Command Palette
Search for a command to run...
Hyper-SD のワンクリックデプロイメント
概要
One-sentence Summary
The authors propose Hyper-SD, a consistency distillation framework that mitigates the performance degradation of existing diffusion models by integrating ODE trajectory preservation and reformulation through Trajectory Segmented Consistency Distillation, human feedback learning, and score distillation, while leveraging a unified LoRA to enable efficient, low-step image synthesis with reduced computational overhead.
Key Contributions
- The framework introduces Trajectory Segmented Consistency Distillation (TSCD), which partitions diffusion time steps into predefined segments to enforce high-order consistency locally before progressively merging them. This mechanism preserves the original ODE trajectory and mitigates accumulated fitting errors during step compression.
- Human feedback learning and score distillation are incorporated to optimize few-step generation capabilities, supported by a unified Low-Rank Adaptation (LoRA) module that maintains consistent inference across all time steps. This integration enhances model performance in low-step regimes while aligning with human preferences.
- Extensive evaluations on the SDXL and SD1.5 benchmarks demonstrate state-of-the-art performance in low-step inference regimes. The method delivers high-quality image generation with significantly reduced computational overhead relative to existing diffusion acceleration techniques.
Introduction
Diffusion models have become foundational to generative AI, yet their reliance on lengthy multi-step inference creates substantial computational overhead that limits real-world deployment. Prior acceleration strategies typically follow two paths: trajectory-preserving distillation, which maintains the original model flow but often degrades output quality due to accumulated fitting errors, and trajectory-reformulating distillation, which constructs faster generation paths but frequently introduces domain inconsistencies with the base model. The authors tackle these trade-offs by introducing a unified distillation framework that strategically merges both methodologies. They propose trajectory segmented consistency distillation to enforce fine-grained alignment across time steps while progressively reducing inference steps. Additionally, they integrate human feedback learning to reshape ODE trajectories for optimal few-step performance and employ score distillation within a unified LoRA adapter to enable robust one-step generation. This combined approach delivers state-of-the-art image quality across SDXL and SD1.5 architectures while drastically cutting computational overhead.
Dataset
- Dataset Composition and Sources: The authors use subsets from the LAION and COYO datasets for the primary distillation training pipeline, while incorporating the COCO2017 training split specifically for human feedback learning.
- Key Details for Each Subset:
- LAION and COYO: Processed following the SDXL-lightning protocol to generate text-image pairs for multi-stage distillation.
- COCO2017: Utilized exclusively for structure optimization, leveraging its pre-existing instance annotations and paired captions.
- Data Usage and Training Configuration: The LAION and COYO subsets drive the progressive time-step reduction across four training stages. The COCO2017 data supports human feedback learning by providing structured ground truth for alignment. All distillation phases employ a batch size of 512, a learning rate of 1e-6, and train lightweight LoRA adapters rather than full UNet weights.
- Processing and Metadata Handling: The paper does not introduce custom cropping or metadata construction. Preprocessing relies on the standard SDXL-lightning workflow for LAION and COYO, while the COCO2017 subset directly applies its built-in instance segmentation masks and captions for structure optimization.
Method
The authors leverage a multi-stage framework to enhance the distillation of diffusion models, focusing on preserving the original ordinary differential equation (ODE) trajectory while enabling efficient few-step inference. The core of the method, termed Trajectory Segmented Consistency Distillation (TSCD), addresses the limitations of single-stage consistency distillation by decomposing the full time-step range [0,T] into k segments. This segmentation allows for progressive and fine-grained distillation, reducing model fitting complexity and minimizing errors that degrade generation quality. The process begins with a coarse segmentation, where the time interval is divided into k parts, and consistency distillation is performed independently within each segment. As shown in the figure below, the initial stage trains a model to follow the ODE trajectory within two distinct segments, [0,T/2] and [T/2,T], resulting in two separate consistent ODE paths. This is followed by a global consistency trajectory distillation stage that integrates the segment-specific results into a unified model. 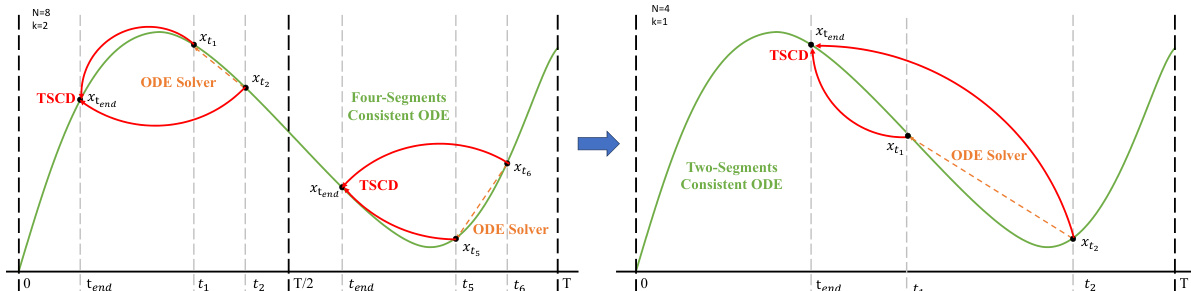
The TSCD framework dynamically adapts the training loss to the stage of training. It employs a hybrid loss function combining adversarial loss and Mean Squared Error (MSE) loss. The adversarial loss is prioritized in later stages where the divergence between predictions and targets increases, while MSE loss is more effective in earlier stages with closer predictions. This dynamic weighting ensures stable and effective training across all stages. Furthermore, a noise perturbation mechanism is integrated to enhance training stability. The method utilizes Low-Rank Adaptation (LoRA) technology, enabling the TSCD models to be trained as plug-and-play plugins, which can be instantly deployed.
