Command Palette
Search for a command to run...
Whisper AutoCaption を使用して、あらゆる言語から自動で動画字幕を生成
概要
One-sentence Summary
Video Language Planning (VLP) is a tree search algorithm that trains vision-language models as policies and value functions alongside text-to-video models as dynamics to generate long-horizon multimodal video plans, which are translated into real robot actions via goal-conditioned policies to substantially improve task success rates across simulated and real environments spanning multi-object rearrangement, dexterous manipulation, and three hardware platforms.
Key Contributions
- Video Language Planning (VLP) is an algorithm that generates long-horizon video plans by integrating vision-language models and text-to-video foundation models within a tree search procedure.
- The framework trains vision-language models as policies and value functions while employing text-to-video models as dynamics models, enabling the system to simulate and reason over hundreds of future frames rather than generating plans step by step.
- Experiments demonstrate that VLP substantially improves long-horizon task success rates on simulated and real robotics benchmarks across three hardware platforms by translating intermediate video frames into goal-conditioned robot actions.
Introduction
Intelligent physical interaction requires agents to plan over both high-level task objectives and low-level environmental dynamics. While vision-language models excel at generating abstract step-by-step instructions, they struggle to ground reasoning in physical constraints and temporal dynamics. Text-to-video models capture rich object motion and physics from internet footage but currently lack the ability to generate coherent long-horizon sequences or integrate directly into decision-making pipelines. The authors leverage these complementary capabilities by introducing Video Language Planning, a forward tree search algorithm that synergizes both model types. In this framework, the vision-language model proposes candidate actions and evaluates rollout progress, while the video model simulates short-term physical outcomes. This composition enables scalable planning over hundreds of frames, allowing robots to execute complex, long-horizon manipulation tasks with significantly higher success rates than existing baselines.
Dataset
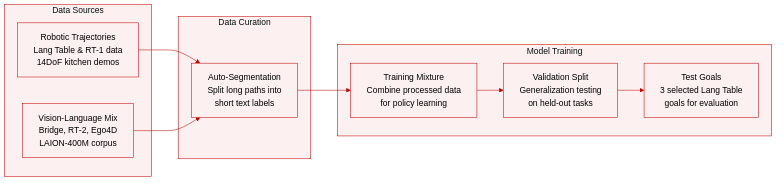
- Dataset Composition and Sources: The authors combine robotic manipulation trajectories with large-scale vision-language corpora. The robotic data includes the Language Table, the RT-1 mobile manipulator dataset, custom teleoped demonstrations, and a curated blend of Bridge, RT-2, Ego4D, EPIC-KITCHEN, and LAION-400M for cross-modal pretraining.
- Subset Details: The Language Table contains roughly 10,000 long-horizon trajectories across hundreds of goals, with three specific goals selected for evaluation to yield approximately 20,000 trajectories. The 14DoF bi-manual subset comprises around 1,200 teleoped kitchen stacking demonstrations. The 7DoF mobile manipulator data is sourced directly from RT-1 and supplemented with additional trajectories for generalization testing. The vision-language mix integrates the six external datasets to support the diffusion model.
- Processing and Metadata Construction: The authors automatically segment long-horizon trajectories and high-level instructions into short-horizon text labels. This metadata generation step produces approximately 400,000 short-horizon labels for the Language Table subset and roughly 25,000 labels for the 14DoF bi-manual dataset. The temporal and instructional segmentation ensures aligned vision-language pairs without requiring explicit spatial cropping.
- Training Usage and Splits: The VLP model learns manipulation policies directly from the robotic trajectory datasets. For the text-to-video diffusion component, the authors blend the 7DoF mobile manipulator data with the broader vision-language corpus. The three selected Language Table goals function as the primary evaluation split, while the remaining trajectories and external datasets form the training mixture to support policy learning and cross-domain generalization.
Method
The Video Language Planning (VLP) framework integrates vision-language models (VLMs) and text-to-video models into a tree-search-based planning system to generate long-horizon video plans for complex tasks. The overall architecture operates in three primary phases: planning, plan execution, and replanning. At its core, VLP leverages multimodal reasoning to synthesize a sequence of intermediate image states and corresponding abstract text actions that progressively achieve a high-level natural language goal.
The planning process begins with a current visual observation x0 and a language goal g. The framework employs a vision-language model as a policy, πVLM(x,g)→a, to generate a set of candidate abstract text actions a conditioned on the current state and the goal. This policy is implemented using PaLM-E, either through a few-shot prompting approach or by fine-tuning on trajectory snippets. Concurrently, a text-to-video model, fVM(x,a), acts as the dynamics model, predicting the resulting video sequence x1:S when a given text action a is executed from the current image x. This video model is trained on short trajectory snippets paired with language labels and is used to synthesize concrete future states.
