Command Palette
Search for a command to run...
GSM-Symbolic: 大規模言語モデルにおける数学的推論の限界の理解
GSM-Symbolic: 大規模言語モデルにおける数学的推論の限界の理解
Iman Mirzadeh Keivan Alizadeh Oncel Tuzel Samy Bengio Hooman Shahrokhi Mehrdad Farajtabar
概要
大規模言語モデル(LLM)における近年の進展は、その数学的推論能力に対する関心を高めている。広く普及しているGSM8Kベンチマークにおけるパフォーマンスは向上しているものの、報告されている評価指標の信頼性については依然として疑問が残っており、LLMの推論能力は確実に進化している。既存の評価が抱える限界を克服するため、我々はGSM-Symbolicを導入する。これは、多様な問題の生成を可能にする記号的テンプレートを用いて構築された改善されたベンチマークである。GSM-Symbolicはより制御可能な評価を可能にし、モデルの推論能力を測定するための重要な洞察と、より信頼性の高い指標を提供する。我々の発見は、LLMが同一問題の異なるインスタンスに対して応答する際に、目に見えるばらつきを示すことを明らかにしている。具体的には、GSM-Symbolicベンチマークにおいて、問題内の数値のみを変更した場合、モデルのパフォーマンスは低下する。さらに、我々はこれらのモデルにおける数学的推論の脆弱性を調査し、問題内の節(clause)数が増加するにつれてパフォーマンスが大幅に悪化することを示した。我々は、このパフォーマンス低下は、現在のLLMが真の論理的推論を実行できるわけではないためであるという仮説を立てている。むしろ、それらは学習データで観察された推論ステップを模倣しようとしているに過ぎない。
One-sentence Summary
The authors introduce GSM-Symbolic, a benchmark utilizing symbolic templates to generate diverse questions that overcome limitations in existing evaluations such as GSM8K by revealing performance variance across numerical instantiations and significant deterioration with increased clause counts, indicating models replicate training patterns rather than perform genuine logical reasoning.
Key Contributions
- This work introduces GSM-Symbolic, an improved benchmark created from symbolic templates that allow for the generation of a diverse set of questions. The benchmark enables more controllable evaluations and provides reliable metrics for measuring the reasoning capabilities of models.
- Findings reveal that large language models exhibit noticeable variance when responding to different instantiations of the same question. Specifically, the performance of models declines when only the numerical values in the question are altered within the GSM-Symbolic benchmark.
- The research demonstrates that model performance significantly deteriorates as the number of clauses in a question increases. These findings support the hypothesis that current models lack genuine logical reasoning and instead replicate steps observed in training data.
Introduction
Mathematical reasoning is vital for deploying artificial intelligence in scientific and real-world applications. Current evaluations rely on static benchmarks like GSM8K, which limit robustness testing and risk data contamination. The authors address these gaps with GSM-Symbolic, a benchmark utilizing symbolic templates to generate diverse question variants for controlled evaluation. Their findings show that model performance varies across question instantiations and drops when numerical values or irrelevant clauses change. These results suggest Large Language Models depend on pattern matching rather than genuine logical reasoning.
Dataset
-
Dataset Composition and Sources
- The authors base their work on the GSM8K dataset, which includes over 8000 grade school math questions split into 7473 training and 1319 test examples.
- They introduce GSM-Symbolic to generate numerous instances with controlled difficulty, addressing risks of data contamination and sensitivity to minor question modifications.
-
Processing and Key Details
- Templates are created from GSM8K test examples by identifying variables, domains, and conditions such as divisibility to ensure whole number answers.
- Common proper names are used for persons, foods, and currencies while automated checks verify that original values do not appear in the template.
- Manual review covers 10 random samples per template, with additional review triggered if fewer than two models answer a question correctly during evaluation.
- Numerical ranges align with the original GSM8K test set to focus on logical reasoning rather than arithmetic skills within known accuracy boundaries.
-
Model Usage and Evaluation
- The data serves as a reliable evaluation framework to view LLM performance as a distribution across various problem instances.
- This approach assesses mathematical capabilities and robustness to diverse problem difficulties and augmentations beyond a single fixed metric.
Experiment
This work evaluates the reasoning capabilities of various large language models using GSM-Symbolic, a benchmark generated by mutating GSM8K templates to test reliability and robustness. Results indicate significant performance variance across different question instantiations, with original GSM8K metrics often overstating true capability due to potential data contamination. Additional experiments demonstrate that reasoning abilities are fragile, as accuracy declines with increased numerical complexity or irrelevant information, suggesting models rely on pattern matching rather than formal logical understanding.
