Command Palette
Search for a command to run...
Triton-distributed: トライトンコンパイラを用いた分散AIシステムにおける重複するカーネルのプログラミング
Triton-distributed: トライトンコンパイラを用いた分散AIシステムにおける重複するカーネルのプログラミング
Triton コンパイラチュートリアルのワンクリックデプロイ
概要
単一チップのスケーリングが徐々にボトルネックに近づいているため、単一のアクセラレータでは既存の大規模言語モデルのトレーニングおよび推論をサポートできなくなっている。したがって、複数のアクセラレータで構成される分散システムを用いてトレーニングおよび推論を行うことが緊急の課題となっている。分散システムでは、計算、メモリアクセス、通信という3つの基本的な処理が並行して発生する。既存のトレーニング/推論フレームワークでは、これらの側面はしばしば異なるプログラミングレベルで独立して最適化されている。その結果、これらの処理は互いに協調しにくく、クラスターの性能ポテンシャルを最大限に引き出すことが困難である。本報告では、既存のTritonコンパイラを拡張したTriton-distributedを提案し、分散AIシステムにおけるプログラミングの課題を克服する。Triton-distributedは、分散AIワークロードに対してネイティブなオーバーラップ最適化をサポートする初のコンパイラであり、異なるフレームワークからの既存の最適化を広くカバーしている。まず、OpenSHMEM標準に準拠する通信プリミティブをコンパイラに統合する。これにより、プログラマはこれらのプリミティブをより高レベルのPythonプログラミングモデルで利用可能となる。
One-sentence Summary
Triton-distributed extends the Triton compiler to natively overlap computation, memory access, and communication for distributed AI workloads by integrating OpenSHMEM-compliant primitives into a Python programming model, thereby coordinating concurrent cluster operations to maximize performance for large language model training and inference.
Key Contributions
- This report introduces Triton-distributed, a compiler extension that integrates OpenSHMEM-compliant communication primitives into a Python programming model to unify distributed and computational kernel development.
- The framework enables native fine-grained computation-communication overlapping by automatically lowering compiler-assisted primitives to NVSHMEM or ROCSHMEM, allowing developers to implement complex distributed workloads with minimal code modifications while achieving performance comparable to low-level implementations.
- Evaluations on Nvidia and AMD GPUs demonstrate speedups ranging from 1.09× to 44.97× over NCCL and RCCL across diverse workloads, including AllGather GEMM, GEMM ReduceScatter, and expert-parallel AllToAll operations.
Introduction
The rapid scaling of large language models has shifted AI deployment from single accelerators to distributed multi-node clusters, making computation-communication overlap essential for maintaining throughput and controlling infrastructure costs. Prior distributed programming approaches struggle with this transition, as they typically target CPU clusters, demand complex low-level CUDA or C++ engineering, or rely on proprietary domain-specific languages that alienate Python-based algorithm developers. This workflow disconnect forces cross-language development, stifles productivity, and restricts advanced optimization to teams with exceptional engineering resources. To bridge this gap, the authors introduce Triton-distributed, a compiler extension built on the open-source Triton framework that enables fine-grained computation and communication overlapping entirely within Python. By compiling high-level primitives directly into optimized accelerator code, the authors deliver performance that rivals hand-written implementations while drastically reducing development overhead and supporting diverse hardware architectures.
Method
The authors leverage a compiler-based programming model for distributed AI workloads, centered on the MPMD (multiple programs multiple data) paradigm, which enables concurrent execution and coordination of computation, memory access, and communication tasks. The core of this model comprises three key concepts: symmetric memory, signal exchange, and async-task. Symmetric memory provides each rank with a globally scoped memory buffer, where each buffer resides in a separate address space, precluding direct remote memory access via pointers; instead, communication primitives are required. Signal exchange facilitates consistent coordination between ranks through data objects stored in symmetric memory, supporting operations such as setting, incrementing, checking, and spin-locking signals. Async-tasks treat operations like data transfer and computation as asynchronous units that can run in parallel, synchronized through signals, with implementation details varying by hardware backend—multi-streaming and multi-threading are common for GPUs.
