Command Palette
Search for a command to run...
Phi-4技術報告書
Phi-4技術報告書
ワンクリックでPhi-4をデプロイ
概要
我々は、データ品質を中核に据えたトレーニングレシピを用いて開発された140億パラメータの言語モデルphi-4を発表する。ウェブコンテンツやコードなどの有機的なデータソースを主にベースとするほとんどの言語モデルとは異なり、phi-4はトレーニングプロセス全体を通じて合成データを戦略的に取り入れている。Phiシリーズの以前のモデルは主に教師モデル(具体的にはGPT-4)の能力を蒸留していたのに対し、phi-4はSTEM(科学・技術・工学・数学)に焦点を当てた質問応答(QA)能力において教師モデルを大幅に上回り、当社のデータ生成およびトレーニング後の手法が蒸留を超えていることを示す証拠を提供している。phi-3アーキテクチャへの変更は最小限であるにもかかわらず、phi-4は改善されたデータ、トレーニングカリキュラム、およびトレーニング後スキームにおける革新により、その規模に対して強力なパフォーマンス、特に推論に焦点を当てたベンチマークにおいて優れたパフォーマンスを達成している。
One-sentence Summary
Phi-4 is a 14-billion parameter language model that achieves strong performance on reasoning-focused benchmarks by prioritizing data quality through strategic synthetic data incorporation, a refined training curriculum, and novel post-training innovations, thereby substantially surpassing GPT-4 on STEM-focused QA and demonstrating that these techniques extend beyond standard teacher distillation.
Key Contributions
- The paper introduces phi-4, a 14-billion parameter language model that strategically incorporates synthetic data throughout training to move beyond traditional organic data sources and standard distillation pipelines.
- A refined post-training pipeline is developed that constructs improved supervised fine-tuning datasets and implements a direct preference optimization technique based on pivotal token search.
- The model demonstrates strong reasoning and STEM question-answering capabilities that match or exceed significantly larger architectures, notably surpassing GPT-4o on the GPQA and MATH benchmarks and outperforming Llama-3.1-405B on multiple reasoning evaluations.
Introduction
Large language models have traditionally prioritized compute scaling and massive organic datasets, yet emerging evidence shows that data quality is a more efficient driver for improving reasoning capabilities. Previous models typically rely on uncurated web text or distill knowledge from larger teacher models, which limits their depth in complex problem-solving and often yields factual inconsistencies. The authors leverage a 14-billion parameter architecture to introduce phi-4, fundamentally shifting the training paradigm toward curated synthetic data generation, optimized training curricula, and advanced post-training optimization. This data-centric approach enables the model to match or exceed significantly larger competitors and outperform its GPT-4 teacher on rigorous STEM benchmarks without requiring architectural modifications.
Dataset
- Dataset Composition and Sources
- The authors combine heavily curated organic corpora with extensively generated synthetic datasets to form the core pretraining corpus.
- Organic sources span filtered web dumps, academic repositories (arXiv, PubMed Central), code platforms (GitHub), educational forums, licensed books, and multilingual archives (CommonCrawl, Wikipedia) covering 176 languages.
- Synthetic data comprises approximately 400 billion tokens across fifty distinct categories, engineered to cover diverse reasoning tasks, code generation, and academic problem-solving.
- Post-training datasets include supervised fine-tuning prompts and direct preference optimization pairs derived from rejection sampling and LLM evaluations.
- Key Details for Each Subset
- Filtered Web Data: The largest cluster with roughly 1.3 trillion unique tokens, split into reasoning-heavy and knowledge-dense portions. Quality is enforced using small classifiers trained on LLM-generated annotations, with specialized pipelines to balance STEM and non-STEM content.
- Synthetic Data: Generated from high-quality seeds using multi-stage prompting, self-revision feedback loops, and instruction reversal techniques. The authors prioritize diversity, nuanced complexity, factual accuracy, and explicit chain-of-thought reasoning.
- Web Rewrites: Approximately 290 billion tokens created by transforming filtered organic passages into structured exercises, discussions, and reasoning tasks.
- Code Data: Around 820 billion unique tokens combining raw and synthetic sources. All code is validated through execution loops and automated testing to ensure correctness.
- Q&A and Academic Data: Tens of millions of organic problems are collected and filtered using plurality voting to balance difficulty. Inaccurate answers are replaced with synthetically generated alternatives, and the entire set undergoes rigorous decontamination.
- Long-Context Data: A dedicated subset for midtraining includes samples exceeding 8K and 16K token lengths, specifically up-weighted to improve extended sequence handling.
- Data Usage and Mixture Ratios
- Pretraining allocates 40 percent of tokens to synthetic data, 30 percent to web and web rewrites split evenly, 20 percent to code, and 10 percent to targeted acquisitions like academic papers and books.
