Command Palette
Search for a command to run...
トークン分類
概要
One-sentence Summary
To address the uniform weighting assumption of conventional next-token prediction, this work introduces novel token-weighting schemes that assign non-uniform loss weights using a two-step framework scoring tokens by comparing the confidences of long-context and short-context models, with evaluations across multiple long-context understanding tasks demonstrating that non-uniform loss weights improve the long-context abilities of large language models.
Key Contributions
- This paper introduces a two-step token-weighting framework that replaces uniform loss weighting with dynamic scores derived from comparing prediction confidences between long-context and short-context models. The pipeline categorizes scoring methods and applies either dense or sparse postprocessing to adjust training emphasis.
- The study systematically evaluates dense versus sparse weight postprocessing and demonstrates that frozen pretrained short-context models function as effective, lightweight scorers. This mechanism explicitly upweights tokens reflecting long-range dependencies while downweighting trivial or inherently difficult ones.
- Evaluations across multiple long-context understanding tasks demonstrate that non-uniform loss weights consistently improve model performance over standard training baselines. These empirical findings establish practical guidelines for loss-weighting strategies and clarify the trade-offs inherent in long-context language modeling.
Introduction
Large language models are increasingly deployed for applications requiring long-context understanding, yet they consistently struggle to effectively utilize extended input sequences. While prior research has largely optimized training data and architectural efficiency, the training criterion itself has received little attention. Standard next-token prediction assigns equal importance to every token, which fails to account for the varying contextual demands across different sequences and obscures long-range dependencies. The authors leverage a novel token-weighting framework that dynamically adjusts loss contributions by comparing prediction confidences between short-context and long-context models. By systematically evaluating dense and sparse weighting schemes, they demonstrate that prioritizing tokens with genuine long-range dependencies significantly enhances model performance without altering the underlying architecture.
Dataset

-
Dataset Composition and Sources: The authors utilize the RULER benchmark, a synthetically generated evaluation suite comprising 6,500 examples distributed across 13 categories. These categories span four core long-context capability areas: retrieval, multi-hop tracing, aggregation, and question answering.
-
Key Details for Each Subset:
- Retrieval tasks feature five variants built around hidden key-value pairs within a distraction text. The authors control parameters including the number of pairs (m), key and value formats (words, numbers, or UUIDs), haystack composition (essays, repeated sentences, or empty), and query counts.
- Multi-hop tracing uses a variable tracking setup with five chained assignments to simulate coreference resolution.
- Aggregation tasks generate synthetic word lists requiring models to extract either ten words appearing thirty times each or the top three most frequent words sampled via a zeta distribution.
- Question answering subsets source documents from SQuAD for single-hop queries and HotPotQA for multi-hop scenarios, positioning one target document as the needle among randomly sampled distractors.
-
Data Usage and Processing: Each category contains exactly 500 examples, which the authors deploy exclusively for evaluation rather than model training. The provided excerpt does not detail training splits or mixture ratios, as the dataset functions as a standardized benchmark to stress-test long-context retention. Prompt templates and generation logic are adapted from the original RULER publication.
-
Additional Processing Details: The authors rely entirely on algorithmic construction with explicit hyperparameters to guarantee reproducibility and controlled noise levels. No manual cropping or metadata filtering is applied, as the synthetic framework inherently manages distraction density, task complexity, and answer formatting.
Method
The authors leverage a two-step framework for determining non-uniform token weights in the training objective of large language models (LLMs), aimed at improving long-context understanding capabilities. This framework consists of two key stages: token scoring and postprocessing. The overall approach generalizes prior work by allowing flexible and continuous weighting of tokens rather than restricting to sparse binary or quantile-based schemes. The method operates under the assumption that a base model θ0 has been pre-trained on sequences of bounded length n, and a target model θ is subsequently extended to handle longer sequences of length N≫n, typically through techniques such as position interpolation or RoPE base scaling. The goal is to enhance the model’s ability to capture long-range dependencies during training on extended-context data.