The authors evaluate various large language models on the GSM8K benchmark and its symbolic variants to assess reasoning reliability. The results indicate a consistent performance drop when models are tested on symbolic variations compared to the original GSM8K dataset, suggesting potential data contamination or reliance on pattern matching rather than formal reasoning. Furthermore, increasing question difficulty or adding irrelevant information leads to significant degradation in accuracy across all tested models. Models generally achieve higher accuracy on the standard GSM8K benchmark compared to the symbolic variations. Increasing question difficulty by adding clauses leads to lower performance scores compared to the base symbolic version. Adding seemingly relevant but inconsequential information results in the lowest performance scores across the board.
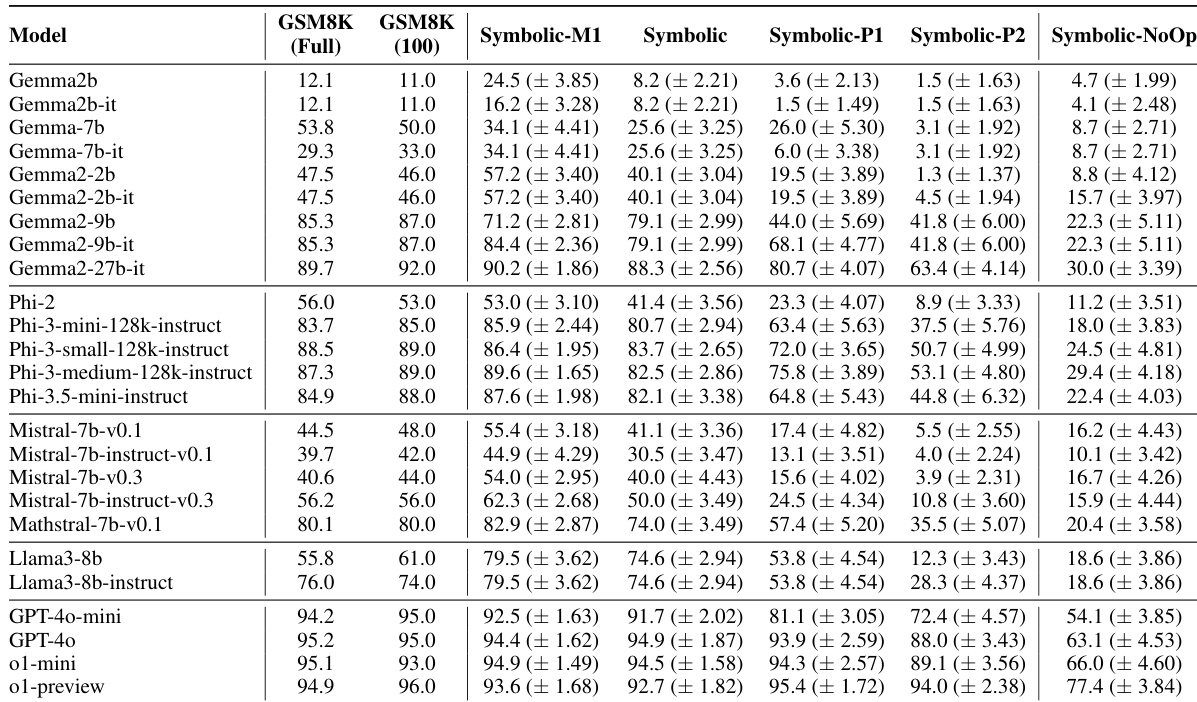
The authors compare model performance across the original GSM8K benchmark and three modified variants designed to test reasoning robustness through symbolic changes and increased difficulty. The results indicate that the original GSM8K benchmark consistently achieves higher overall accuracy compared to the modified versions, suggesting that these variations introduce challenges that slightly reduce model performance. The original GSM8K benchmark demonstrates superior overall performance compared to the modified GSM-Symbolic and GSM-P variants. Increasing question difficulty through added clauses results in a measurable drop in accuracy, with GSM-P1 and GSM-P2 scoring lower than GSM-Symbolic. Models maintain high accuracy across the benchmarks, though the specific variant of the test has a noticeable impact on the final results.
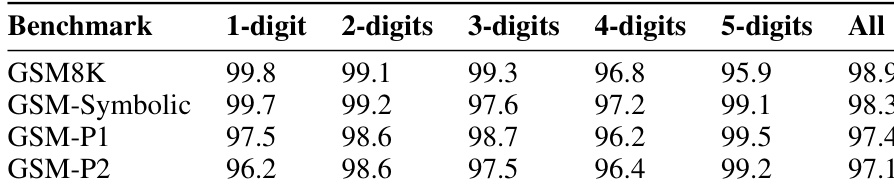
The authors evaluate large language models on the GSM8K benchmark and modified variants to assess reasoning reliability and robustness against symbolic changes. Results indicate a consistent performance drop on these variations compared to the original dataset, suggesting a potential reliance on pattern matching rather than formal reasoning. Furthermore, increasing question difficulty or adding irrelevant information leads to significant accuracy degradation across all tested models.