- The authors conduct ablation studies to optimize these ratios, finding that heavy synthetic allocation improves reasoning while targeted organic data is essential for knowledge retention and reducing hallucinations.
- Midtraining extends the context window from 4K to 16K tokens. The mixture shifts to 30 percent newly curated long-context data and 70 percent recall from pretraining, trained over 250 billion tokens with a reduced learning rate and adjusted RoPE frequency.
- Post-training utilizes SFT data for response generation and a two-stage DPO pipeline for alignment. The DPO process incorporates pivotal token pairs and judge-guided optimization, with 1 to 5 percent of the data reserved for safety and refusal training.
- Processing, Metadata, and Cropping Strategies
- The authors employ custom extraction pipelines that parse diverse file formats while preserving fragile elements like MathML equations, syntax-highlighted code, and forum thread structures through DOM tree normalization.
- Synthetic seeds are annotated with rich metadata, including complexity levels, factual obscurity scores, reasoning chains, step-by-step logical dependencies, and information type classifications.
- Advanced generation techniques include fill-in-the-middle exercises, where meaningful text segments are removed to create context and answer pairs, and multi-turn conversation synthesis that iteratively refines dialogue through self-critique.
- Decontamination relies on a hybrid n-gram algorithm using 13-gram and 7-gram features to match against standard benchmarks, with common phrases explicitly whitelisted to prevent over-filtering.
- Quality assurance is enforced through execution-based code validation, majority voting for answer consistency, and rubric-driven model self-revision before data enters the training loop.
Method
The phi-4 model is built upon a decoder-only transformer architecture, closely resembling the design of phi-3-medium but with several key enhancements. It features 14 billion parameters and a default context length of 4096, which is extended to 16K during midtraining to support longer sequences. The model employs the tiktoken tokenizer, enabling improved multilingual capabilities, and uses a padded vocabulary size of 100,352, including unused tokens. Unlike phi-3-medium, which uses a sliding window attention mechanism over a 2K context, phi-4 utilizes full attention over the entire 4K context length during pretraining, allowing for more effective modeling of long-range dependencies.

Pretraining is conducted on approximately 10 trillion tokens using a linear warm-up and decay learning rate schedule, with a peak learning rate of 0.0003, a constant weight decay of 0.1, and a global batch size of 5760. Hyperparameters are optimized through interpolations from shorter training runs and validated via stress testing of the warm-up phase to ensure stability. After pretraining, a midtraining phase is applied to extend the context length from 4K to 16K, enabling the model to handle longer inputs effectively.
To evaluate the model during pretraining, a custom benchmarking framework is employed that combines log-likelihood and few-shot prompting across various tasks. This includes log-likelihood evaluations for MMLU (5-shot), MMLU-pro, and ARCC (1-shot), and few-shot evaluations for TriviaQA (TQA), MBPP, MATH, and GSM8k using 1, 3, 4, and 8 examples respectively. These evaluations are designed to ensure the model adheres to expected answer formats, facilitating easier solution extraction.
Post-training is structured to transform the pretrained model into a safe and capable AI assistant. This process involves one round of supervised fine-tuning (SFT), followed by two rounds of Direct Preference Optimization (DPO). The first DPO round uses data generated via the pivotal token search (PTS) method, while the second applies DPO on full-length preference pairs. The model is fine-tuned using the standard chatml format, which structures conversations with system, user, and assistant messages, enabling coherent and context-aware interactions.

Pivotal Token Search (PTS) is a key innovation in the preference data generation pipeline. It identifies critical tokens in a response sequence that significantly influence the probability of correctness. For a given prompt Q and completion Tfull=t1,t2,…, PTS estimates the conditional probability of success p(success∣t1,…,ti) by sampling completions from Q+t1,…,ti. The algorithm recursively subdivides the sequence until the change in success probability falls below a threshold pgap or a single token remains. Tokens causing sharp changes in success probability are deemed pivotal and used to construct preference pairs, where the accepted and rejected completions are single tokens tacc and trej that respectively increase and decrease the success probability.
PTS is applied to tasks with ground-truth verification, such as mathematics, question answering, and coding, with filtering to retain only questions where 0.2≤p(success)≤0.8, as pivotal tokens are rare in extremely easy or hard cases. This method ensures that DPO optimization focuses on high-impact tokens, improving model behavior without being diluted by noise from less significant tokens. Preference data generated via PTS is shown in Figure 5, where pivotal tokens are underlined, highlighting their critical role in determining solution correctness.