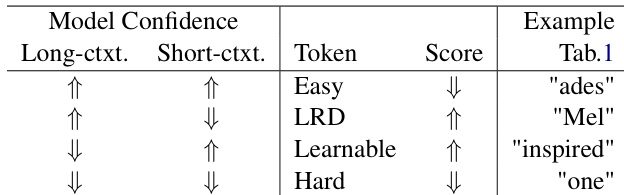
As shown in the figure below, the token scoring method is designed to identify tokens that are either difficult to predict under short-context modeling but predictable under long-context modeling (indicating long-range dependencies) or tokens that are already well-predicted by the long-context model but remain uncertain under the short-context model (suggesting learnable but not yet learned content). The scoring function is defined as the absolute value of the difference in log probabilities between a short-context model θ′ and the long-context model θ:
∣w~i∣=log(pθ(N)(i)pθ′(n)(i))=log(pθ′(n)(i))−log(pθ(N)(i)).Here, the superscript denotes the number of past tokens used for prediction, with θ′ operating on a context of length n and θ on length N. This formulation ensures that tokens exhibiting long-range dependencies—such as those where the short-context model is uncertain and the long-context model is confident—are assigned high scores. Conversely, tokens that are either inherently hard to predict (e.g., due to ambiguity or variation) or trivial (e.g., frequent or predictable) receive low weights. The absolute value ensures that the scoring remains positive and avoids negative values that would arise if the long-context model were less certain than the short-context model, which would violate the objective of emphasizing long-range dependencies during context extension.
The authors note that this scoring function corresponds to the negative conditional pointwise mutual information (CPMI) between the current token and the distant context, making it a natural measure of long-range influence. This property aligns with the desired behavior of emphasizing tokens where the faraway context provides significant predictive information. While alternative scoring methods exist, the chosen approach is favored for its simplicity and theoretical grounding.
The choice of the short-context model θ′ is a critical design decision. One option is to use θ0, the pre-trained model, as the short-context model and freeze its parameters. This approach is similar to that used in ρ, but it requires either pre-scoring the entire dataset or maintaining two models during training, which increases memory consumption. Alternatively, the authors consider using a smaller model as the short-context model, which can act as a "teacher" in a weak-to-strong generalization setup. This allows for more efficient scoring, especially when multiple models of the same architecture are available. A third option is to use the long-context model θ itself but artificially limit its context during scoring, which shares weights and reduces memory overhead. The authors explore these choices empirically and discuss their trade-offs.
In the postprocessing stage, the authors move away from sparse weighting schemes like those in ρ, which set weights to zero or 1/κ based on quantiles. Instead, they adopt a dense weighting approach by directly using the normalized scores ∣w~i∣. To ensure compatibility with standard training procedures, the scores are normalized such that their sum equals the sequence length N:
norm(∣w~i∣)=N⋅∑i=1N∣w~i∣∣w~i∣.This normalization ensures that the effective loss remains comparable to uniform weighting, allowing the use of standard learning rates. To further control the degree of deviation from uniformity, the authors interpolate between the normalized scores and uniform weights using a hyperparameter λ∈[0,1]:
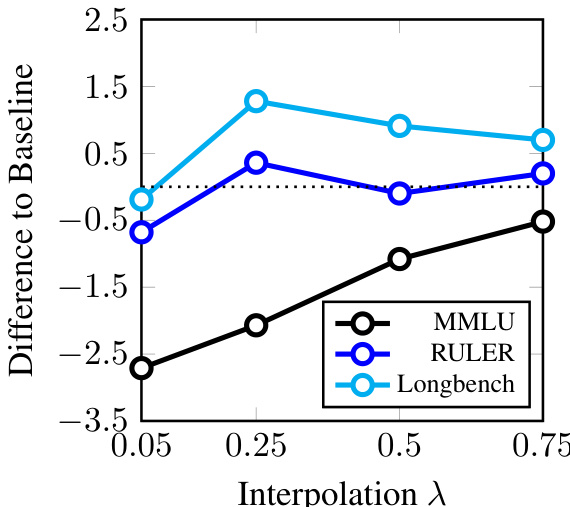
wi=λ+(1−λ)⋅norm(∣w~i∣).This interpolation acts as a temperature-like parameter: when λ=1, weights are uniform; when λ=0, weights are fully determined by the scoring function. This allows for a smooth trade-off between short-context performance and long-context capability, enabling fine-tuning of the model's focus across different contexts. The authors emphasize that this dense weighting scheme avoids signal loss from sparsification and is compatible with standard autoregressive training, despite the lack of backward pass speed-up due to the nature of transformer decoders.