To further improve the performance of the distilled models, the authors incorporate human feedback learning. This technique is designed to enhance generation quality by steering the model towards outputs that align with human aesthetic preferences and objective visual perceptual standards. Aesthetic feedback is derived from models like the LAION aesthetic predictor and ImageReward, which provide reward signals to guide the model towards higher-quality outputs. Additionally, perceptual feedback from instance segmentation models is used to evaluate and improve the structural accuracy of generated images. This dual feedback mechanism allows the model to balance subjective aesthetic appeal with objective structural correctness. 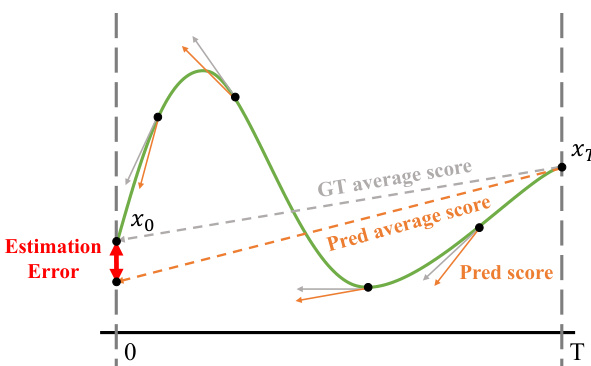
Finally, the framework addresses the challenge of one-step generation, which is inherently limited by consistency loss. The authors integrate score distillation to boost the one-step inference capability of the TSCD models. This involves leveraging a distribution matching distillation (DMD) technique that uses score functions from both the teacher model's real distribution and a fake distribution to refine the model's output. The score distillation process is enhanced with a MSE loss to promote training stability. By combining the TSCD framework with score distillation and human feedback learning, the authors achieve a unified model capable of performing inference from 1 to 8 steps, effectively eliminating the need for model conversion to x0-prediction and enabling the implementation of a one-step LoRA plugin. This integrated approach ensures near-lossless performance during step compression, achieving state-of-the-art results for both SDXL and SD1.5 models.
Experiment
The evaluation setup benchmarks the proposed method against baseline and state-of-the-art diffusion acceleration approaches on the COCO-5k dataset using both SD15 and SDXL architectures, supported by visual comparisons and a comprehensive user study. The primary experiments validate that integrating trajectory segmented consistency distillation with human feedback learning substantially improves generation aesthetics and prompt adherence while reducing inference steps to a single pass. Ablation studies and compatibility tests further demonstrate that the unified lightweight adapter effectively mitigates training difficulties, maintains consistent quality across varying step counts, and seamlessly operates with ControlNet and diverse base models. Collectively, these findings confirm that the framework delivers highly efficient, scalable, and visually superior image synthesis well suited for practical deployment.