The post-training framework also incorporates hallucination mitigation strategies. SFT data and DPO pairs are constructed to encourage the model to refuse answers when uncertain, rather than generating fabricated content. This approach significantly reduces hallucinations, as evidenced by the decreasing frequency of attempts on SimpleQA problems during post-training (Figure 6).
Safety alignment is further enhanced through the use of helpfulness and harmlessness preference datasets, adapted from prior work and augmented with in-house generated data. This ensures the model adheres to responsible AI principles across multiple harm categories. Additionally, training data includes trajectories from AgentKit, which capture detailed chain-of-thought reasoning, improving planning, reasoning, tool use, and error correction capabilities. These trajectories are rewritten into self-contained thoughts to preserve the essence of the reasoning process, enabling the model to exhibit structured and reflective problem-solving behavior.
Experiment
The evaluation framework integrates decontaminated internal benchmarks, fresh mathematical competitions, and independent safety red-teaming to validate the model’s reasoning capabilities, computational efficiency, and alignment. Testing on unseen competition data and contamination-proof datasets confirms that the model’s strong STEM and coding performance reflects genuine generalization rather than benchmark leakage, while comparative analysis demonstrates its superior inference efficiency over long chain-of-thought alternatives. Although minor limitations persist in strict instruction following, targeted post-training strategies successfully enhance reasoning quality and adversarial defenses, establishing the model as a highly capable and resource-efficient foundation.
The authors analyze the impact of different post-training components on model performance across various benchmarks, showing that combining pivotal token DPO and judge-guided DPO leads to improvements on reasoning-heavy tasks. Results indicate that the S + WR configuration achieves the highest average score, while the Uniform baseline performs the worst across most metrics. The S + W configuration shows mixed results, with some improvements in specific areas but overall lower performance compared to S + WR. Combining pivotal token DPO and judge-guided DPO leads to the best overall performance on reasoning benchmarks. The S + WR configuration achieves the highest average score across all evaluated benchmarks. The Uniform baseline performs the worst across most metrics, indicating the importance of post-training techniques.

The authors analyze the impact of synthetic data and web rewrites on model performance across multiple benchmarks. Results show that adding web rewrites to synthetic data leads to improvements on most benchmarks, with notable gains on Human-Eval and MBPP, while some metrics like TQA and MMLU show minor degradation. The improvements are consistent across different evaluation domains, indicating the effectiveness of the data strategy. Adding web rewrites to synthetic data improves performance on most benchmarks, particularly on Human-Eval and MBPP. The model shows consistent gains across evaluation domains when using combined data, indicating robust improvement. While most metrics improve, some benchmarks like TQA and MMLU show slight degradation with the addition of web rewrites.
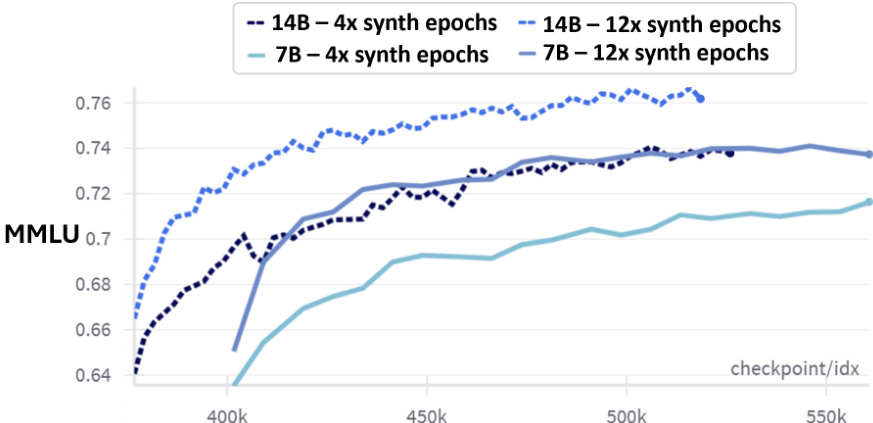
The authors evaluate phi-4 and compare its performance to several other models across multiple benchmarks, showing that phi-4 achieves strong results in various tasks, particularly in reasoning and STEM-related evaluations. The model's performance is consistent across different input lengths, with improvements observed in some benchmarks when the maximum length is increased, indicating robustness to input size. Results show that phi-4 outperforms comparable models in most categories, with notable strengths in reasoning and coding tasks. phi-4 achieves top performance in multiple benchmarks, outperforming models like Qwen-2.5-14B and Llama-3.3-70B in most categories. The model shows consistent performance across different input lengths, with improvements in some metrics when the maximum length is increased to 16K. phi-4 demonstrates strong reasoning capabilities, particularly in STEM and coding tasks, outperforming larger models in key areas.
