) selects the top-N hypotheses from the combined beam Bt+1, ensuring that at least one hypothesis from each length tag is preserved, if available. The selection process prioritizes high-scoring hypotheses while enforcing diversity across length categories. Specifically, the top three hypotheses from each length tag are included, and the remaining N−3 candidates are selected based on score. If fewer than N hypotheses exist across all tags, all are retained. Additionally, hypotheses that have reached the End-of-Sequence token ⟨EOS⟩ are given priority to ensure complete translations are considered in the final candidate set.
The algorithm iterates through steps of beam expansion and pruning until a maximum length T is reached or all hypotheses have generated ⟨EOS⟩. The final n-best list H^ is selected from the set of completed hypotheses Bfinal using a selection function SelectNBest(Bfinal,N,L), which ensures representation from each length tag if possible, while ranking primarily by score. This approach enables efficient generation of multiple length variants in a single decoding pass, facilitating synchronization with the source audio duration without compromising translation quality.
Experiment
The evaluation setup employs a multilingual speech-to-text model trained on Spanish and Korean data, assessed via the FLEURS test set to measure translation quality and temporal alignment. The first set of experiments validates phoneme-based length tokens as an effective unit for regulating output duration while preserving translation fidelity. The second set of experiments validates the LABS decoding strategy, demonstrating substantial gains in speech rate compliance and perceived synchronization without compromising fluency or introducing significant latency. Collectively, these findings confirm that integrating length-aware decoding with phoneme-based controls produces more natural, well-timed translations that closely match source audio pacing.
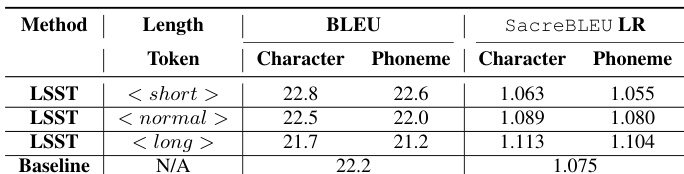
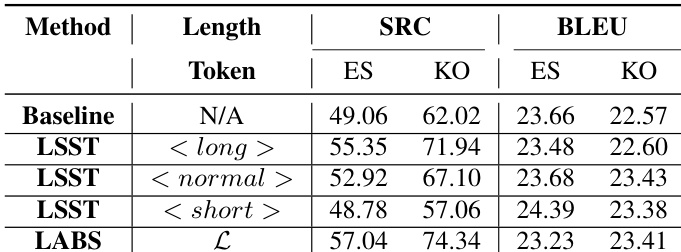
The authors evaluate a length-sensitive speech translation model using character and phoneme-based length tokens, comparing performance against a baseline. Results show that both length token types maintain translation quality while enabling control over output length, with phoneme-based approaches performing similarly to character-based ones. The proposed LABS method improves speech rate compliance and synchronization quality, particularly for Korean, while maintaining low latency and high translation quality. Both character and phoneme-based length tokens achieve similar translation quality to the baseline while enabling length control. Phoneme-based length tokens perform comparably to character-based ones, supporting the use of phonemes for length-sensitive translation. The LABS method improves speech rate compliance and synchronization quality, especially for Korean, with minimal latency increase.
The authors evaluate a length-sensitive speech translation model with different length control mechanisms, comparing baseline and LSST approaches using character and phoneme-based length units. Results show that the LABS method improves speech rate compliance while maintaining translation quality, with consistent improvements across languages and a minimal increase in latency. LABS improves speech rate compliance significantly over the baseline for both Spanish and Korean. The LABS method maintains translation quality with only a marginal decline in BLEU scores for Spanish and an improvement for Korean. LABS achieves better synchronization with minimal latency increase compared to traditional beam search.
The experiments evaluate a length-sensitive speech translation framework by comparing a standard baseline against a proposed length-aware alignment method that utilizes both character and phoneme-based tokens for output length control. These evaluations validate that both token types effectively preserve translation quality while enabling precise length management, with phoneme-based units performing comparably to character-based alternatives. Ultimately, the proposed approach significantly enhances speech rate compliance and audio-text synchronization across tested languages while maintaining minimal processing latency and robust overall translation performance.