Command Palette
Search for a command to run...
Open WebUI を使用した Llama 3.1 405B のワンクリックデプロイ
概要
One-sentence Summary
The authors evaluate Meta’s Llama 3.1 405B for automated code generation and algorithmic problem solving, demonstrating that its contextual awareness and multi-language support effectively translate natural language prompts into executable code for simple algorithmic and data structure tasks, though the model struggles with advanced domains such as quantum computing, bioinformatics, and artificial intelligence.
Key Contributions
- This paper presents an empirical evaluation of Llama 3.1 405B for translating natural language prompts into executable multi-language code, establishing a performance baseline across foundational algorithmic and data structure tasks.
- Experimental results quantify the model’s performance degradation in specialized domains, specifically identifying consistent limitations in generating correct code for quantum computing, bioinformatics, and artificial intelligence challenges.
- The analysis identifies inherent limitations in LLM-generated code, including syntax errors, semantic inaccuracies, and suboptimal efficiency, while demonstrating how contextual awareness and debugging functionalities can improve software development productivity.
Introduction
Large language models have increasingly enabled developers to translate natural language prompts into functional code across multiple programming languages, streamlining software development workflows and democratizing programming access. Despite these advances, prior approaches frequently generate syntactically valid but semantically flawed or unoptimized code, while struggling with deep reasoning, complex programming constructs, and strict domain constraints. The authors evaluate Meta’s Llama 3.1 405B model to benchmark its code generation and algorithmic problem solving capabilities, demonstrating reliable performance on foundational data structure and sorting tasks. They identify significant performance degradation when the model encounters specialized domains like quantum computing, bioinformatics, and advanced artificial intelligence, providing a clear roadmap for targeted architectural refinements and domain-specific training to address these computational gaps.
Dataset
- Dataset Composition and Sources: The authors assembled a specialized programming corpus by consulting subject teachers across five technical domains: Artificial Intelligence (AI), Quantum Computing (QC), Algorithms (AG), Programming and Data Structures (PDS), and Bioinformatics Applications (BioA).
- Subset Details: Each domain contains exactly 100 programming problems, creating a balanced total of 500 items. The collection features domain-specific coding tasks, including quantum computing implementations such as defining qubit operators for max cut problems.
- Data Usage and Processing: The authors utilize this curated set as a benchmark for model training and evaluation. While the provided excerpts do not specify exact training splits or mixture ratios, the problems are structured by subject to test comprehensive technical proficiency.
- Additional Processing Details: The text does not outline any cropping strategies or metadata construction pipelines. Validation relies entirely on expert consultation rather than automated filtering, ensuring technical accuracy and pedagogical relevance.
Method
The authors leverage a modular and well-structured approach to implement the A* algorithm for efficient pathfinding in weighted graphs. The core framework operates by maintaining two primary data structures: an open set containing candidate nodes to be evaluated, and a map tracking the best-known path to each node via the cameFrom dictionary. Each node is assigned a cost function f(n)=g(n)+h(n), where g(n) represents the actual cost from the start node to node n, and h(n) is a heuristic estimate of the remaining cost to the goal. The algorithm proceeds iteratively, selecting the node with the lowest f(n) from the open set at each step, updating the costs of its neighbors if a shorter path is found, and propagating these updates through the graph.
