Command Palette
Search for a command to run...
Hunyuan-Large: Tencentによる520億活性化パラメータを持つオープンソースのMoEモデル
Hunyuan-Large: Tencentによる520億活性化パラメータを持つオープンソースのMoEモデル
Tencent Hunyuan Team
ワンクリックで HunyuanVideo をデプロイ
概要
本論文では、現在最も大規模なオープンソースのTransformerベースのMixture of Experts(MoE)モデルであるHunyuan-Largeを紹介します。Hunyuan-Largeは総パラメータ数が3,890億、活性化パラメータ数が520億であり、最大256Kのtokensを処理することができます。Hunyuan-Largeは、言語理解と生成、論理的推論、数学的問題解決、コーディング、長文コンテキスト、および統合タスクを含む様々なベンチマークにおいて優れた性能を示し、Llama3.1-70Bを上回り、さらに大幅に大きなLlama3.1-405Bモデルと同等の性能を発揮します。Hunyuan-Largeの主要な技術的工夫としては、従来の研究よりも桁違いに大きな規模の合成データ、混合expertルーティング戦略、key-valueキャッシュ圧縮技術、およびexpert固有の学習率戦略が挙げられます。さらに、本論文ではMoEモデルのスケーリング則と学習率スケジューリングについても調査し、将来のモデル開発と最適化に向けた貴重な洞察とガイダンスを提供します。Hunyuan-Largeのコードとチェックポイントは、将来の革新と応用を促進するために公開されています。
One-sentence Summary
The Tencent Hunyuan Team introduces Hunyuan-Large, an open-source Transformer-based mixture of experts model with 389 billion total and 52 billion activated parameters that handles up to 256K tokens and outperforms Llama3.1-70B while demonstrating performance comparable to Llama3.1-405B across language, reasoning, coding, and long-context benchmarks through large-scale synthetic data, mixed expert routing, key-value cache compression, and expert-specific learning rates.
Key Contributions
- Introduce Hunyuan-Large, an open-source Transformer-based mixture of experts model comprising 389 billion total parameters and 52 billion activation parameters to support a 256K token context window.
- Incorporate a recycle routing strategy, key-value cache compression, and an expert-specific learning rate schedule to reduce overhead and improve token utilization during large-scale pre-training.
- Demonstrate superior performance across diverse benchmarks by outperforming Llama3.1-70B and matching the capabilities of Llama3.1-405B in language understanding, logical reasoning, mathematics, coding, and long-context tasks.
Introduction
Large language models have rapidly transformed fields ranging from natural language processing to scientific computing, with Mixture of Experts (MoE) architectures emerging as a highly efficient paradigm for scaling performance while managing computational costs. Despite this progress, the open-source community remains heavily reliant on dense models, as existing open MoE implementations are typically limited to smaller parameter scales. To address this gap, the authors introduce Hunyuan-Large, a 389-billion-parameter Transformer-based MoE model that dynamically activates 52 billion parameters per token and supports a 256K context window. By leveraging high-quality synthetic data, architectural optimizations like KV cache compression and recycle routing, and systematic scaling law analysis, the authors deliver a model that outperforms comparable open-source counterparts across reasoning, coding, and multilingual tasks. The team has publicly released both pre-trained and post-trained weights to accelerate community research and real-world deployment.
Dataset
-
Dataset Composition and Sources The authors build a bilingual (Chinese and English) corpus that merges a natural text foundation with extensive synthetic data. Natural sources span web pages, question-answering platforms, code repositories, books, and encyclopedias. The collection is supplemented by PenguinScrolls, a specialized long-context benchmark featuring financial, legal, and academic documents.
-
Key Subset Details
- Pre-training Natural Data: Filtered for writing quality, educational value, and toxicity. Privacy-sensitive and harmful content is anonymized or excluded.
- Pre-training Synthetic Data: Focused on mathematics, coding, low-resource domains, and high-educational-value topics. Generated via a four-step pipeline: seed-based instruction generation, difficulty and clarity evolution, expert model response generation, and self-consistency filtering.
- Supervised Fine-Tuning Data: Exceeds 1 million samples targeting logic, reasoning, coding, role-playing, and long-text capabilities. Built by extracting instructions from public sources and systematically generalizing them into complex variants.
- PenguinScrolls Benchmark: Contains contexts up to 128K tokens, multi-turn human-simulated dialogues, and four task types: information extraction, localization, qualitative analysis, and numerical reasoning.
-
Data Usage and Training Strategy The authors mix natural and synthetic pre-training data in a configurable ratio, dynamically adjusting category proportions throughout training. For SFT, the dataset is carefully curated to target specific capability gaps, ensuring the model receives balanced exposure to diverse instruction types. All data flows through a multi-stage processing pipeline before being fed into the model.