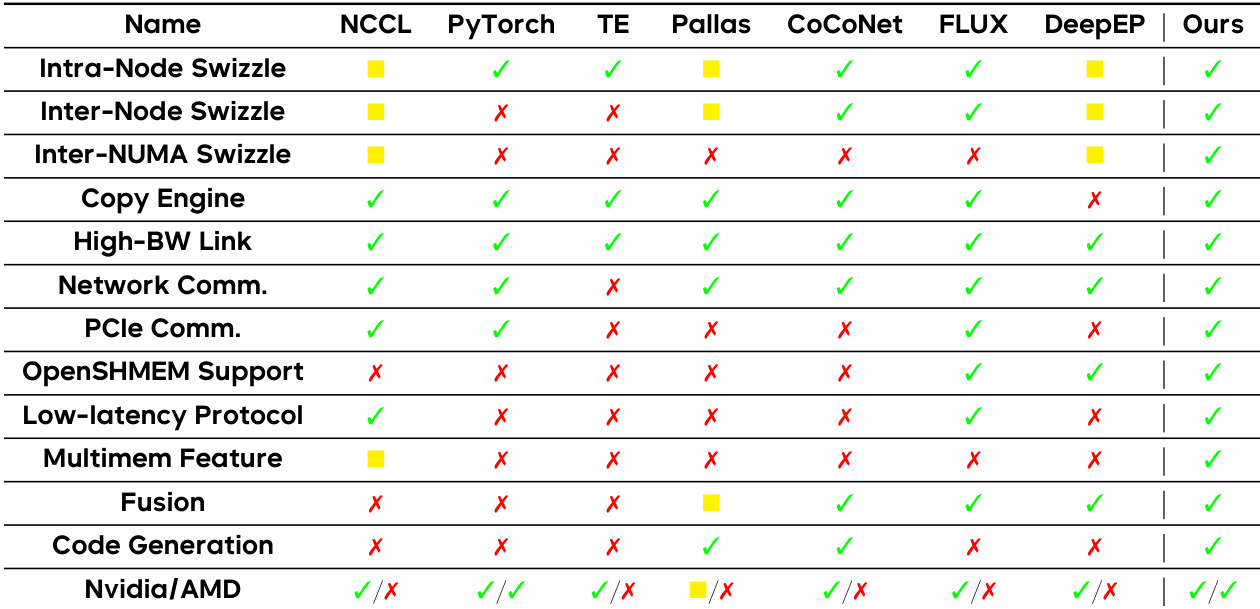
The compiler integrates communication primitives compliant with the OpenSHMEM standard, enabling programmers to utilize these primitives via a high-level Python programming model. These primitives include both OpenSHMEM implementations (NVSHMEM for Nvidia GPUs, ROCSHMEM for AMD GPUs) and non-OpenSHMEM primitives (e.g., wait, consume_token, notify) designed for specific optimization purposes like pipelining and low-latency communication. For instance, the wait and consume_token primitives are used to establish data dependencies between signal operations and subsequent memory access, enabling fine-grained synchronization. The framework supports a wide range of overlapping optimizations, as summarized in Table 2, covering techniques such as intra-node and inter-node swizzling, copy engine utilization, high-bandwidth link mapping, network communication optimization, PCIe scheduling, and hardware-specific features like TMA instructions on Nvidia and persistent kernel optimization on AMD.
The compiler's architecture, illustrated in Figure 1, operates as an extension of the Triton compiler. Users write programs in Python, typically using a compute.py file for computation and a communication.py file for communication, which are compiled into a unified IR. This IR is processed by the Triton compiler backend, which generates intermediate representations such as TTIR and TTIIR. The compiler then translates these into LLVM IR, which is further optimized and lowered into target-specific code, including PTX for Nvidia GPUs and AMDGCN for AMD GPUs. The compilation workflow integrates with hardware-specific libraries like SHMEM.bc lib and extra.ll lib to generate code that efficiently leverages the underlying hardware's capabilities. This design allows the compiler to generate code that can be optimized for both single-node and multi-node scenarios.
To demonstrate the programming model, the authors present an inter-node overlapping AllGather GEMM example. The communication part of the program is assigned to different threadblocks, with some responsible for intra-node data transfer and others for inter-node data transfer, enabling them to run in parallel. The computation part reuses Triton's GEMM implementation, with the addition of wait and consume_token primitives to create data dependencies and overlap communication with computation. The host-side code allocates symmetric memory and launches the communication and computation parts on different streams, ensuring that both tasks can execute concurrently. The timeline of this execution, as shown in Figure 3, demonstrates how the computation task runs in parallel with communication tasks across ranks.