To guide the search efficiently, a VLM is also used as a heuristic function, HVLM(x,g), which estimates the number of steps remaining to complete the goal from a given state x. This heuristic is trained to predict the remaining steps in a successful trajectory and is used to score and prune the search space. The planning algorithm uses a tree-search procedure, specifically a parallel hill-climbing approach, to explore sequences of actions and states. It initializes multiple plan beams and, at each step, generates a set of candidate actions using the VLM policy. For each action, it synthesizes multiple video rollouts using the text-to-video model. The best-performing video, as determined by the VLM heuristic, is appended to the corresponding plan beam. To maintain diversity and prevent convergence to suboptimal paths, the lowest-value beam is periodically replaced with a copy of the highest-value beam.

The generated long-horizon video plan, x1:H, consists of a sequence of image frames that represent intermediate sub-goals. To execute this plan, a goal-conditioned policy, πcontrol(x,xg), is used to infer low-level control actions u that drive the robot from the current state x to the next synthesized goal state xg. This policy is trained on paired image and control action data, using a short-horizon prediction approach. To handle long-horizon tasks and mitigate error accumulation, VLP employs a receding horizon control strategy, where the video plan is generated in segments and periodically replanned based on the current state.
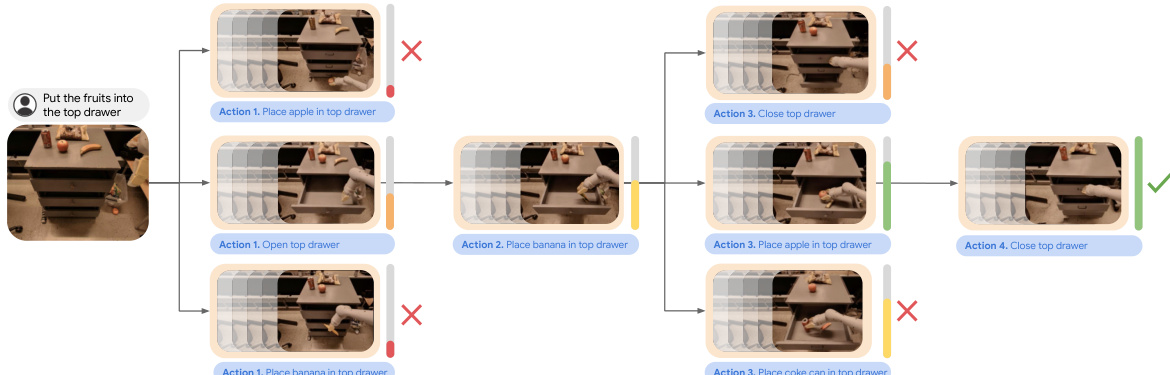
Experiment
The evaluation assesses VLP across simulated and real-world robotic platforms by manually verifying generated video plans against long-horizon language goals and measuring execution success in controlled environments. Experiments demonstrate that hierarchical planning significantly outperforms direct text-to-video synthesis and unpruned policy chaining, with increased search depth consistently improving plan coherence and task success. The framework also exhibits strong generalization capabilities, successfully adapting to novel objects, varying lighting conditions, and unseen tasks by leveraging pre-trained internet knowledge and decomposing execution into focused visual goal generation. While minor limitations such as occasional physics inconsistencies or interpretive errors persist, the overall results confirm that VLP reliably synthesizes and executes complex, multi-step robotic behaviors across diverse scenarios.
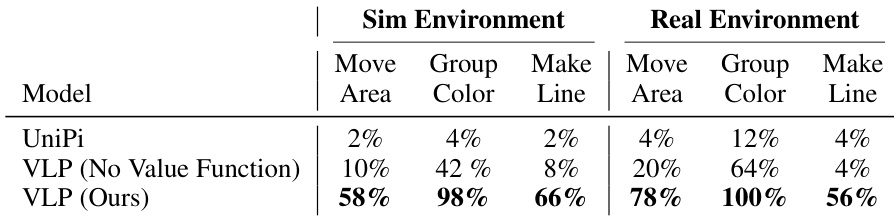
The authors evaluate the performance of their approach, VLP, against baselines in synthesizing long-horizon video plans for tasks in both simulated and real environments. Results show that VLP significantly outperforms the baselines, particularly in the real environment, demonstrating the effectiveness of its planning procedure and value function. VLP also exhibits strong generalization capabilities to new tasks and environments. VLP substantially outperforms baselines in both simulated and real environments for synthesizing long-horizon video plans. The inclusion of a value function in VLP leads to a significant improvement in success rates compared to the baseline without it. VLP demonstrates strong generalization, achieving high success rates in the real environment, particularly on the 'Group Color' task.