-
Metadata, Cropping, and Quality Control While no explicit text cropping strategy is detailed, the authors implement a robust metadata system using category labels and a structured instruction taxonomy. These tags enable precise control over data distribution and help prevent overfitting to dominant instruction types. Quality assurance relies on a three-tier filtering approach for SFT: rule-based checks for formatting and duplication, a 70B parameter critique model scoring accuracy and relevance, and final human annotation to enforce task-specific response patterns. Synthetic pre-training data undergoes automated critique and self-consistency validation before inclusion.
Method
The authors leverage a mixture-of-experts (MoE) architecture for Hunyuan-Large, building upon the classical Transformer structure with key innovations in model design and training methodology. The overall framework is structured around a hierarchical organization of experts, where each token is routed to a subset of specialized experts for processing, enabling efficient scaling of model capacity. The model employs a combination of shared and specialized experts, with a single shared expert handling common knowledge across all tokens and 16 specialized experts dynamically activated to capture domain-specific patterns. This routing mechanism is enhanced by a novel recycle routing strategy, which addresses inefficiencies in traditional top-k routing by reallocating tokens from overloaded experts to underutilized ones, thereby preserving valuable information and improving training stability.
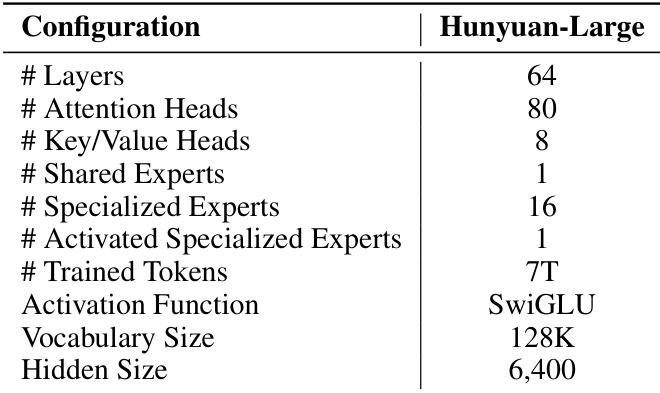
Refer to the framework diagram for an overview of the model's architecture and hyper-parameters. The model utilizes Rotary Position Embedding (RoPE) for positional encoding and SwiGLU as the activation function. The architecture is designed to balance parameter count and computational efficiency, with a total of 389 billion parameters and only 52 billion activated parameters during inference, allowing for high-capacity modeling without prohibitive memory overhead.
To reduce memory pressure during inference, the authors integrate two complementary techniques for key-value (KV) cache compression: Grouped-Query Attention (GQA) and Cross-Layer Attention (CLA). GQA reduces the number of KV heads by grouping them, while CLA shares the KV cache across adjacent layers. In Hunyuan-Large, these techniques are combined with 8 GQA groups and KV cache sharing every two layers, resulting in a nearly 95% reduction in KV cache memory compared to standard multi-head attention. This optimization significantly enhances inference efficiency without degrading model performance.
The model's training process incorporates a sophisticated learning rate strategy tailored to the imbalanced workload across experts. While AdamW is used as the optimizer, the authors apply expert-specific learning rate scaling to account for differences in the number of tokens processed by each expert. The shared expert, which processes all tokens, is assigned the optimal learning rate based on the full batch size, while specialized experts, which are activated only for a fraction of tokens, receive a scaled-down learning rate. This scaling ensures balanced training dynamics and maximizes efficiency, with a learning rate ratio of approximately 0.31 between the shared and specialized experts.
The pre-training recipes are guided by a systematic exploration of MoE scaling laws. The compute budget for MoE models is modeled as a function of both total parameters and activated parameters, with attention complexity factoring into the equation due to sparse activation patterns. By training a series of models with varying activation counts and analyzing their performance under constrained compute budgets, the authors derive optimal scaling laws for activated parameters and training data volume. This analysis informs the selection of 52 billion activated parameters and approximately 7 trillion training tokens, ensuring cost-effective model development. The learning rate schedule further enhances training stability, featuring a warmup phase, a prolonged decay phase, and a final annealing phase where the learning rate is reduced to one-tenth of its peak value to fine-tune the model on high-quality data.
Finally, to enable long-context capabilities, Hunyuan-Large undergoes a dedicated long-context pre-training phase. This phase involves training on sequences up to 256K tokens, with a gradual increase in sequence length from 32K to 256K. The RoPE positional embedding is scaled to a base frequency of 1 billion during the 256K stage, allowing the model to effectively model long-range dependencies. The pre-training corpus for this phase combines natural long-context data from books and code with standard-length data, ensuring that the model maintains strong performance on both long and short-context tasks.