The framework's ability to achieve fine-grained overlapping is further demonstrated through kernel implementations for different optimization purposes. For intra-node AllGather, the compiler utilizes the copy engine for data transfer, with push and pull modes available depending on the need for data arrival order control. Similarly, intra-node ReduceScatter is implemented using a push mode, where local data shards are pushed to other ranks after producing a tile, with the reduction operation running in parallel and synchronized via signals. For inter-node AllGather, the compiler employs a low-latency protocol (LL) for small message scenarios, where data and flags are stored together in an 8-byte chunk, and a spin-lock is used to check for arrival. This approach avoids the overhead of signal operations for each transfer, reducing latency. The compiler also supports inter-node ReduceScatter with heterogeneous communication, where intra-node scatter is scheduled on one stream, and local reduction and inter-node P2P communication are assigned to another stream to maximize bandwidth and minimize resource contention.
The compiler further optimizes performance through tile swizzling and code generation techniques. Swizzling controls the order in which tiles are processed to maximize overlap and minimize latency. For Nvidia GPUs, which use NVSwitches, the swizzle order ensures that each rank gathers data from one other rank at a time, fully utilizing the NVLink bandwidth. For AMD GPUs, which use a full-mesh topology, the swizzle order allows each rank to gather data from all other ranks simultaneously, maximizing the available bandwidth. Resource partitioning ensures that computation and communication tasks are mapped to different processing units (e.g., SMs for computation, copy engine for communication) to avoid contention and achieve perfect overlap. The compiler's autotuner is tailored for distributed kernels, considering both the synchronization needs of the kernel launch and the synchronization of tuning results across devices, enabling it to discover globally optimal configurations.
Experiment
The evaluation tests optimized communication-computation overlapping kernels across intra-node and inter-node configurations on Nvidia and AMD GPU clusters ranging from eight to sixty-four devices. Experiments validate the efficiency of GEMM, ReduceScatter, AllGather, and MoE routing operations against standard baselines, while distributed flash decoding benchmarks validate sustained high-bandwidth utilization across scaled hardware. The compiler-generated implementations consistently match or exceed hand-tuned libraries while requiring substantially less code, demonstrating strong generality across different accelerators and interconnects. Ultimately, the study confirms that these overlapping strategies and distributed kernels effectively accelerate large-scale model training and long-context inference.
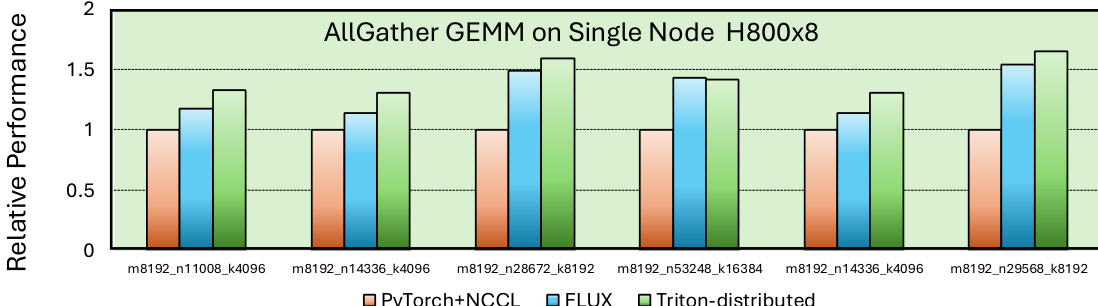
The authors evaluate their optimized kernels across various hardware and communication frameworks, comparing performance against multiple baselines including PyTorch, NCCL, FLUX, and DeepEP. Results show that their approach achieves significant speedups over baseline implementations, particularly in intra-node and inter-node communication scenarios, while also demonstrating compatibility with different GPU architectures and communication protocols. The authors highlight that their compiler-generated code achieves competitive performance with state-of-the-art solutions, even when using simpler implementation approaches. The proposed approach achieves substantial speedups over PyTorch+NCCL and FLUX baselines in intra-node and inter-node communication kernels. The system demonstrates strong compatibility across different GPU architectures and communication backends, including Nvidia and AMD GPUs, as well as NVLink and PCIe networks. Compiler-generated code achieves performance comparable to hand-optimized implementations, even with simplified memory management and reduced code complexity.