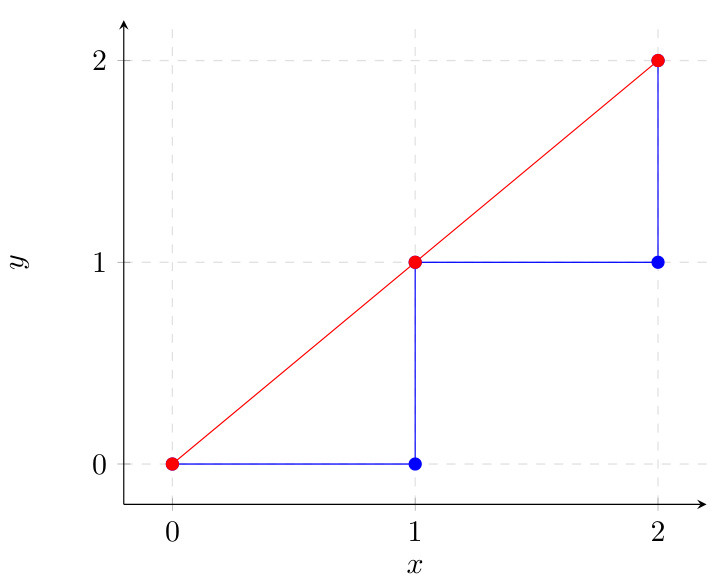
As shown in the figure below, the algorithm evaluates nodes in order of their total estimated cost, prioritizing paths that appear to lead more directly toward the goal. The red line illustrates the path taken by the algorithm, while the blue lines represent the edges traversed during the exploration. The heuristic function h(n), which in this example is the Manhattan distance, guides the search by biasing the selection toward nodes closer to the goal, ensuring that the algorithm efficiently converges on the optimal path. The implementation includes a standard loop that terminates when the goal node is reached or when the open set is exhausted, returning either the reconstructed path or a failure indicator. The design emphasizes clarity and correctness, with well-defined variables and a logical flow that aligns with the theoretical foundations of A* search.
Experiment
Three large language models were evaluated on their ability to generate correct, relevant, and complete code across multiple technical subjects through expert verification and human scoring. This experimental framework validates both the objective accuracy and subjective quality of each model's domain-specific problem-solving capabilities. Qualitative analysis reveals that Llama 3.1 405B consistently delivers the most reliable and thorough outputs, followed closely by Gemini, while GPT-3.5 Turbo demonstrates notable limitations in specialized categories. Although expert feedback highlights minor implementation considerations regarding optimization and result interpretation for the leading model, it remains the most effective choice for complex programming tasks.
The authors compare the performance of three language models—Llama 3.1 405B, Gemini, and GPT-3.5 Turbo—on programming tasks across multiple domains, evaluating both correctness and human-rated quality. Results show that Llama 3.1 405B achieves the highest accuracy in most categories and outperforms the others in human evaluation of relevance and completeness, while GPT-3.5 Turbo shows lower performance, particularly in specialized domains. Llama 3.1 405B achieves the highest performance across all categories in terms of correctness. GPT-3.5 Turbo performs well in Algorithms and PDS but significantly worse in AI, BioA, and QC. Llama 3.1 405B receives the highest human evaluation scores for relevance and completeness.
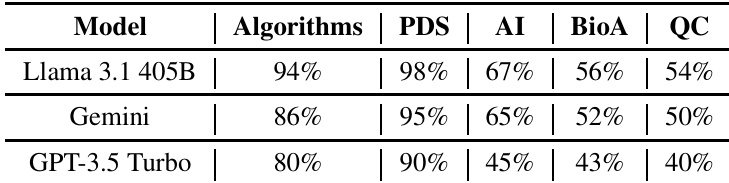
The authors evaluate the performance of three language models—Llama 3.1 405B, Gemini, and GPT-3.5 Turbo—on programming tasks across multiple subjects using both automated correctness assessment and human evaluation. Results show that Llama 3.1 405B outperforms the other models in both relevance and completeness, with Gemini ranking second and GPT-3.5 Turbo scoring the lowest. Llama 3.1 405B achieves the highest scores in both relevance and completeness compared to Gemini and GPT-3.5 Turbo. Gemini shows strong performance, ranking second in both evaluation metrics. GPT-3.5 Turbo has the lowest scores in relevance and completeness among the three models.
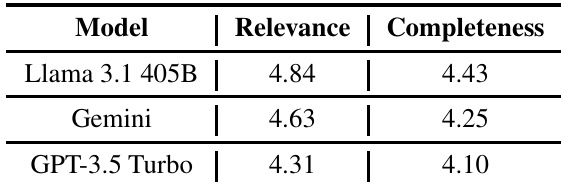
The experiments assess Llama 3.1 405B, Gemini, and GPT-3.5 Turbo on programming tasks across various domains through automated correctness verification and human evaluation of relevance and completeness. Llama 3.1 405B consistently demonstrates superior accuracy and produces the most relevant and complete solutions, establishing it as the strongest performer. Gemini ranks second with reliable results, whereas GPT-3.5 Turbo shows marked weaknesses, especially in specialized technical fields. These findings collectively validate a clear performance hierarchy, highlighting Llama 3.1 405B's robustness for complex programming applications.