Experiment
Evaluations employ standardized zero and few-shot protocols across diverse benchmarks to validate the foundational capabilities of the base model, the alignment and instruction-following proficiency of the post-trained variant, and the robustness of extended context processing. Pre-training results demonstrate that an optimized MoE architecture combined with high-quality data synthesis yields superior cross-task performance while maintaining high parameter efficiency. Subsequent instruction tuning experiments confirm that advanced preference optimization strategies significantly enhance alignment and strict prompt adherence without degrading general reasoning. Long-context assessments further verify the model's consistent stability and accurate information retention across extended sequences, establishing it as a highly efficient and versatile language model.
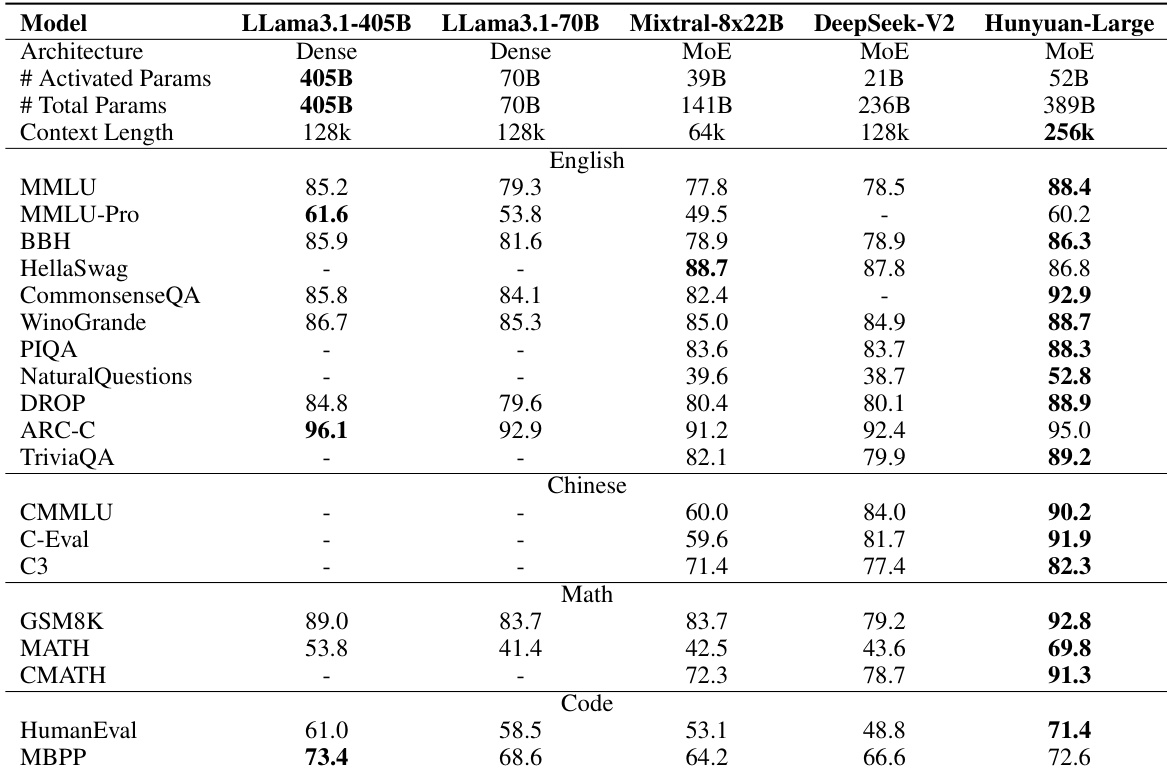
The authors present evaluations of Hunyuan-Large, a model with a mixture-of-experts architecture, demonstrating strong performance across various benchmarks in both pre-trained and post-trained settings. The model achieves top results in multiple categories, including reasoning, mathematics, coding, and language understanding, often outperforming models with larger activated parameter counts. It also shows robust long-context capabilities, maintaining high performance across extended input lengths. Hunyuan-Large achieves superior performance compared to models with similar or larger activated parameter sizes on diverse tasks including reasoning, math, and coding. The post-trained version of Hunyuan-Large demonstrates strong alignment and instruction-following abilities across multiple benchmark categories. The model maintains high performance across extended context lengths, outperforming strong baselines on long-context evaluation benchmarks.
The authors evaluate Hunyuan-Large, a mixture-of-experts model, against dense and MoE competitors on various benchmarks in English and Chinese, including reasoning, commonsense, math, and coding tasks. Results show that Hunyuan-Large achieves the best overall performance, particularly in Chinese tasks and long-context scenarios, while using fewer activated parameters than larger models. The model also demonstrates strong performance on post-trained evaluations and alignment benchmarks. Hunyuan-Large achieves superior performance across multiple benchmarks compared to models with similar or larger activated parameter counts. The model shows strong results in Chinese tasks and long-context evaluations, outperforming baselines like LLaMA3.1-70B-Instruct. Hunyuan-Large achieves top-tier performance in math and coding tasks, with notable improvements on MMLU and MATH datasets.