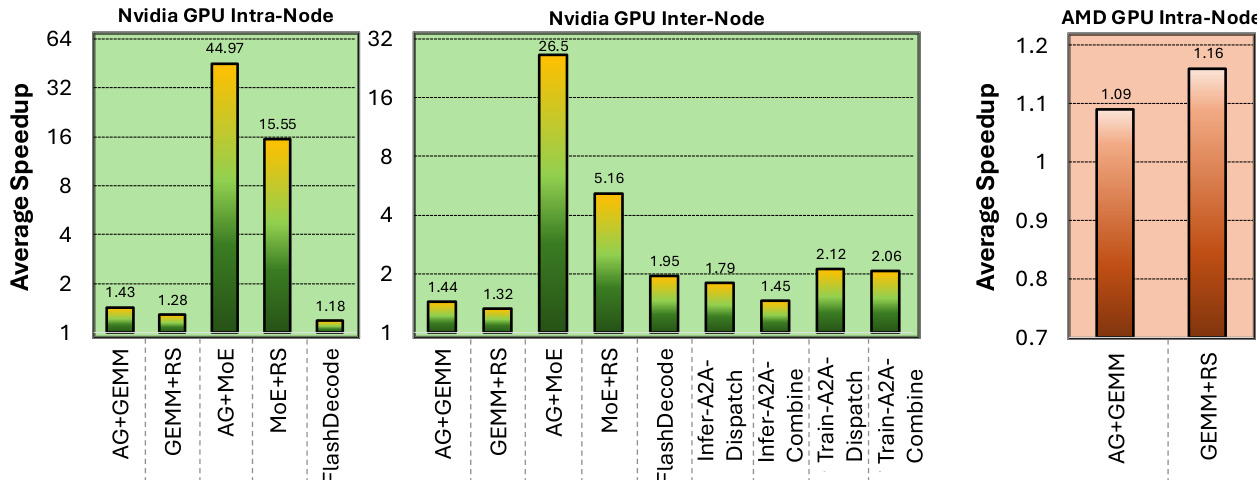
The authors evaluate the performance of optimized kernels across different GPU architectures and communication scenarios, comparing their approach to various baselines. Results show significant speedups for intra-node and inter-node operations on Nvidia GPUs, with more moderate improvements observed on AMD GPUs, particularly for AllGather and ReduceScatter kernels. The performance varies depending on the kernel type and scaling strategy, with some operations showing strong scaling and others limited by communication overhead. The approach achieves substantial speedups for intra-node operations on Nvidia GPUs, with notable improvements for AllGather GEMM and MoE ReduceScatter. Inter-node performance shows consistent gains over baselines, with near-peak efficiency compared to state-of-the-art implementations on Nvidia hardware. On AMD GPUs, the performance is competitive but slightly lower than optimized native libraries, with modest speedups observed for key communication kernels.
The authors present performance results for various kernel optimizations across different configurations and hardware platforms, including Nvidia and AMD GPUs. The experiments evaluate intra-node and inter-node operations, with a focus on speedups over baseline implementations such as PyTorch+NCCL and FLUX, as well as comparisons between different communication strategies and architectures. The proposed optimizations achieve significant speedups over baseline methods like PyTorch+NCCL across multiple kernel types and hardware platforms. Performance improvements vary between intra-node and inter-node operations, with some kernels showing better scalability than others when scaling across nodes. The approach demonstrates strong performance on both Nvidia and AMD GPUs, indicating generality and effectiveness across different hardware architectures.
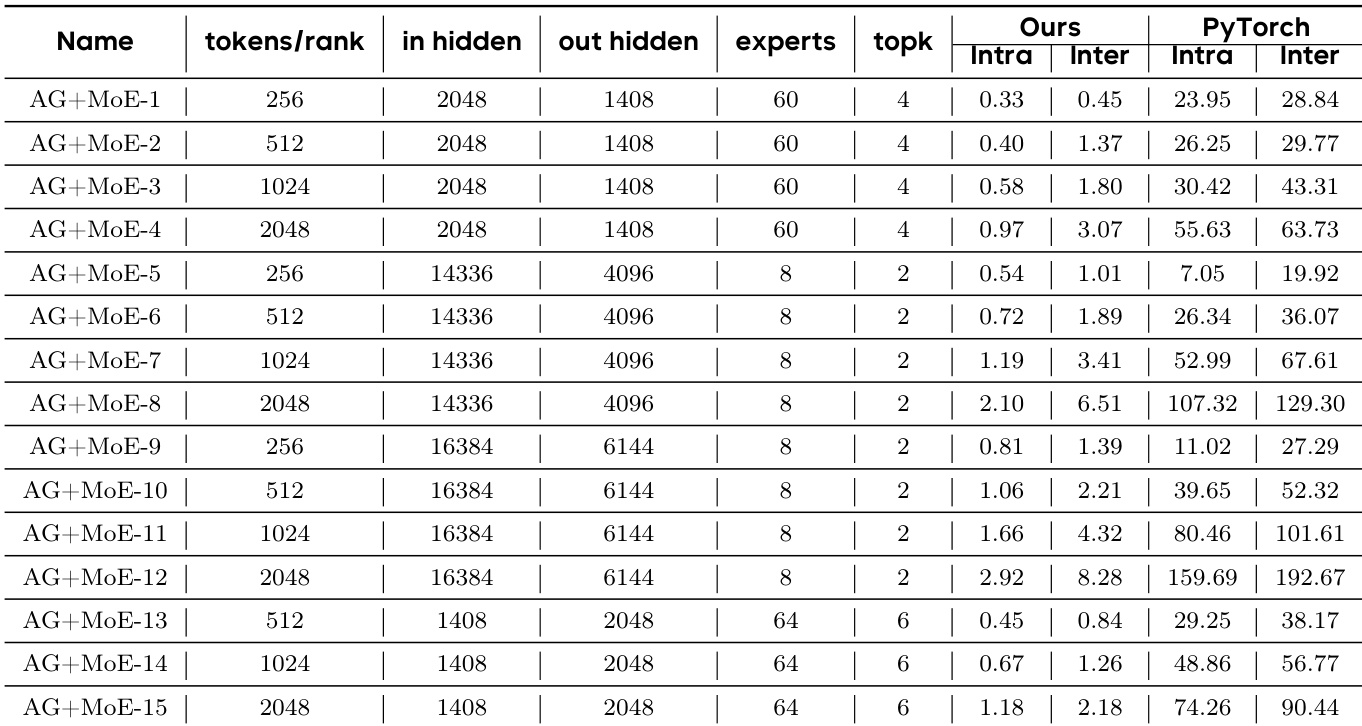