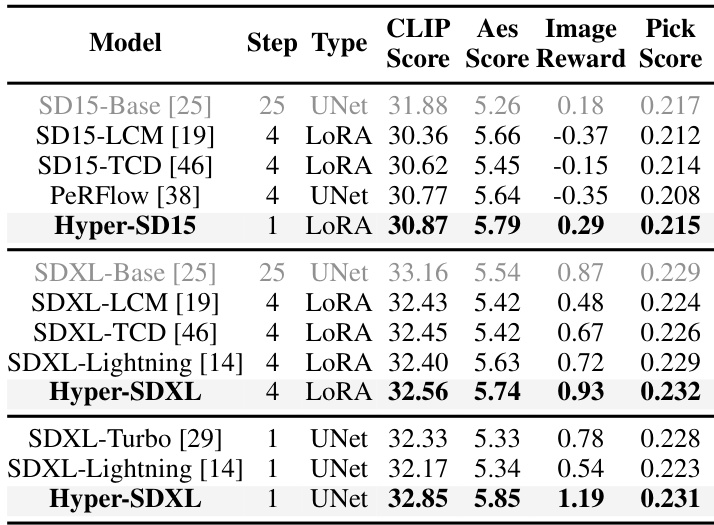
The authors compare their method with baseline approaches using quantitative metrics on the SDXL architecture, evaluating performance with and without human feedback. Results show that their approach achieves higher scores across multiple metrics, particularly in image-text alignment and aesthetics, while maintaining consistency across different inference steps. The method also demonstrates robustness and scalability, with improvements over baseline models in both low- and high-step settings. The proposed method outperforms baseline approaches in image-text alignment and aesthetics, especially when using human feedback. The method maintains consistent performance across different inference steps, with improved scores in both low-step and high-step settings. The approach shows robustness and scalability, with superior results compared to baseline models across various evaluation metrics.
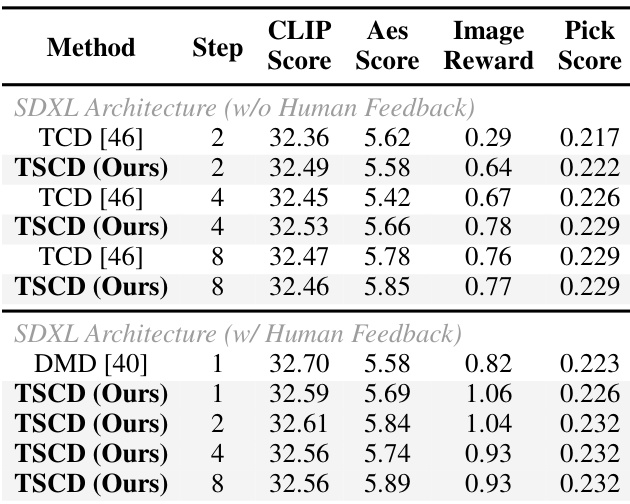
The authors compare their method with existing acceleration approaches using quantitative metrics across different models and inference steps. Results show that their approach achieves higher scores in aesthetics and image-text alignment while requiring fewer steps, demonstrating improved efficiency and quality. The method also maintains consistent performance across different model architectures and inference settings. The proposed method achieves higher aesthetics and image-text alignment scores compared to baseline models with fewer inference steps. The method outperforms other approaches in both SD15 and SDXL architectures, showing consistent improvements across different model types. The unified LoRA approach maintains high-quality results across varying inference steps, indicating robustness and practical applicability.
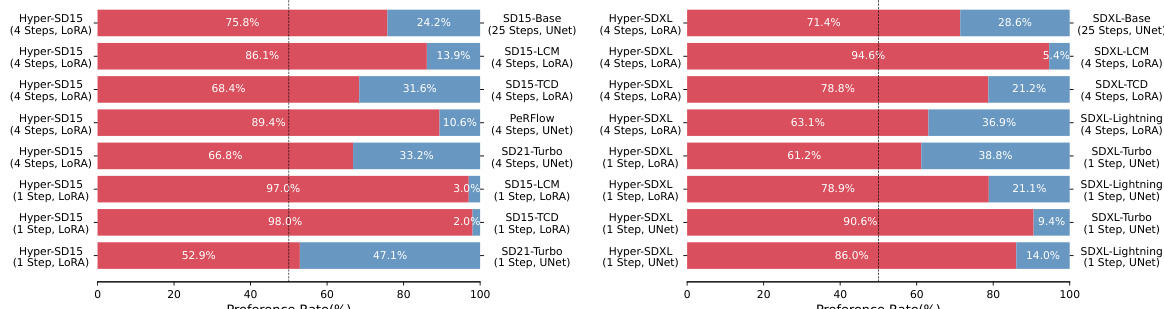
The authors conduct a comprehensive evaluation of their method, Hyper-SD, comparing it against various acceleration approaches on both SD15 and SDXL architectures. Results show that Hyper-SD consistently achieves higher user preference rates across different models and inference steps, particularly excelling in one-step generation. The method demonstrates superior performance compared to baseline and distillation-based approaches, with significant advantages in image quality and alignment with user prompts. Hyper-SD achieves higher user preference rates than competing methods across different models and inference steps. The method significantly outperforms baseline and distillation-based approaches in one-step image generation, particularly on SDXL. Hyper-SD maintains strong performance and image quality across different architectures and user prompts, indicating robustness and scalability.