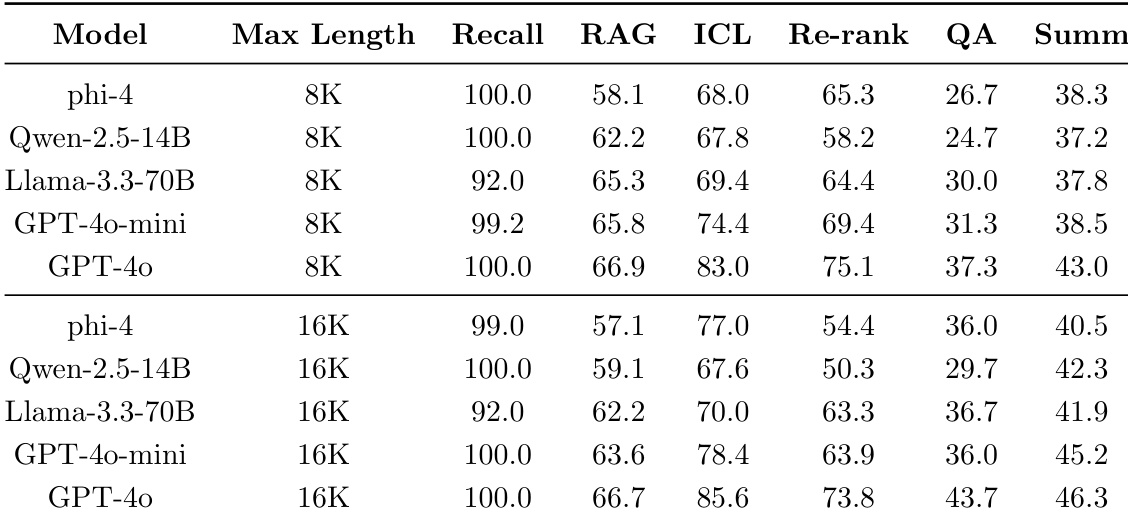
The authors describe a training process that involves multiple data sources, with synthetic data contributing the largest fraction of training tokens. The training strategy includes varying numbers of epochs for different data types, with synthetic data undergoing the most extensive training. Web-related data sources are trained for a moderate number of epochs, while code and acquired data are trained for fewer epochs. Synthetic data constitutes the largest portion of the training data and undergoes the most training epochs. Web-related data sources are trained for a moderate number of epochs, while code and acquired data are trained for fewer epochs. The training process uses a diverse set of data sources, each with different fractions of training tokens and epochs.
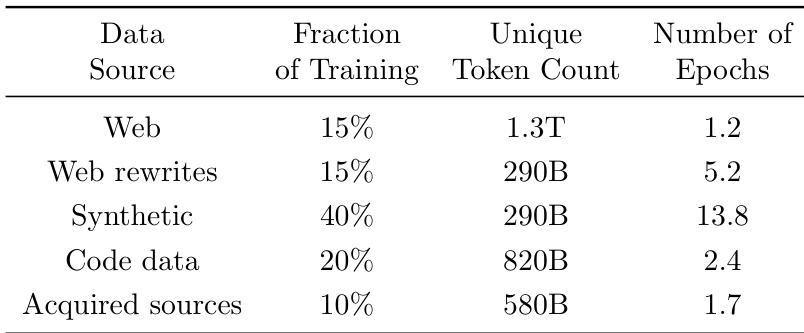
The authors present benchmark results for phi-4, comparing performance across different model sizes and evaluation tasks. Results show that the 16k version of phi-4 outperforms the 4k version on most benchmarks, with notable improvements in reasoning and STEM tasks, while both versions show relative weaknesses in instruction-following and specific QA tasks. The performance gains are attributed to post-training techniques, including pivotal token DPO and judge-guided DPO, which are particularly effective on reasoning-heavy benchmarks. The 16k version of phi-4 shows consistent improvements over the 4k version across most benchmarks, especially in reasoning and STEM tasks. Pivotal token DPO and judge-guided DPO are effective post-training methods, with complementary strengths on different types of benchmarks. phi-4 achieves strong performance on reasoning and STEM tasks, outperforming larger models on certain benchmarks, but shows weaker performance on instruction-following and specific QA benchmarks.

The evaluation setup spans multiple reasoning, STEM, coding, and instruction-following benchmarks to assess how data composition, training duration, and alignment techniques influence model capabilities. Each experiment validates that combining pivotal token and judge-guided DPO, alongside a data strategy that prioritizes synthetic content with web rewrites, significantly strengthens reasoning and coding performance. While these configurations deliver robust cross-domain improvements, they also reveal minor trade-offs in specific QA and instruction-following tasks. Overall, the results confirm that targeted post-training alignment and a strategically weighted multi-source training mixture are the key drivers of the model's advanced reasoning capabilities.