The authors evaluate the impact of planning parameters on video synthesis performance, showing that increasing the planning horizon and branching factor improves success rates. Results indicate that higher search complexity leads to better outcomes in generating long-horizon video plans. The approach demonstrates scalability with increased computational resources. Increasing the planning horizon and branching factor improves the success of video plan synthesis. Higher search complexity leads to better performance in generating long-horizon video plans. The method scales positively with increased computational budget for planning.
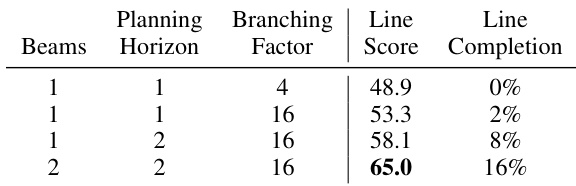
The authors evaluate the impact of search parameters on video synthesis performance, showing that increasing the branching factors in the planning process leads to improved success rates. Results indicate that higher beam and branch values result in substantially better outcomes compared to lower values, demonstrating the importance of extensive search in generating effective long-horizon video plans. Increasing the branching factors in the planning process improves the success rate of video synthesis. Higher beam and branch values lead to substantially better performance compared to lower values. The results highlight the importance of extensive search in generating effective long-horizon video plans.
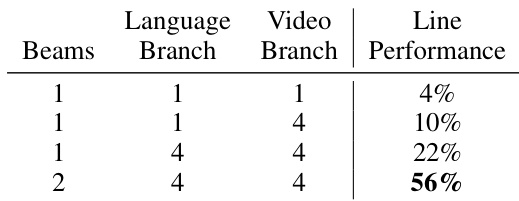
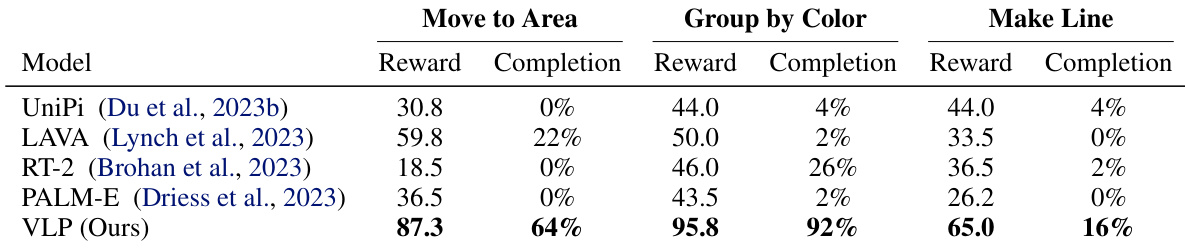
The authors compare their approach, VLP, against several baselines in synthesizing long-horizon video plans for tasks such as moving objects to an area, grouping by color, and making a line. Results show that VLP achieves higher completion rates and rewards across all tasks, demonstrating the effectiveness of its hierarchical planning structure. The performance improvements are particularly notable in tasks requiring precise object arrangement. VLP substantially outperforms baselines that directly synthesize videos or rely solely on a policy without planning. VLP achieves significantly higher completion rates than all baselines across multiple tasks, including moving objects to an area, grouping by color, and making a line. VLP outperforms methods that directly synthesize videos or use only a policy without planning, highlighting the importance of hierarchical planning and a value function. The approach demonstrates robust performance in tasks requiring precise object arrangement, with high completion rates on tasks like grouping by color and making a line.
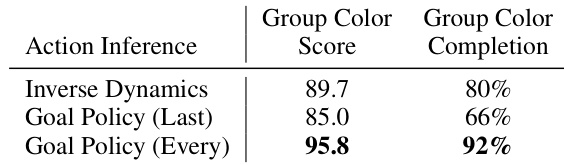
{"summary": "The authors compare different methods for long-horizon video synthesis, focusing on the effectiveness of hierarchical planning. Results show that a method using goal-conditioned policy with full action inference achieves higher success rates in group color tasks compared to inverse dynamics and a last-step policy. The approach demonstrates improved performance in both score and completion metrics when using comprehensive action inference.", "highlights": ["A method using goal-conditioned policy with full action inference outperforms inverse dynamics and a last-step policy in group color tasks.", "The goal-conditioned policy with full action inference achieves higher completion rates compared to other methods.", "The results indicate that comprehensive action inference leads to better performance in both score and completion metrics."]
The authors evaluate the VLP framework against multiple baselines across simulated and real environments to assess its capability in synthesizing long-horizon video plans. Experimental results validate that VLP's hierarchical planning structure and integrated value function substantially outperform direct video synthesis and policy-only approaches, particularly in precise object manipulation tasks while demonstrating strong generalization to novel scenarios. Furthermore, parameter analysis confirms that expanding the planning horizon and branching factors consistently enhances success rates and scales effectively with computational resources. Ultimately, the study concludes that comprehensive action inference paired with extensive search strategies is critical for reliably generating high-quality long-horizon video plans.