The authors evaluate Hunyuan-Large-Instruct on long-context benchmarks, comparing its performance against a strong baseline model. Results show that Hunyuan-Large-Instruct maintains high performance across various context lengths, demonstrating superior stability and consistently outperforming the baseline in both RULER and LV-Eval benchmarks, particularly in longer context ranges. Hunyuan-Large-Instruct consistently outperforms the baseline across all context lengths in both RULER and LV-Eval benchmarks. The model shows superior stability in long-context processing, with minimal performance degradation as context length increases. Hunyuan-Large-Instruct achieves significant improvements over the baseline in the 64K to 128K token range on RULER.

The authors evaluate the Hunyuan-Large-Instruct model on a set of benchmarks focusing on information extraction, localization, qualitative analysis, and numerical reasoning, comparing its performance against LLaMa3.1-70B-Instruct. Results show that Hunyuan-Large-Instruct outperforms the baseline across all evaluated tasks, achieving higher scores in each category and a superior overall performance. The model demonstrates particular strength in information extraction and qualitative analysis, with consistent gains over the comparison model. Hunyuan-Large-Instruct achieves higher performance than LLaMa3.1-70B-Instruct across all evaluated task categories. The model shows the strongest improvement in information extraction and qualitative analysis compared to the baseline. Hunyuan-Large-Instruct achieves a higher overall score, indicating superior performance across the tested capabilities.

The authors evaluate Hunyuan-Large-Instruct across various benchmarks, comparing it to state-of-the-art dense and mixture-of-experts models. Results show that Hunyuan-Large-Instruct achieves superior performance on multiple tasks, particularly in reasoning, mathematics, code generation, and alignment, while also demonstrating strong long-context capabilities. Hunyuan-Large-Instruct outperforms comparable models on key benchmarks including MMLU, MATH, and HumanEval. The model achieves top results on alignment and instruction-following tasks, indicating strong alignment with user intent. Hunyuan-Large-Instruct shows consistent performance across long-context evaluations, surpassing baselines in handling extended inputs.
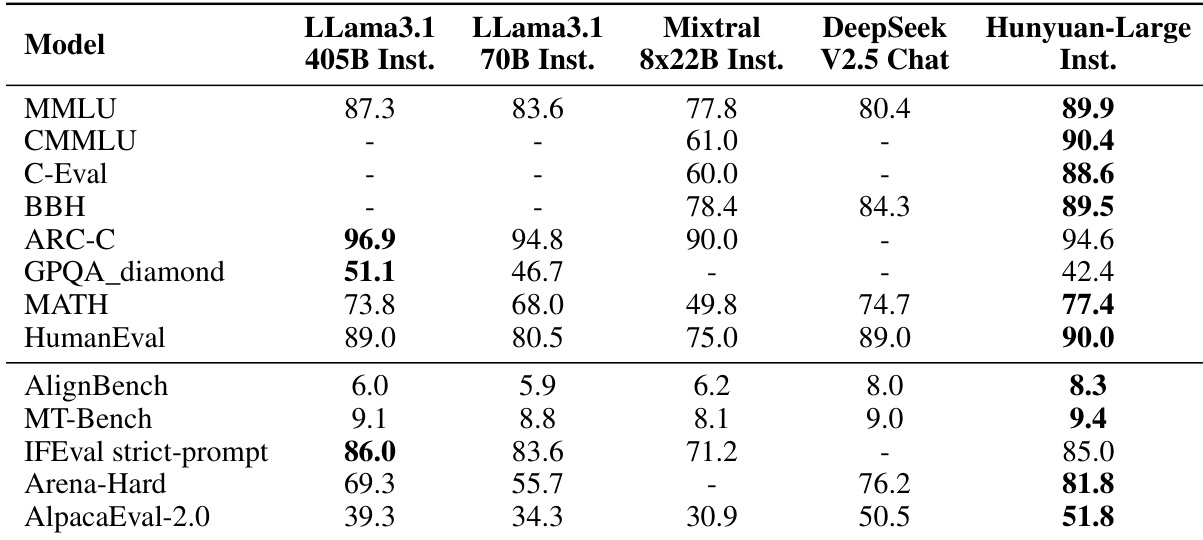
The authors evaluate Hunyuan-Large and its instruction-tuned variant against competitive dense and mixture-of-experts baselines across a comprehensive suite of English and Chinese benchmarks. These experiments validate the model’s proficiency in reasoning, mathematics, coding, alignment, information extraction, and long-context processing. Qualitatively, the architecture consistently delivers top-tier results while utilizing fewer activated parameters than larger competitors, demonstrates remarkable stability across extended context windows, and exhibits strong cross-lingual and instruction-following capabilities. Overall, the evaluations confirm that the model achieves superior efficiency and robust generalization across diverse downstream tasks.