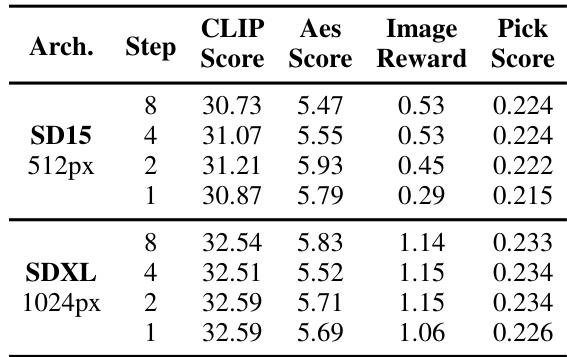
The authors present a comparison of their method with baseline models across different architectures and inference steps, showing improvements in aesthetic and alignment metrics. Results indicate that reducing inference steps leads to performance degradation, but the proposed approach maintains high-quality outputs even at one step, particularly on the SDXL architecture. The method demonstrates consistent performance across various metrics and architectures, with the SDXL model achieving higher scores than SD15 in most cases. The method achieves higher aesthetic and alignment scores on SDXL compared to SD15 across all inference steps. Reducing inference steps leads to a drop in performance, but the proposed approach maintains strong results even at one step. The SDXL architecture consistently outperforms SD15 in terms of both aesthetic and alignment metrics across different inference steps.
{"summary": "The authors compare their method with various acceleration approaches, demonstrating that their proposed TSCD framework significantly improves performance across multiple metrics, particularly in terms of aesthetics and image-text alignment. The results show that incorporating human feedback learning enhances the model's ability to maintain consistency and quality, especially at low inference steps. The unified LoRA approach further demonstrates consistent performance across different steps, indicating its practicality for real-world applications.", "highlights": ["The proposed method outperforms baseline models in aesthetics and image-text matching, especially at one-step inference.", "Human feedback learning effectively compensates for performance degradation during distillation, improving consistency and quality.", "The unified LoRA approach maintains high-quality results across different inference steps, showing scalability and practicality."]
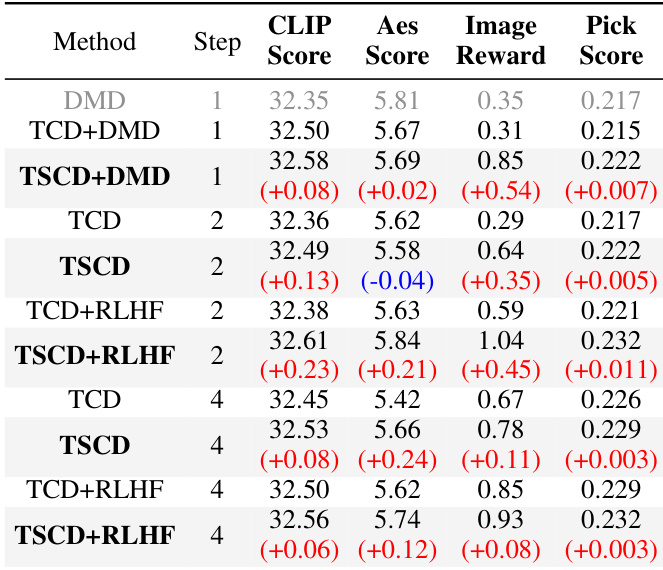
The experiments evaluate the proposed method against baseline and distillation-based approaches across SD15 and SDXL architectures, assessing performance across varying inference steps with and without human feedback. These evaluations validate that the approach successfully accelerates generation while preserving strong image-text alignment and aesthetic quality, particularly in demanding one-step scenarios. Human feedback learning effectively mitigates typical performance degradation during acceleration, and the unified LoRA framework ensures consistent outputs across different models and step counts. Overall, the method demonstrates superior robustness, scalability, and practical applicability compared to existing acceleration techniques.