Experiment
The experiments evaluate extending the context windows of Llama-3 8B and Phi-2 2.7B to 32k tokens using various token weighting schemes, assessing long-context capabilities on RULER and Longbench while monitoring short-context retention on MMLU and BBH. The results demonstrate that non-uniform token weights consistently outperform uniform baselines, with sparse weighting effectively concentrating learning on long-range dependencies to boost retrieval-heavy tasks at the expense of short-context performance. Conversely, dense weighting preserves a more balanced generalization across both long and short contexts, while frozen scoring models generally prove more robust than unfrozen ones when managing significant context length mismatches. Ultimately, the study confirms that strategic token weighting successfully extends model context windows, though practitioners must navigate a clear trade-off between specialized long-range retrieval and broad short-context retention.
The authors compare different token weighting methods for extending the context of language models, evaluating their performance on long-context tasks and short-context benchmarks. Results show that sparse unfrozen weighting improves long-context capabilities while sacrificing some short-context performance, whereas frozen models with dense weighting maintain a balance between the two. The best overall performance is achieved by sparse frozen models, which combine long-context focus with better short-context retention. Sparse unfrozen weighting enhances long-context performance but degrades short-context capabilities. Frozen models with dense weighting achieve a better balance between long- and short-context performance. Sparse frozen models yield the highest overall performance by combining long-context focus with retained short-context ability.
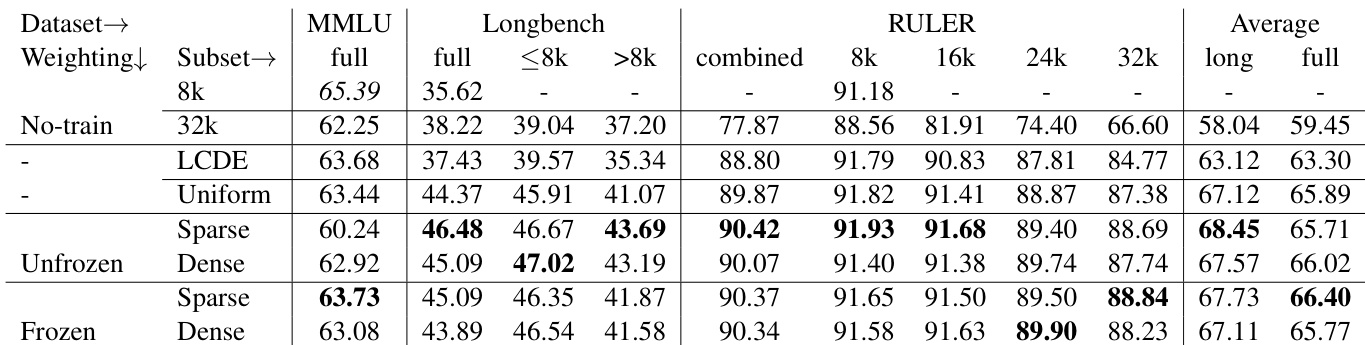
The authors compare different token weighting methods for extending the context of language models, focusing on long-context performance and retention of short-context capabilities. Results show that non-uniform weighting improves long-context understanding, with sparse unfrozen models excelling on retrieval-heavy tasks but at the cost of short-context performance, while frozen models maintain a better balance between long and short contexts. The choice of weighting scheme significantly affects performance across benchmarks, with dense methods preserving generalization and sparse methods specializing on key information. Sparse unfrozen models achieve the best long-context performance but struggle with short-context tasks due to ignoring early tokens. Frozen models, particularly sparse frozen, maintain a better trade-off between long-context capabilities and short-context retention. Dense weighting methods preserve generalization and perform more consistently across both long and short-context evaluations.