The authors evaluate the performance of optimized overlapping kernels across intra-node and inter-node configurations on Nvidia and AMD GPU clusters. The results show consistent speedups over baseline implementations, particularly in intra-node scenarios, with varying scalability when extending to multiple nodes. The proposed kernels achieve significant speedups over PyTorch+NCCL and FLUX in intra-node settings, with performance improvements ranging from 1.28× to over 44×. Inter-node scaling shows good weak scaling for AllGather-based kernels but suboptimal performance for ReduceScatter-based kernels, indicating a need for specialized optimizations. The approach demonstrates generality by achieving competitive performance on AMD GPUs, with speedups observed even when compared to optimized vendor-provided libraries.
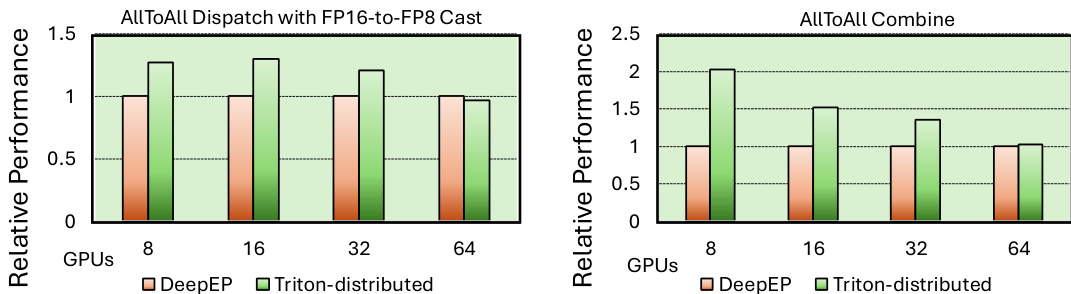
The authors compare the performance of their distributed AllToAll kernels against DeepEP across different numbers of GPUs. Results show that the Triton-distributed implementation outperforms DeepEP in most cases, particularly for the AllToAll Combine operation, while showing slightly lower performance for AllToAll Dispatch at higher GPU counts. The performance advantage is consistent across both 8 and 16 GPU configurations, with the gap widening at 32 and 64 GPUs. The Triton-distributed implementation achieves higher performance than DeepEP for the AllToAll Combine operation across all GPU counts. For the AllToAll Dispatch operation, the Triton-distributed approach performs worse than DeepEP at 64 GPUs. The performance gap between the two implementations increases as the number of GPUs scales from 8 to 64.
The experiments evaluate compiler-generated communication kernels across Nvidia and AMD GPUs, benchmarking them against established baselines like PyTorch+NCCL, FLUX, and DeepEP to validate performance across intra-node and inter-node configurations. The results demonstrate that the optimized approach consistently delivers substantial speedups over existing implementations, particularly for collective operations like AllGather and AllToAll Combine, while maintaining strong compatibility across diverse hardware architectures and network protocols. Scaling efficiency varies by kernel type due to inherent communication overheads, yet the system proves that simplified, compiler-driven code generation can match or exceed hand-optimized vendor libraries. Ultimately, the work confirms that the proposed methodology offers a highly effective and broadly compatible alternative for high-performance distributed communication.