The authors investigate the impact of token weighting methods on extending the context length of language models, comparing dense and sparse weighting schemes with frozen and unfrozen scoring models. Results show that sparse unfrozen weighting improves long-context performance but at the cost of short-context capabilities, while frozen models with sparse weighting achieve a better balance between long- and short-context performance. The choice of scoring model and weighting strategy significantly affects downstream task performance, particularly on retrieval-heavy and synthetic tasks. Sparse unfrozen weighting enhances long-context performance but degrades short-context capabilities. Frozen models with sparse weighting achieve a better trade-off between long- and short-context performance. The effectiveness of weighting methods varies by task, with sparse unfrozen excelling in retrieval-heavy and synthetic tasks.
The authors compare different token weighting methods for extending the context length of language models, focusing on performance across various context lengths and tasks. Results show that sparse unfrozen models perform best on long-context tasks, particularly in retrieval-heavy scenarios, while dense models maintain better short-context performance. The choice of scoring model, whether frozen or unfrozen, significantly impacts overall performance, with frozen models generally outperforming unfrozen ones in long-context tasks. Sparse unfrozen models excel on long-context tasks, especially in retrieval-heavy scenarios, but struggle with short-context performance. Dense models maintain a more balanced performance across short and long contexts, preserving short-context abilities better than sparse models. Frozen models outperform unfrozen models in long-context tasks, with the choice of scorer having a significant impact on overall results.
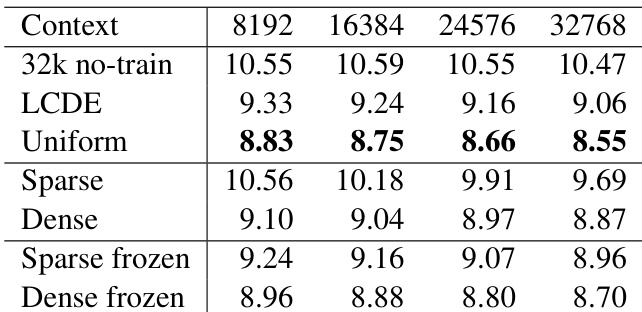
The authors compare different token weighting methods for extending the context length of language models, focusing on their impact on long-context performance and retention of short-context capabilities. Results show that sparse unfrozen weighting improves long-context performance, particularly on retrieval-heavy tasks, but at the cost of short-context performance, while dense methods maintain better overall balance. The choice of scoring model, whether frozen or unfrozen, also influences performance, with frozen models generally performing better in the sparse setting. Sparse unfrozen weighting improves long-context performance but harms short-context capabilities. Dense weighting methods maintain better overall performance and retain short-context abilities. Frozen scoring models outperform unfrozen ones in sparse settings, while unfrozen models can recover from poor initial long-context performance.
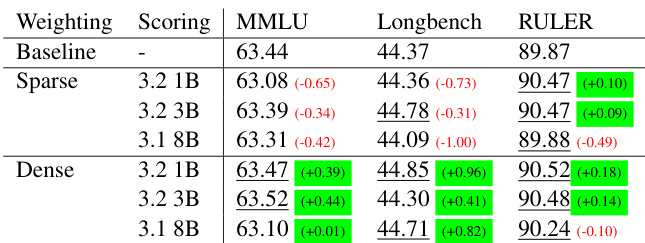
The experiments evaluate different token weighting strategies, comparing dense and sparse schemes with frozen and unfrozen scoring models to assess their impact on extending language model context lengths. Each validation focuses on the critical trade-off between improving long-context capabilities, particularly in retrieval-heavy tasks, and preserving short-context generalization. Qualitatively, sparse unfrozen weighting maximizes long-context performance but degrades short-context retention, whereas dense methods maintain a more consistent balance across both domains. Ultimately, sparse frozen models deliver the strongest overall results by effectively prioritizing long-context focus while retaining short-context abilities.